Table API是流处理和批处理通用的关系型API,Table API可以基于流输入或者批输入来运行而不需要进行任何修改。Table API是SQL语言的超集并专门为Apache Flink设计的,Table API是Scala 和Java语言集成式的API。与常规SQL语言中将查询指定为字符串不同,Table API查询是以Java或Scala中的语言嵌入样式来定义的,具有IDE支持如:自动完成和语法检测。
一、需要引入的pom依赖
注意版本号:https://mvnrepository.com/
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.12</artifactId>
<version>1.7.2</version>
<scope>provided</scope>
</dependency>
二、Table API与SQL程序结构(摘自官网)
用于批处理和流式传输的所有Table API和SQL程序都遵循相同的模式。以下代码示例显示了Table API和SQL程序的通用结构。
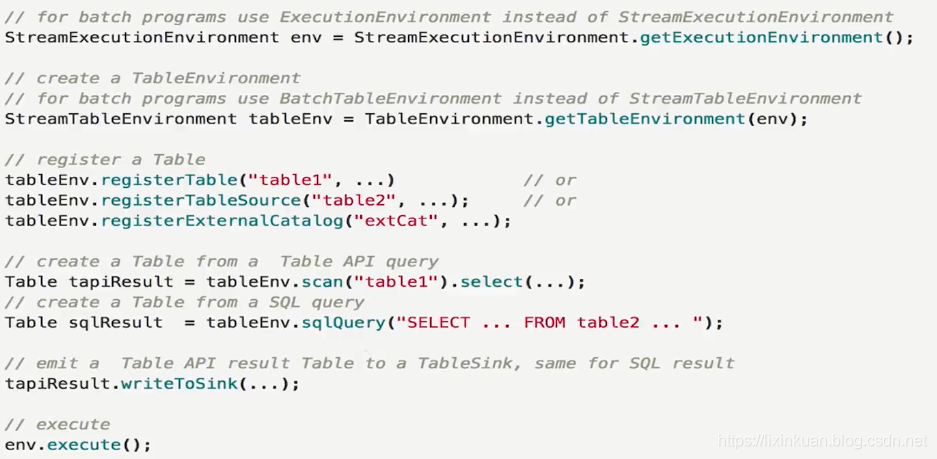
注意:表API和SQL查询可以轻松地与DataStream或DataSet程序集成并嵌入其中。请参阅与DataStream和DataSet API集成,以了解如何将DataStream和DataSet转换为Tables,反之亦然(上面截图是1.72版本,下面截图是1.9版本)。

三、Demo示例(一)演示fliter函数
package com.lxk.service
import com.alibaba.fastjson.JSON
import com.lxk.bean.UserLog
import com.lxk.util.FlinkKafkaUtil
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer010, FlinkKafkaProducer010}
import org.apache.flink.table.api.{StreamTableEnvironment, Table, TableEnvironment, scala}
object StartupTableApp {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val myKafkaConsumer: FlinkKafkaConsumer010[String] = FlinkKafkaUtil.getConsumer("GMALL_STARTUP")
val dstream: DataStream[String] = env.addSource(myKafkaConsumer)
val tableEnv = TableEnvironment.getTableEnvironment(env)
val startupLogDstream: DataStream[UserLog] = dstream.map { JSON.parseObject(_, classOf[UserLog]) }
val startupLogTable: Table = tableEnv.fromDataStream(startupLogDstream)
tableEnv.registerTable("userlog",startupLogTable)
val table: Table = tableEnv.scan("userlog").select("*").filter("channel==='appstore'")
// 将table转换为DataStream----将一个表附加到流上Append Mode
val appendStream: DataStream[UserLog] = tableEnv.toAppendStream[UserLog](table)
// 将表转换为流Retract Mode true代表添加消息,false代表撤销消息
//val retractStream: DataStream[(Boolean, UserLog)] = tableEnv.toRetractStream[UserLog](table)
appendStream.print()
env.execute()
}
}output:
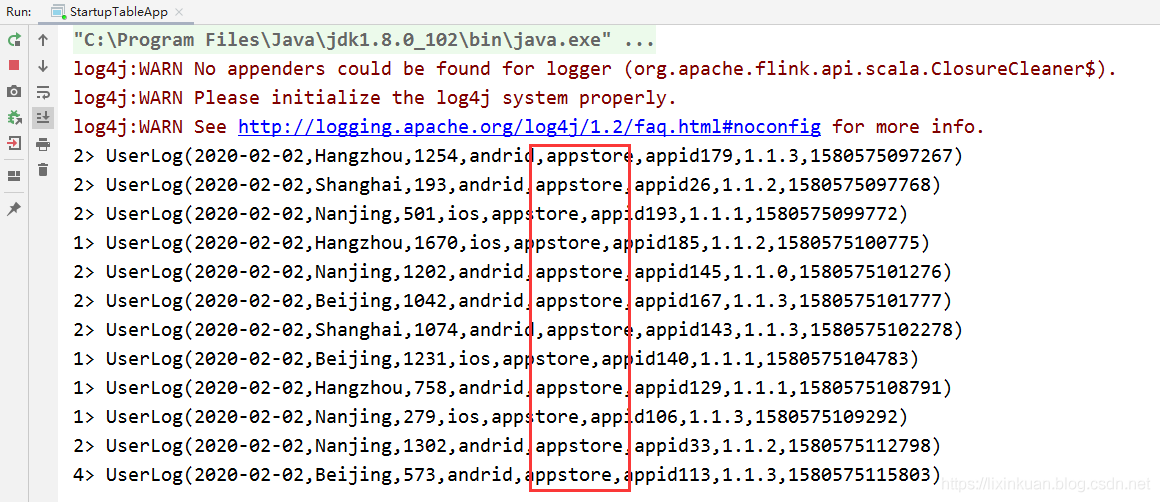
动态表
如果流中的数据类型是case class可以直接根据case class的结构生成table
val tableEnv = TableEnvironment.getTableEnvironment(env) val startupLogDstream: DataStream[UserLog] = dstream.map { JSON.parseObject(_, classOf[UserLog]) } val startupLogTable: Table = tableEnv.fromDataStream(startupLogDstream)
或者根据字段顺序单独命名(这种方式还没有调通)
val startupLogTable: Table = tableEnv .fromDataStream(dstream,'dateToday, 'area, 'uid, 'os, 'channel, 'appid, 'ver, 'timestamp.rowtime()) 字段:用一个单引放到字段前面 来标识字段名, 如 dateToday, 'area, 'uid, 'os 等
最后的动态表可以转换为流进行输出
table.toAppendStream[(String,String)]
四、Demo示例(二)演示group by函数
package com.lxk.service
import com.alibaba.fastjson.JSON
import com.lxk.bean.UserLog
import com.lxk.service.StartupTableApp.userLogTamp
import com.lxk.util.FlinkKafkaUtil
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010
import org.apache.flink.table.api.{StreamTableEnvironment, Table, TableEnvironment, scala}
object StartupTableApp01 {
case class userLogSumTamp( channel:String, sum:Integer)
def main(args: Array[String]): Unit = {
//sparkcontext
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//时间特性改为eventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val myKafkaConsumer: FlinkKafkaConsumer010[String] = FlinkKafkaUtil.getConsumer("GMALL_STARTUP")
val dstream: DataStream[String] = env.addSource(myKafkaConsumer)
val startupLogDstream: DataStream[UserLog] = dstream.map { JSON.parseObject(_, classOf[UserLog]) }
//告知watermark 和 eventTime如何提取
val startupLogWithEventTimeDStream: DataStream[UserLog] = startupLogDstream
.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[UserLog](Time.seconds(0L)) {
override def extractTimestamp(element: UserLog): Long = {
element.timestamp
}
}).setParallelism(1)
//SparkSession
val tableEnv = TableEnvironment.getTableEnvironment(env)
val startupLogTable: Table = tableEnv.fromDataStream(startupLogWithEventTimeDStream)
tableEnv.registerTable("userlog",startupLogTable)
val table: Table = tableEnv.scan("userlog").groupBy("channel").select("channel, sum(1) as sum")
// 将table转换为DataStream----将一个表附加到流上Append Mode
//val appendStream: DataStream[userLogSumTamp] = tableEnv.toAppendStream[userLogSumTamp](table)
//appendStream.print()
// 将表转换为流Retract Mode true代表添加消息,false代表撤销消息
val retractStream: DataStream[(Boolean, userLogSumTamp)] = tableEnv.toRetractStream[userLogSumTamp](table)
retractStream.print()
env.execute()
}
}output:
模式生产环境,每500ms生产一条数据,共生产30条用户日志,
主函数输出结果如下,
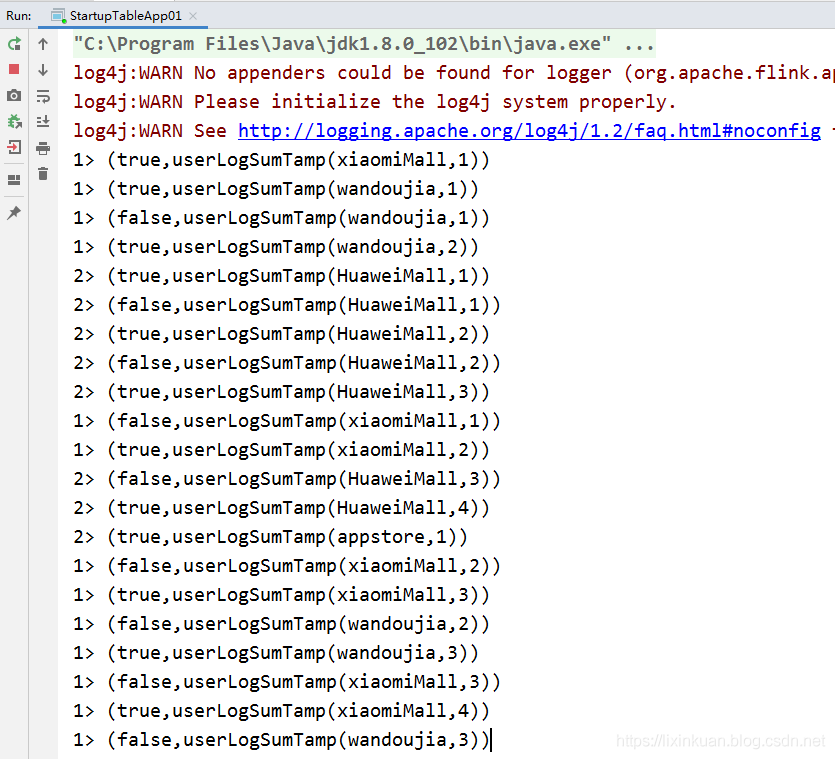
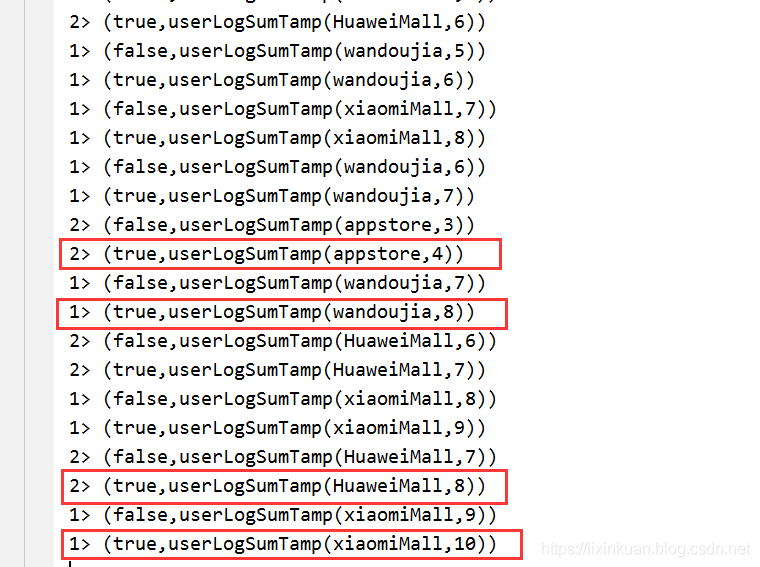
通过分组函数,最后统计的各个渠道总共是4+8+8+10=30个,符合预期。
