发送的第3个请求需要前两个请求的cookie,需要对cookie进行合并
发送的请求数据来自于json数据中的某个键值。
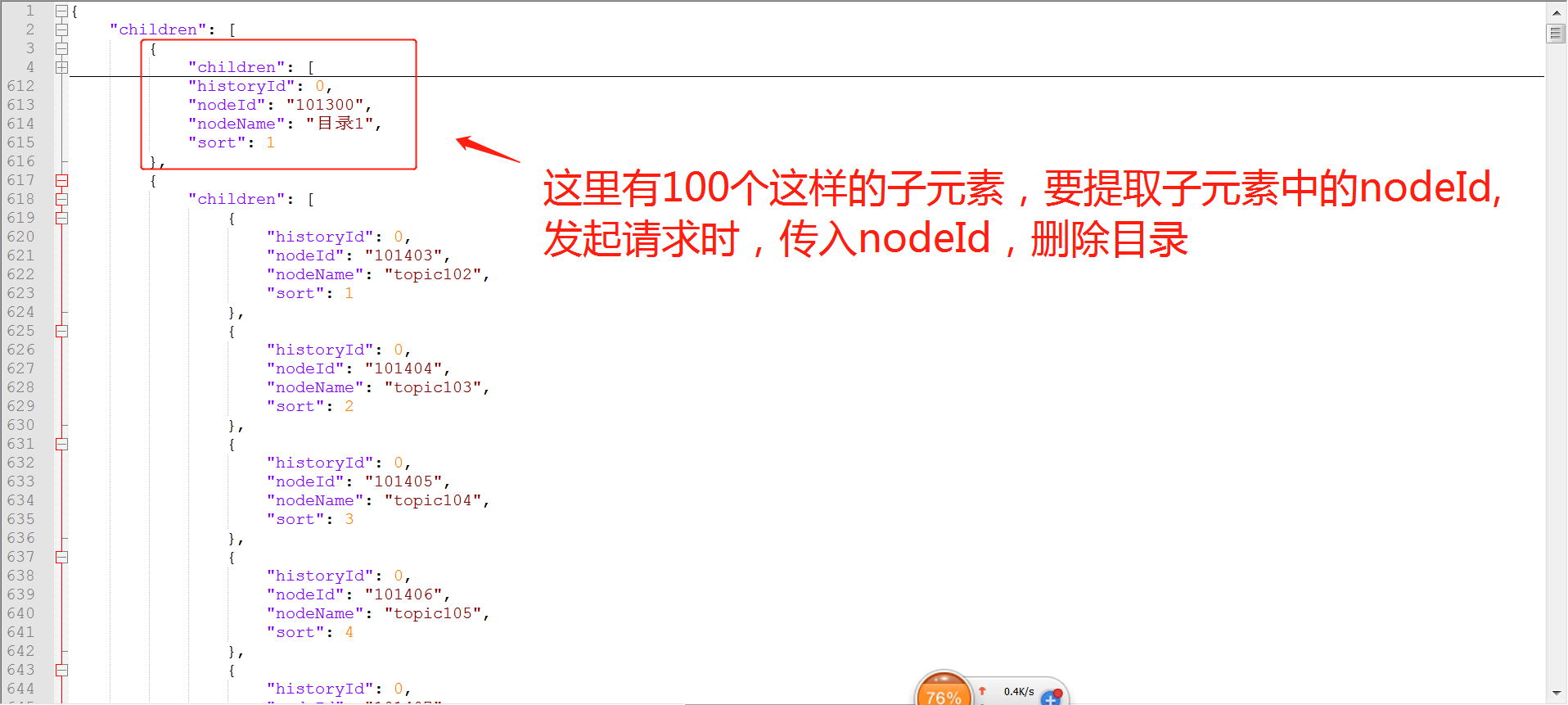
这里是删除所有的对话主题目录,每一个目录有一个id,发起删除对话主题目录的请求时,需要遍历这个目录id, 把目录id作为请求参数传入进去
import requests
import json
Cookie = None
class HttpRequest:
def http_request(self, url, method, data=None, cookie=None):
res = None
try:
if method.upper() == "GET":
res = requests.get(url, data, cookies=cookie)
elif method.upper() == "POST":
res = requests.post(url, data, cookies=cookie)
else:
print("请输入正确参数")
except Exception as e:
print("请求报错了:{}".format(e))
raise e
return res
def get_dir(file, key, sub_key):
# 提取json数据的所有nodeId
# 需要编码,不然可能会报错
with open(file, "r", encoding="utf-8") as f:
json_str = f.read()
data = json.loads(json_str)
dir_list = []
for sub_dic in data[key]:
dir_id = sub_dic[sub_key]
dir_list.append(dir_id)
return dir_list
if __name__ == '__main__':
# 登录
login_url = "http://chat.rainbowred.com/login"
login_data = {"username": "15546355872",
"password": "123456",
"rememberCheck": "1",
"loginStatus": "1",
"rememberStatus": "1",
"autoLogin": "0",
"language": "zh"}
login_res = HttpRequest().http_request(login_url, "post", login_data)
print(login_res.json())
Cookie = login_res.cookies
print("登录后的cookie", Cookie)
# 选择公司
c_url = "http://chat.rainbowred.com/chc"
c_data = {"companyId": "1364"}
c_res = HttpRequest().http_request(c_url, "post", c_data, cookie=Cookie)
print(c_res.json())
print("选择公司后的cookie", c_res.cookies)
# 合并两次接口请求的cookie
Cookie = dict(Cookie, **c_res.cookies)
print("选择公司后的cookie2", Cookie)
file = r"C:\Users\acer-pc\Desktop\8_.json"
key = "children"
sub_key = "nodeId"
d_url = "http://tprofile.rainbowred.com/ctm/delete"
d_data = get_dir(file, key, sub_key)
send_data = {}
# 提取json数据
for data in d_data:
print(data)
send_data["nodeId"] = data
d_res = HttpRequest().http_request(d_url, "post", send_data, Cookie)
print(d_res.json())
如何获取json列表:
首先更新对话主题
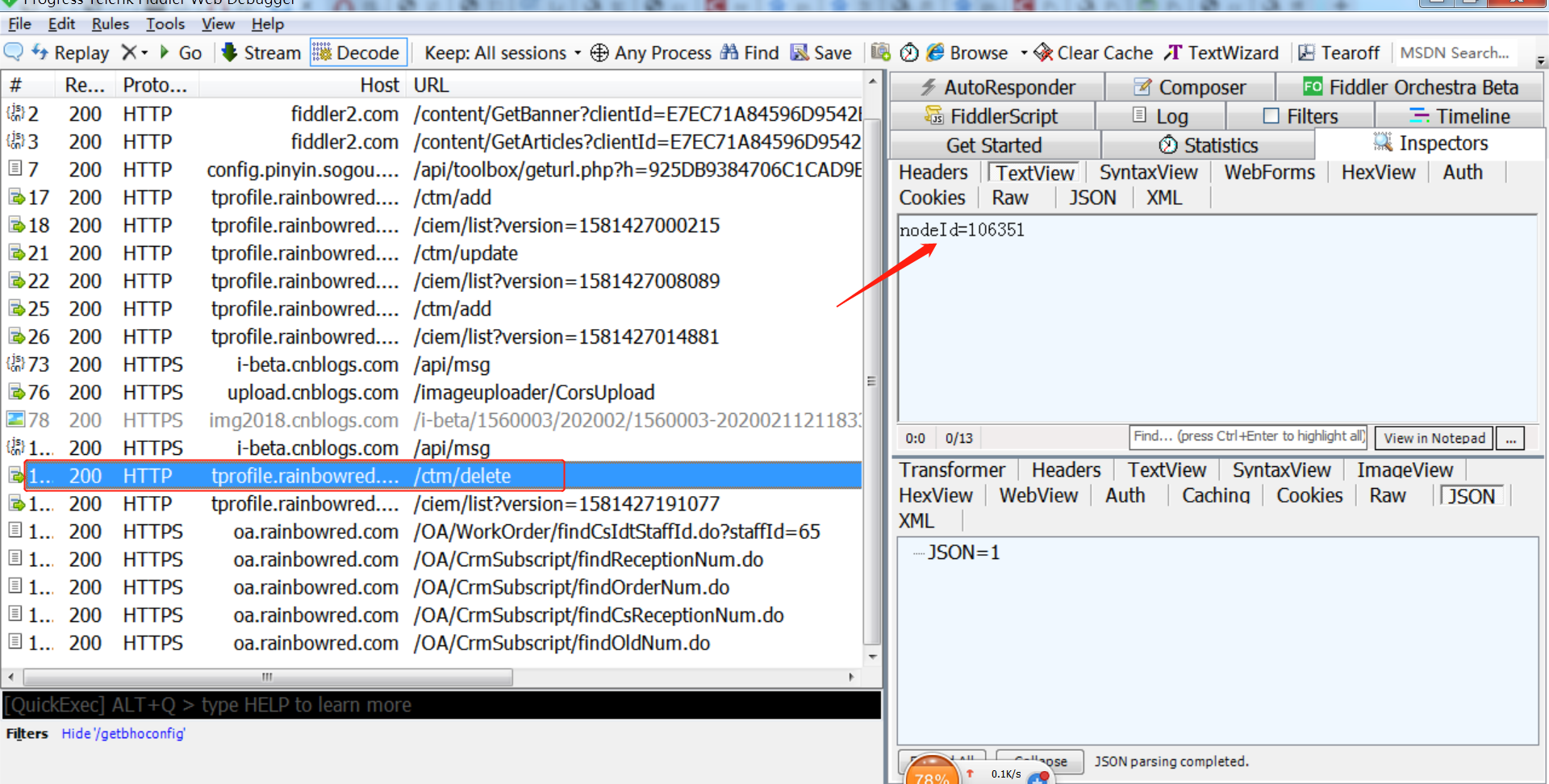
抓取删除接口的请求参数:可以看到需要nodeId
扫描二维码关注公众号,回复:
9090382 查看本文章

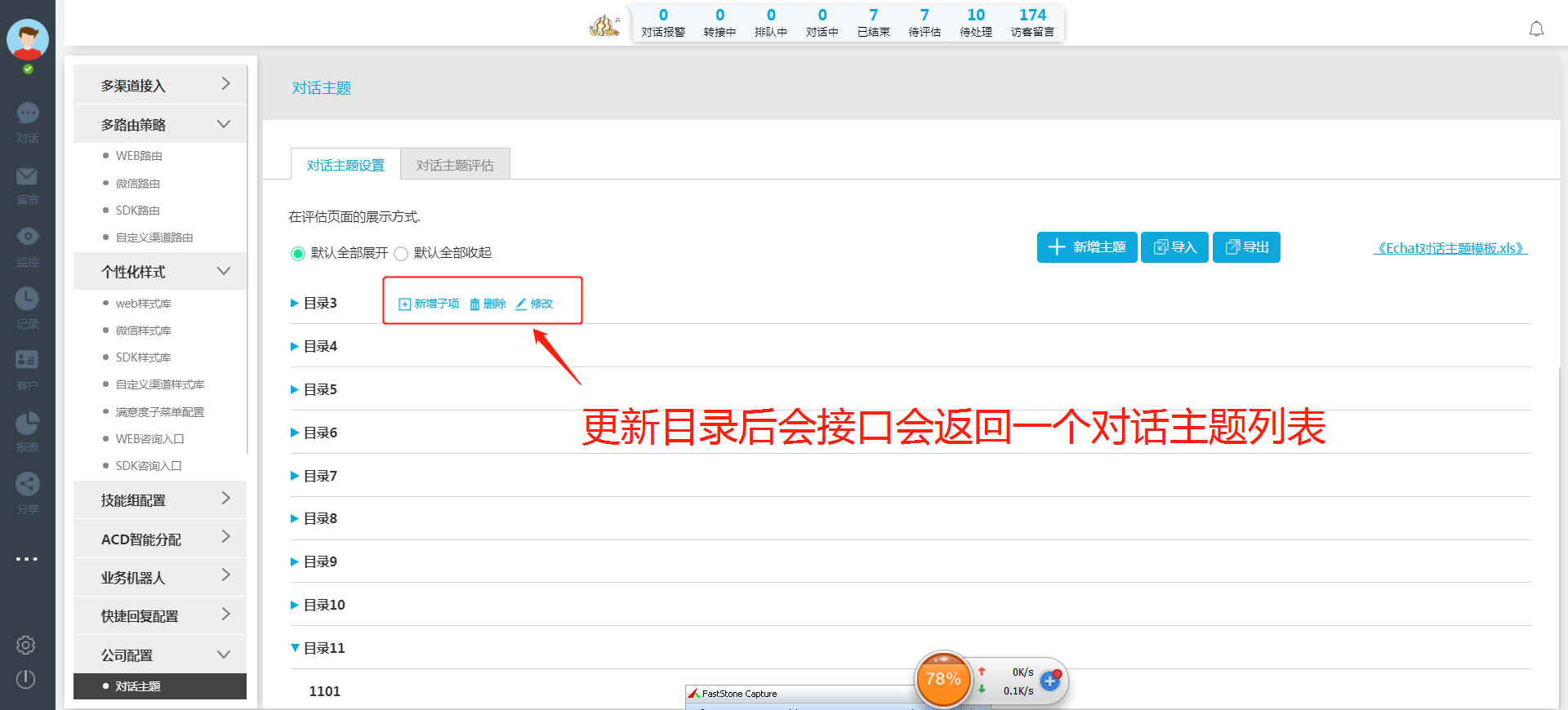
更新对话主题后会更新对话主题版本,请求所有的对话主题列表
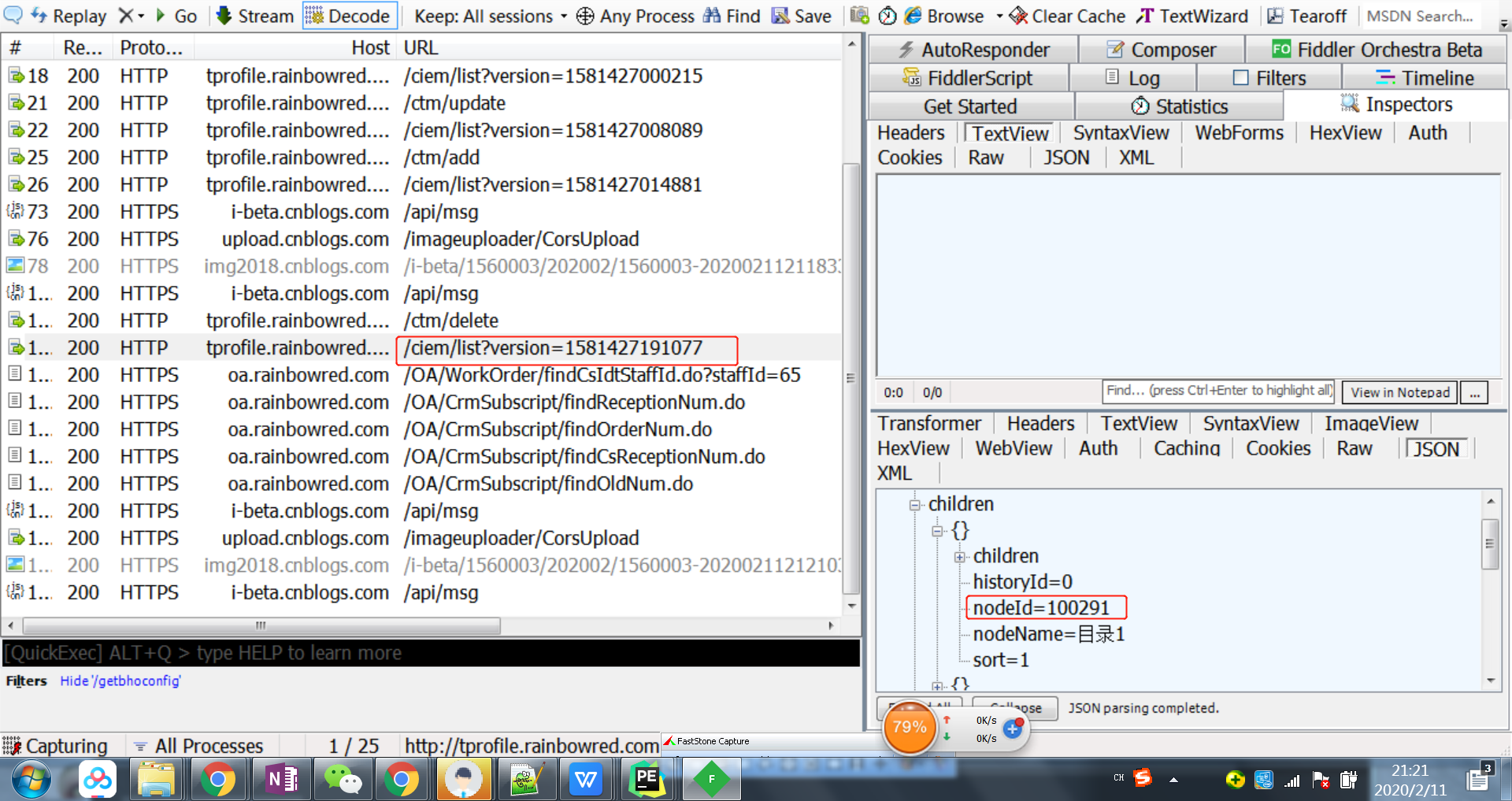
选中接口请求,右键可以保存响应body到本地,便于分析数据结构,看看应该如何获取所有的nodeId
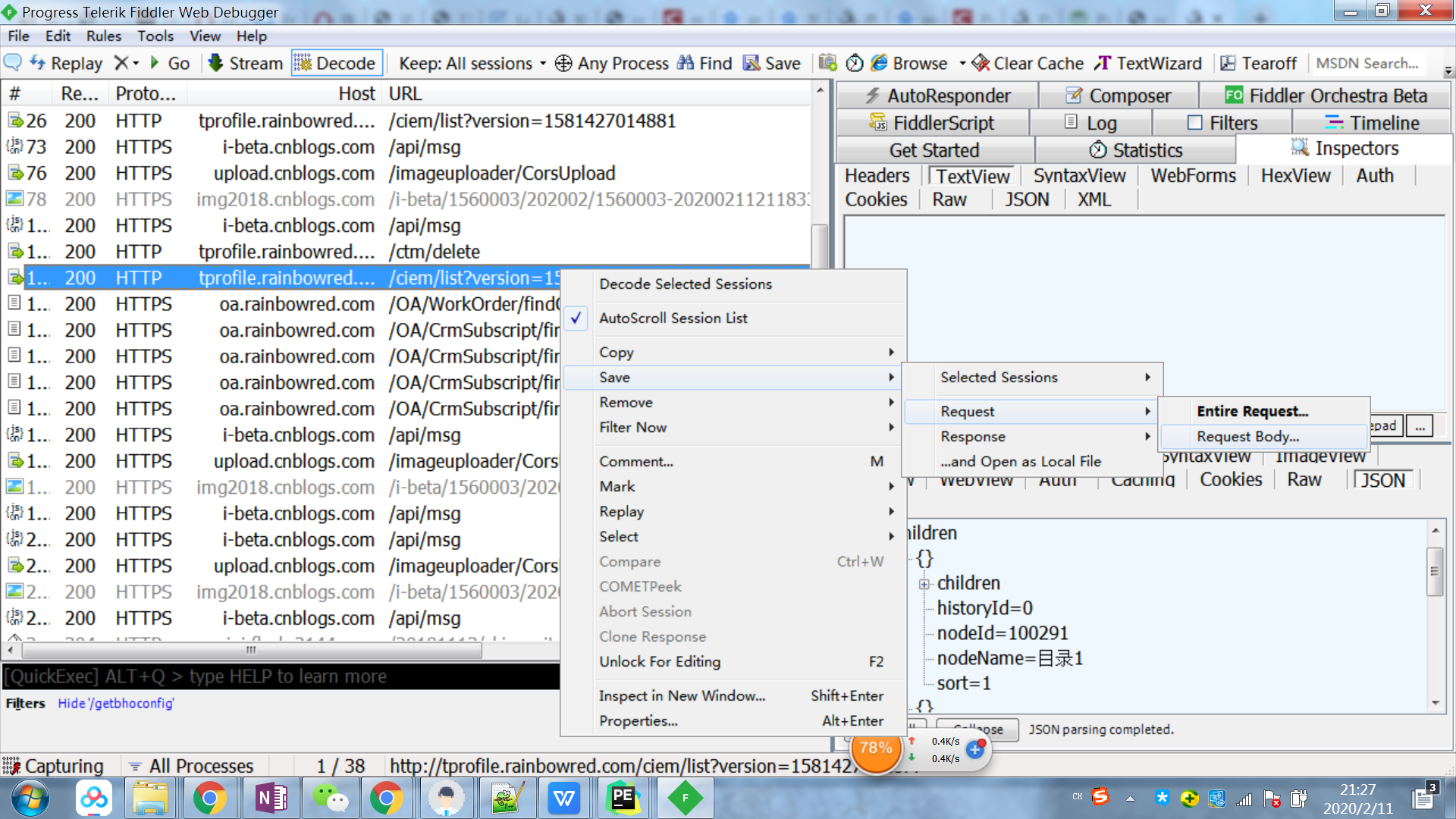
json数据如图