因为疫情单位无限期放假,只能宅在家里看娃,可每天娃都有作业要写,闲的发慌的我想着自己喜欢看电影,写个爬虫为以后找点电影省点事。
边学边写,花了几天时间,总算实现了两个主要功能:搜索影片和显示最新影片
其他功能后续再完善。
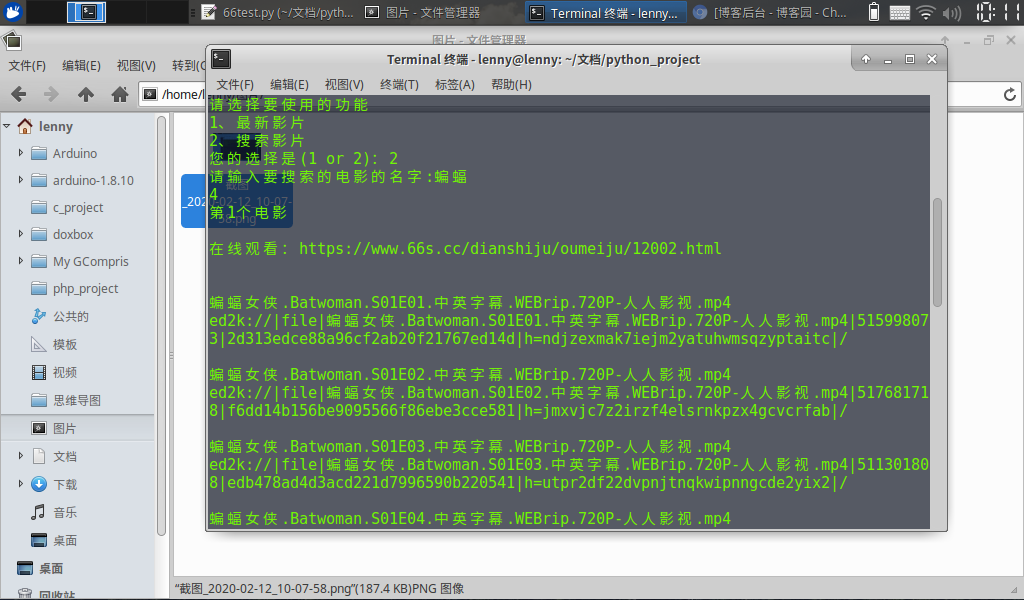
在开发搜索功能时,遇见了整个过程中最大的坑。
在抓包时,我发现网站用post提交搜索数据,并进行了跳转。
Request URL: https://www.66e.cc/e/search/index.php Request Method: POST Status Code: 302 Moved Temporarily Remote Address: 23.225.141.94:443 Referrer Policy: no-referrer-when-downgrade
以下是搜索影片时提交的数据,而关键字keyboard显示无法解码的值。
show: title,smalltext tempid: 1 tbname: Article keyboard: (unable to decode value) submit:
后来再用程序测试的时候始终获取不到跳转后的url,经过各种查询和测试我才明白需要给搜索的关键字转码,网站用的的gbk编码。
在程序里需要转换一下关键字的编码
keyboard = u'蝙蝠侠' keyboard =keyboard.encode('gb2312')
然后就是一马平川了,抓取网页,提取电影详情页链接。


1 #获取第一个搜索页面 2 def getSearchPage(keyWord,searchUrl): 3 #构建post数据 4 postDict = { 5 "keyboard": keyWord, 6 "show": "title,smalltext", 7 "submit": "", 8 "tbname": "Article", 9 "tempid": "1" 10 } 11 postData = urllib.parse.urlencode(postDict) 12 #提取电影id 13 response = requests.post(searchUrl, data=postDict, headers=header,allow_redirects=True) 14 url = response.url 15 searchid = url.replace("https://www.66e.cc/e/search/result/?","") 16 #是否搜索到电影 17 html = response.text 18 soup = BeautifulSoup(html, "lxml") 19 results = soup.select("html > body > table.tableborder > tr > td > div > b") 20 if len(results) == 1: 21 print("没有搜索到相关的内容") 22 exit() 23 24 hrefs = getSearchLinks(soup,searchid) 25 return hrefs
在进入电影详情页后,就省最后一步提取下载链接了,66影视提供了多种在线和下载电影方式,用正则就可以搞定。
值得一提的是,在提取下载链接后,还需要进行url转码,特别是磁力链接,进行url转码后还要对其中的html转义字符进行处理。
url转码:urllib.parse.unquote("下载链接")
转义处理:html.unescape("下载链接")
#新式页面链接 def new_pages(results): links = [] dr = re.compile(r'<[^>]+>',re.S) for result in results: if 'magnet' in str(result): dmlink = re.findall(r'magnet:?[^\"]+',str(result),re.I) dmtext = dr.sub('',str(result)) links.append(dmtext + html.unescape(urllib.parse.unquote(dmlink [0]))) continue if 'ed2k' in str(result): delink = re.findall(r'ed2k://.*\|/',str(result),re.I) detext = dr.sub('',str(result)) links.append(detext + urllib.parse.unquote(delink[0])) continue if 'thunder' in str(result): dtlink = re.findall(r'(thunder[^"]+)[^>]+[>]{1}',str(result),re.I) dttext = dr.sub('',str(result)) links.append(dttext + dtlink[0]) continue text = dr.sub('',str(result)) links.append(text) return links
补充一句,66影视的早期页面和现在页面在布局上是有差异的,所以我用了两个不同的函数来处理,以确保早期页面的下载链接也能获取到。
完整代码如下
1 import requests 2 import urllib 3 import re 4 import html 5 import time 6 from bs4 import BeautifulSoup 7 8 header = { 9 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 10 'Accept-Encoding': 'gzip, deflate, br', 11 'Accept-Language': 'zh-CN,zh;q=0.9', 12 'Cache-Control': 'max-age=0', 13 'Connection': 'keep-alive', 14 'Content-Length': '94', 15 'Content-Type': 'application/x-www-form-urlencoded', 16 'Cookie': 'ecmslastsearchtime=1580821558; ecmsecookieinforecord=%2C72-40622%2C72-40593%2C75-40632%2C68-40585%2C37-40634%2C', 17 'Host': 'www.66e.cc', 18 'Origin': 'https://www.66e.cc', 19 'Referer': 'https://www.66e.cc/', 20 'Upgrade-Insecure-Requests': '1', 21 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400' 22 23 } 24 25 searchUrl = "https://www.66e.cc/e/search/index.php" 26 indexUrl = "https://www.66e.cc/" 27 28 content = u'蝙蝠侠' 29 content = content.encode('gb2312') 30 31 #首页布局 32 index_rules = "html > body > div.wrap > div.tnlist > ul > li" 33 #详情页不同的布局 34 detail_rules = {'new' : "html > body > div.wrap > div.mainleft > div.contentinfo > div#text > table > tbody > tr", 35 'old' : "html > body > div.wrap > div.mainleft > div.contentinfo > div#text > p.t_msgfont > a > strong"} 36 37 #新式页面链接 38 def new_pages(results): 39 links = [] 40 dr = re.compile(r'<[^>]+>',re.S) 41 for result in results: 42 if 'magnet' in str(result): 43 dmlink = re.findall(r'magnet:?[^\"]+',str(result),re.I) 44 dmtext = dr.sub('',str(result)) 45 links.append(dmtext + html.unescape(urllib.parse.unquote(dmlink [0]))) 46 continue 47 if 'ed2k' in str(result): 48 delink = re.findall(r'ed2k://.*\|/',str(result),re.I) 49 detext = dr.sub('',str(result)) 50 links.append(detext + urllib.parse.unquote(delink[0])) 51 continue 52 if 'thunder' in str(result): 53 dtlink = re.findall(r'(thunder[^"]+)[^>]+[>]{1}',str(result),re.I) 54 dttext = dr.sub('',str(result)) 55 links.append(dttext + dtlink[0]) 56 continue 57 text = dr.sub('',str(result)) 58 links.append(text) 59 return links 60 61 #旧式页面链接 62 def old_pages(results): 63 links = [] 64 dr = re.compile(r'<[^>]+>',re.S) 65 for result in results: 66 text = dr.sub('',str(result)) 67 links.append(text) 68 return links 69 70 #获取所有下载链接 71 def getDetailLinks(url): 72 results = [] 73 links = [] 74 respones = requests.get(url); 75 respones.encoding = 'gbk' 76 htmltext = respones.text 77 soup = BeautifulSoup(htmltext, "lxml") 78 results = soup.select(detail_rules["new"]) 79 80 if results != []: 81 links = new_pages(results) 82 return links 83 else: 84 results = soup.select(detail_rules["old"]) 85 if results != []: 86 links = old_pages(results) 87 return links 88 else: 89 #print("该页面没有下载链接!") 90 return [] 91 92 #获取电影详情页 93 def getSearchLinks(soup,searchid): 94 filmResults = [] 95 urls = [] 96 hrefs = [] 97 results = [] 98 #计算pageid 99 filmcounts = soup.select("html > body > div > div.wrap > div.mainleft > div.channellist > div.listBox > div.pagebox > a > b") 100 filmCount = int(filmcounts[0].text) 101 if filmCount % 20 == 0: 102 filmCount = filmCount // 20 103 print(filmCount) 104 else: 105 filmCount = filmCount // 20 + 1 106 print(filmCount) 107 108 #通过pageid构建分页url 109 pageid = 0 110 while pageid < filmCount: 111 #print(pageid) 112 urls.append("https://www.66e.cc/e/search/result/index.php?page="+str(pageid)+"&"+str(searchid)) 113 pageid = pageid + 1 114 #获取每一个电影元素 115 for url in urls: 116 response = requests.get(url) 117 html = response.text 118 soup = BeautifulSoup(html, "lxml") 119 filmResult = soup.select("html > body > div > div.wrap > div.mainleft > div.channellist > div.listBox > ul > li > div.listInfo > h3 > a") 120 for fr in filmResult: 121 results.append(fr) 122 123 #提取电影详情页链接 124 for href in results: 125 temp = re.findall(r"https.*html?",str(href),re.I) 126 hrefs.append(temp[0]) 127 128 return hrefs 129 130 131 132 #获取第一个搜索页面 133 def getSearchPage(keyWord,searchUrl): 134 #构建post数据 135 postDict = { 136 "keyboard": keyWord, 137 "show": "title,smalltext", 138 "submit": "", 139 "tbname": "Article", 140 "tempid": "1" 141 } 142 postData = urllib.parse.urlencode(postDict) 143 #提取电影id 144 response = requests.post(searchUrl, data=postDict, headers=header,allow_redirects=True) 145 url = response.url 146 searchid = url.replace("https://www.66e.cc/e/search/result/?","") 147 #是否搜索到电影 148 html = response.text 149 soup = BeautifulSoup(html, "lxml") 150 results = soup.select("html > body > table.tableborder > tr > td > div > b") 151 if len(results) == 1: 152 print("没有搜索到相关的内容") 153 exit() 154 155 hrefs = getSearchLinks(soup,searchid) 156 return hrefs 157 158 #搜索影片 159 def searchFilms(keyWord,searchUrl): 160 hrefs = getSearchPage(keyWord,searchUrl) 161 count = 1 162 for href in hrefs: 163 links = getDetailLinks(href) 164 print("第"+ str(count) +"个电影") 165 for link in links: 166 print(link) 167 count = count + 1 168 time.sleep(3) 169 170 #最新影片 171 def latestFilms(): 172 hrefs = [] 173 response = requests.get(indexUrl) 174 htmltext = response.text 175 soup = BeautifulSoup(htmltext, "lxml") 176 results = soup.select(index_rules) 177 178 for href in results: 179 temp = re.findall(r"https.*html?",str(href),re.I) 180 hrefs.append(temp[0]) 181 182 for href in hrefs: 183 links = getDetailLinks(href) 184 for link in links: 185 print(link) 186 187 def menu(): 188 print("请选择要使用的功能") 189 print("1、最新影片") 190 print("2、搜索影片") 191 num = input("您的选择是(1 or 2):") 192 return num 193 194 def getSearchKeyword(): 195 keyWord = input("请输入要搜索的电影的名字:") 196 keyWord = keyWord.encode('gb2312') 197 return keyWord 198 199 if __name__ == '__main__': 200 201 while 1: 202 num = menu() 203 if num == "1": 204 latestFilms() 205 continue 206 if num == "2": 207 keyWord = getSearchKeyword() 208 searchFilms(keyWord,searchUrl) 209 continue 210 else: 211 continue 212