正则表达式
读取文件
加拿大诗歌:THE MAN FROM SNOWY RIVER
http://members.iinet.net.au/~newtoy/snowyriver.htm
import re
with open('D:\\python\\txt\\the_man_from_snowy_river') as txt:
contents = txt.read()
# print(contents)
匹配
精准匹配
# 发现所有的' to '
result = re.findall(' to ',contents)
# 输出的全是包含' to '的一个列表
print(result)
print(len(result))
模糊匹配
.代表一个字符
# 发现所有的'a..'
result = re.findall('a..',contents)
# 输出的全是包含'a..'的一个列表
print(result)
print(len(result))

[a-z]代表字符只能是a~z中的一个
# 发现所有以'a'开头的长度为3的单词,' a[a-z][a-z] '前后各有空格
result = re.findall(' a[a-z][a-z] ',contents)
print(result)
print(len(result))

# 去除列表中单词左右的空格
result = re.findall(' (a[a-z][a-z]) ',contents)
print(result)
print(len(result))
# 利用集合去除重复元素
result_set = set(result)
print(result_set)
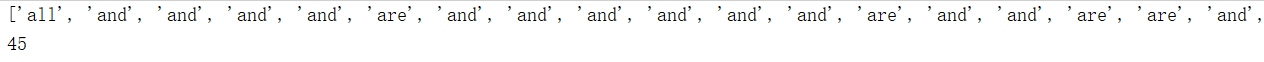
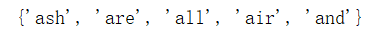
通配符
# 找出以A或a开头的单词,针对'And'开头,处理单词前面的空格
# a* 代表有0个或多个字符a
result = re.findall(' *([Aa][a-z][a-z]) ',contents)
print(result)
print(len(result))
result_set = set(result)
print(result_set)

re.sub
re.sub(pattern, repl, string, count=0, flags=0)
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个**函数**。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配
import re
string = '1829-1231-123 #注释'
num = re.sub('#.*$','',string)
print(string) # string的值并没有改变
print(num)
num1 = re.sub('\D','',num)
print(num1)
运行结果
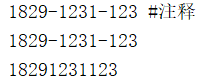
repl可以是一个函数
import re
# 将匹配的数字乘以 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
输出结果如下,其中位数567被转换成1134
A46G8HFD1134
re.compile
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。语法格式为:
re.compile(pattern[, flags])
pattern : 一个字符串形式的正则表达式
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 # 后面的注释
re.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
扫描二维码关注公众号,回复:
9091864 查看本文章

findall(string[, pos[, endpos]])
findall(pattern, string)
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
import re
# 查找所有的数字
pattern = re.compile(r'\d+')
txt = 'ssfj121 jfajfk12343'
print(pattern.findall(txt))
print(pattern.findall(txt,0,15))
'''输出结果为
['121', '12343']
['121', '1']
'''
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
import re
string = '23shfj12da212'
it = re.finditer(r'\d+',string)
for match in it:
print(match.group())
'''输出为
23
12
212
'''
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表
re.split(pattern, string[, maxsplit=0, flags=0])
maxsplit 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
split()括号内可以没有参数,代表按照空,空格,换行符,制表符来分割。
分割出来的都是字符串,形成一个列表
import re
print(re.split('\W+', 'runoob, runoob, runoob.'))
# 在分割得到的列表中,会包含满足条件的\W+本身
print(re.split('(\W+)', ' runoob, runoob, runoob.'))
print(re.split('\W+', ' runoob, runoob, runoob.', 1))
print(re.split('a*', 'hello world'))
print(re.split('aa*', 'hello world'))

运行结果
['runoob', 'runoob', 'runoob', '']
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
['', 'runoob, runoob, runoob.']
['', 'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '']
['hello world']
import re
ip = "202.156.64.82"
print(ip.split(".", 4))
re.RegexObject
re.compile() 返回 RegexObject 对象
re.MatchObject
参考资源
- Python - Regular Expressions
https://www.tutorialspoint.com/python/python_reg_expressions.htm - 菜鸟教程-Python 正则表达式
https://www.runoob.com/python/python-reg-expressions.html - B站视频-详解Python正则表达式
https://www.bilibili.com/video/av7036891?from=search&seid=16720185157603375715 - python split()
https://blog.csdn.net/qq_18543521/article/details/83861430
