基于JS的正则表达式学习
利用正则表达式图形化工具来辅助学习
在JS中用“//”来声明正则表达式
JS正则表达式学习环境:

一.正则表达式对象
字面量,构造函数实例化正则表达式对象
1.字面量
2.构造函数

加上global属性可以实现全局匹配
例如:

二.元字符
正则表达式由两种基本字符类型组成:
1.原义文本字符
字符本身表示的意思没有多余的含义。
2.元字符
有特殊含义的非字母字符
比较常见的有:* + ? $ ^ . | \ () {} []
\b为单词边界
\B不为单词边界
\t水平制表符
\v垂直制表符
\n换行符
\r回车符
\0空字符
\f换页符
\cX与X对应的控制字符(Ctrl + X)
利用正则表达式图形化可以更加明白每个字符的含义,例如:

三.字符类
一般情况下正则表达式一个字符对应字符串一个字符
例如:

使用元字符[ ]构建简单的类来匹配某一共同特性的对象.例如:


字符类取反
使用^创建反向类/负向类
例如:表达式[^bc]表示不是字符b或c
 效果图
效果图

四.范围类
使用[a-z]表示a到z的任意字符
使用[A-Z]表示A到Z的任意字符
使用[0-9]表示0到9的任意数字



四.JS预定义类及边界
预定义类:
. 除了回车换行的任意字符 等价于[^\r\n]
\d 数字字符 等价于[0-9]
\D 非数字字符 等价于[^0-9]
\w 单词字符(字母,数字下划线) 等价于[a-zA-Z0-9_]
\W 非单词字符 等价于[^a-zA-Z0-9_]
\s 空白符 等价于[\t\n\x0B\f\r]
\S 非空白符 等价于[^\t\n\x0B\f\r]

单词边界:
^ 以xxx开始
$ 以xxx结束
\b 单词边界
\B 非单词边界


五.量词
* 匹配0个或多个
+ 匹配1个或多个
? 匹配0个或1个
{n} 出现n次
{n,m} 出现n到m次
{n,} 至少出现n次
{0,n} 至多出现n次


六.JS正则贪婪模式与非贪婪模式
贪婪模式:尽可能的匹配多的

非贪婪模式:尽可能匹配少的(在量词后加上?)

七.分组
使用元字符()可以达到分组的功能,使量词作用于分组


或
使用元字符|可以达到或的效果

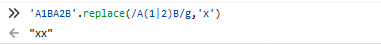
反向引用
使用元字符$实现反向引用


八.前瞻
正则表达式从文本头部向尾部开始解析,文本尾部方向称为“前”,文本头部方向称为“后”
前瞻就是在正则表达式匹配到规则的时候,向前检查是否符合断言,后顾后瞻方向相反
正向前瞻 exp(?=assert)
负向前瞻 exp(?!=assert)
正向后顾 exp(?<=assert) javascript不支持
负向后顾 exp(?>assert) javascript不支持

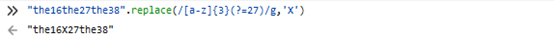

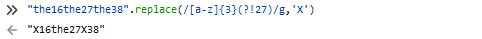
九.JS对象属性
global 是否全文搜索,默认false
ignore case 是否大小写敏感,默认是false
multiline 多行搜索,默认值是false
lastIndex 是当前表达式匹配内容的最后一个字符的下一个位置
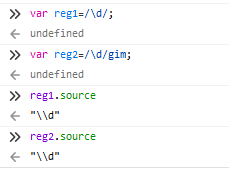
source 正则表达式的文本字符串

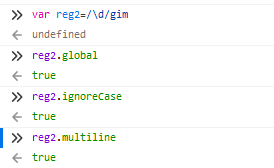
全局搜索大小写不敏感:

十.test和exec方法
regexp.prototype.txt(str) 用于测试字符串参数中是否存在匹配正则表达式模式的字符串

**Regexp.prototype.exec(str) 使用正则表达式模式对字符串执行搜索,并将更新全局regexp对象的属性以反映匹配结果
如果没有匹配的文本则返回null,否则返回一个结果数组:
Index 声明匹配文本的第一个字符的位置
Input 存放被检索的字符串string
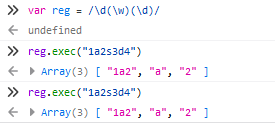
非全局调用
有则返回数组:
第一个元素是与正则表达式匹配的文本
第二个元素是与regexpobject的第一个子表达式相匹配的文本(如果有的话)
第三个元素是与regexpobject的第二个子表达式相匹配的文本(如果有的话),依次类推。
**
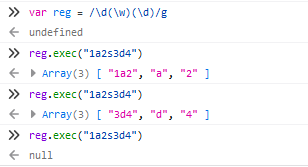
全局调用lastIndex会后移在上一个匹配的后面继续匹配,其他的输出和非全局调用一样
十一.字符串对象
1.String.prototype.search(reg)
search()方法用于检索字符串中指定的子字符串或检索与正则表达式相匹配的子字符串
方法返回第一个匹配结果index,查找不到返回-1
Search()方法不执行全局匹配,它将忽略标志g,并且总是从字符串的开始进行检索
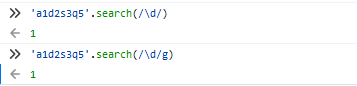
2.String.prototype.match(reg)
match()方法将检索字符串,以找到一个或多个与regexp匹配文本
regexp是否具有标志g对结果影响很大

3.String.prototype.split(reg)
split()方法把字符串分割为数组

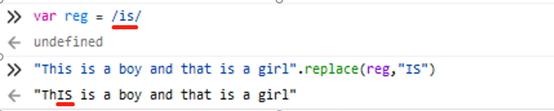
4.String.prototype.replace()
replace()把字符串中匹配的子字符串匹配为指定的字符或者字符串
String.prototype.replace(str,replaceStr)
String.prototype.replace(reg,replaceStr)
String.prototype.replace(reg,function)
regexp是否具有标志g对结果影响很大
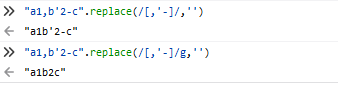
function参数含义
function会在每次匹配替换的时候调用,有四个参数
- 匹配字符串
- 正则表达式分组内容,没有分组则没有该参数
- 匹配项在字符串中的index
- 原字符串



{kind=link}