首先简单介绍一下网易杭州研究院情况简介,如下图所示:

我们公司主要从事平台技术开发和建设方面,工作的重点方向主要在解决用户在数据治理中的各种问题,让用户能更高效地管理自己的数据,进而产生更大的价值,比如如何整合现有功能流程,节省用户使用成本;增加新平台不断调研,丰富平台功能;新平台功能、性能改造,从而满足用户大规模使用需求;根据业务实际需求,输出相应解决方案等。今天分享的内容主要是从数据库内核到大数据平台底层技术开发,分享网易数据科学中心多年大数据建设经验。
1. 数据库技术
数据技术主要有 InnoSQL 和 NTSDB,NTSDB 是最近研发的新产品,预计明年将向外推荐此产品,InnoSQL 属于 MySQL 分支方面的研究大概从 2011 年开始的,InnoSQL 的主要目标是提供更好的性能以及高可用性,同时便于 DBA 的运维以及监控管理。

RocksDB 是以树的形式组织数据的产品,MySQL 有一个 MyRocks 产品,我们内部将其集成到 InnoSQL 分支上。这样做的原因是公司有很多业务,很多都是利用缓存保持其延迟,其规模会越来越大,这样就导致缓存、内存成本很高;其业务对延迟要求不是特别高,但要保持延迟稳定(小于 50 毫秒)。RocksDB 能够很好地将缓存控制的很好,随着缓存越来越大,有的公司会将其放到 HBase 上,但是其延迟有时波动会很大,如小米 HBase 很强,但还是做了一个基于 K-V 模式的缓存处理,主要解决延迟波动问题。我们主要是基于开源产品来解决,如将 RocksDB 集成起来解决公司业务对延迟稳定的一些需求。InnoRocks 由于是基于 LSM,因此对写入支持非常好,后续有内部测试数据可以展示。还有就是 LSM 压缩比很高,网易一种是替换缓存,一种是普通数据库存储,目前还是用 InnoDB 存储,如果用 InnoRocks 存储会节省很多存储空间;还有一个就是结合 DB 做扩展,将其集成到公司内部。
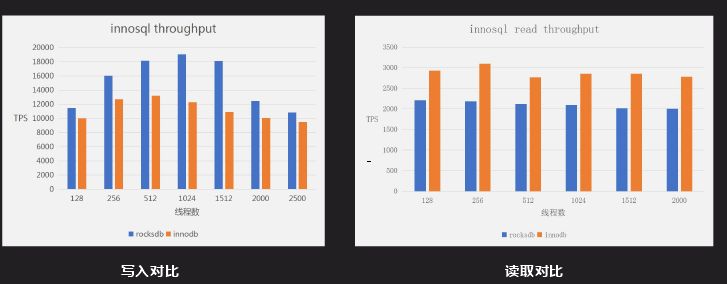
上图是写入对比,是一个普通的写入测试,其主介质是递增型的,对于两个都是一个顺序读写过程;如果要完全对比还要测试 RFID 写入测试,这样能够明显反应 RocksDB 和 InnoDB 的差距。图中 RocksDB 写入性能比 InnoDB 要好,读取性能 InnoDB 性能比 RocksDB。300GB 原始数据,分别导入到 Inno DB(未压缩) 和 Inno Rocks 后的存储容量对比,Inno DB 为 315GB 左右,Inno Rocks 为 50 ~ 60GB,存储容量是 Inno DB 的 20% 到 30%。
InnoRock 一般场景是替换 InnoDB 写入,因为其写入性能、压缩性能更好、成本也更低。另一方面能够解决 InnoDB 延迟不稳定,替换大量的缓存应用,只要其对相应时间没有特殊要求。
(1)大量数据写入场景,比如日志、订单等;
(2)需要高压缩以便存储更多的数据,Inno DB --> Inno Rocks;
(3)对写入延迟波动比较敏感,HBase --> Inno Rocks;
(4)相对较低的延迟要求 (10 ~ 50ms) 下替换缓存场景 (延迟 <5ms),节省内存成本, Redis --> Inno Rocks。
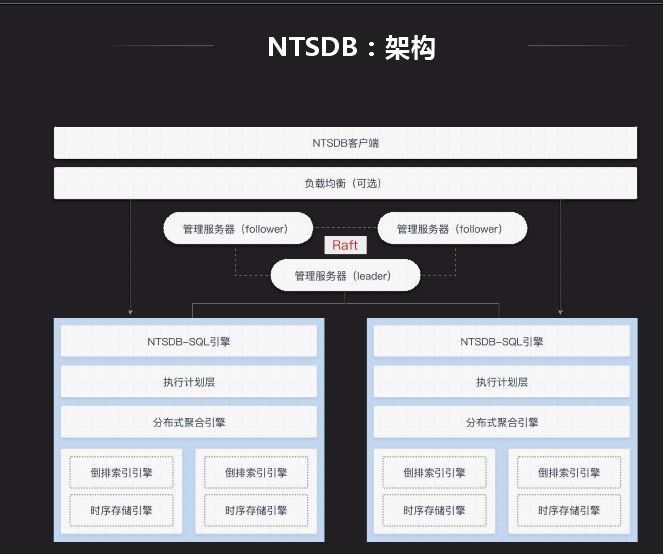
InnoSQL 是 MySQL 一个分支,同时还做了一个时序数据库。其不依赖第三方存储,重新做了一套。其架构也是列式存储,支持倒排索引等不同索引组织形式。对大型数据公司时序数据库集中在访问时通过什么去访问,我们提供 SQL 层给外部应用去访问,应用简单。
NTSDB 特点有聚合运算相关算法,时序数据库相对于关系型数据库没有特别复杂的查询,最常见的使用类型是宽表使用,在此基础上做一些聚合算法、插值查询。

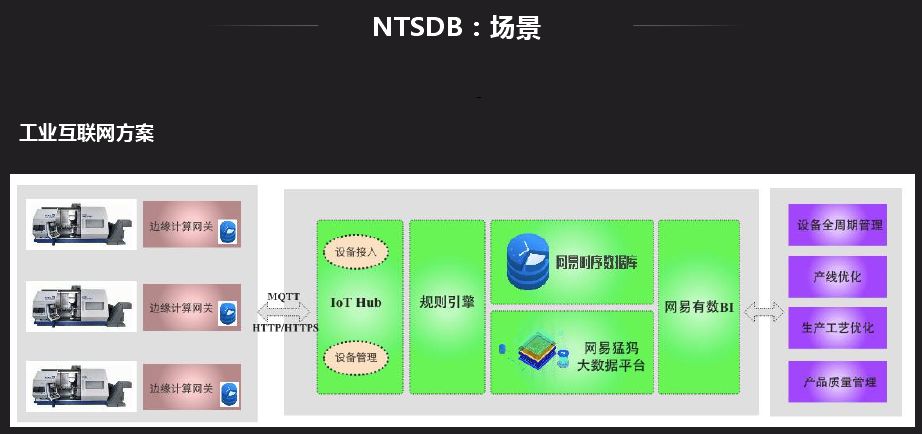
NTSDB 应用场景很多,很多应用都可以基于时序数据库来做,最常见的就是监控系统,有一些外部应用也会对接监控系统。外部应用中,现在 RIT 比较火,时序是其中比较重要的一环,很多设备目前都需要联网,数据的产生都是以时间的形式产生,有的通过规则引擎处理存储在时序数据库中。
2. 大数据技术
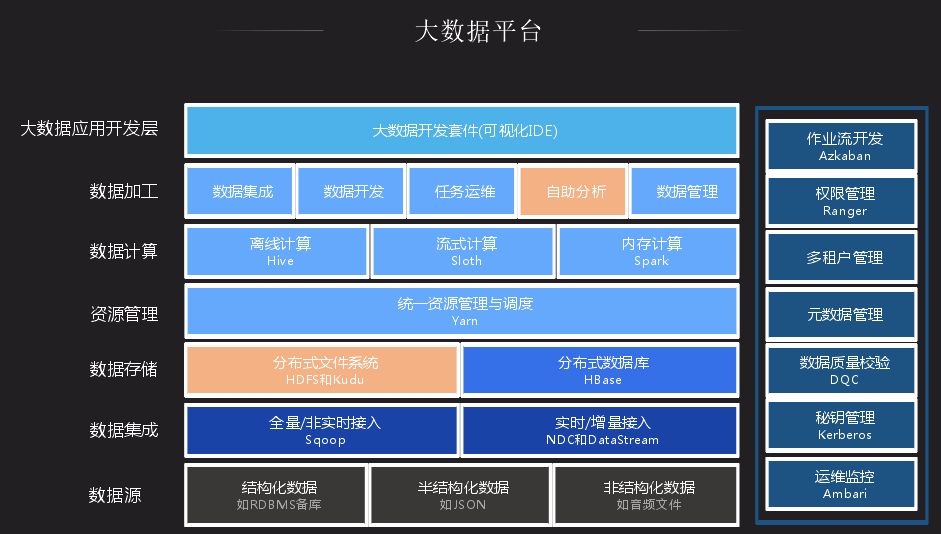
我们大数据平台整合了一些开源社区的一些组件,内部进行一些产品化的改造和 bug 修复。最顶层是大数据接入层,作为大数据平台,业务平台很多数据来源于数据库,也有很大一部分来源于日志。通过 NDC 做全量数据导入,如有些数据在 Oracle 中,通过 NDC 导入,后续可以通过数据变更来进行同步,还有一个通过 dataStream 将日志数据录入大数据平台。数据存储层大都差不多,都用 HDFS 存储,搭载一些 HBase 分布式存储;数据计算大都是离线计算平台,内存计算是基于 Spark;数据加工和一般大数据平台都差不多,我们加入了自助分析、任务运维,后续会详细介绍。接下来介绍自助分析里面应用的一个插件 Impala,以及分布式存储系统中的 Kudu 平台。
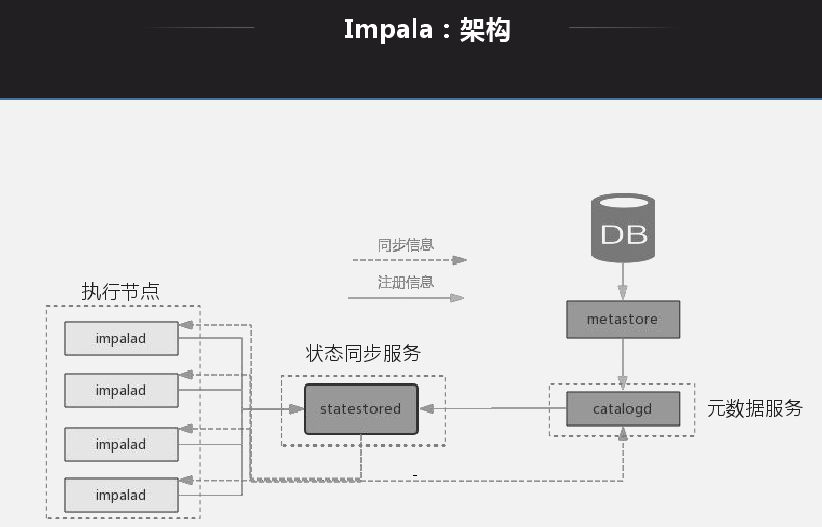
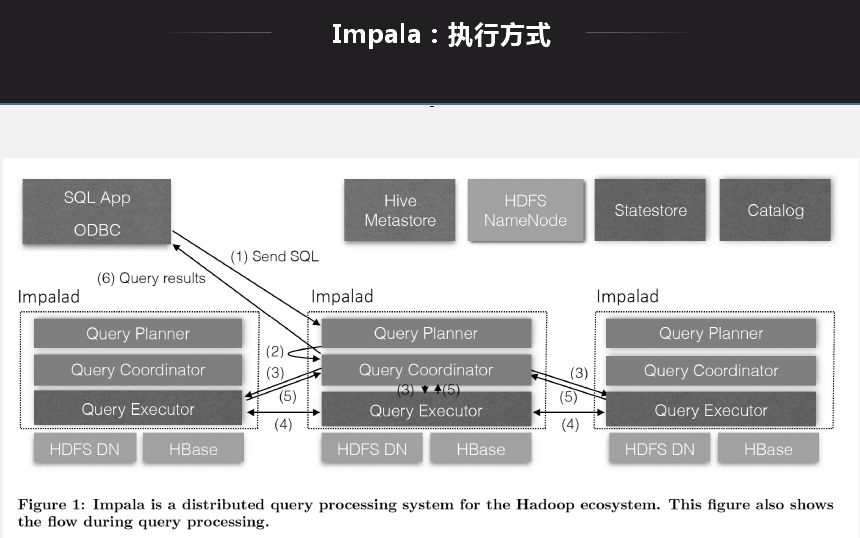
应用 Impala 目标是解决大数据量下的 ad-hoc 查询问题,ad-hoc 是介于 OITP 和 OIAP 中间的一层,OITP 是响应层很快,毫秒级;OIAP 查询有时会耗时很久。ad-hoc 定位与 1 分钟到几分钟,现在很多业务需要 ad-hoc 提供,如公司报表,有时需要实时计算,响应在 5 秒 -1 分钟延迟。
Impala 架构特点就是每一个节点都是无状态节点,节点查询地位一样,查询无论发送到哪一个节点都可以生成查询计划、产生结果。查询打到哪一个节点就能生成执行计划,将对应的节点分配给对应的处理节点,将所有节点返回后做一个规则,然后做一个返回。基本所有的 MPP 架构都是类似。

选择 Impala 而不选择其他工具的原因:首先它有元数据缓存,好处是节点缓存元数据做查询时不用再去获取元数据,缺点就是元数据爆炸问题;再者就是 Impala 兼容 Hive,元数据可以和 Hive 共享;同时还支持很多算子下推。Impala 最好使用方式是通过 Impala 自己 insert 然后通过其自己去查,实际过程是通过 Hive 和 Spark 写入大数据平台,通过 Impala 来做查询。这种方式有些限制就是写入时 Impala 无法感知写入,还有在 Hive 更改元数据,Impala 能读取数据但是无法动态感知,为了解决这个问题官方提供手动刷新操作。

Impala 缺陷就是所有节点都是 MPP 结构,没有统一的 Master 入口,负载均衡不易控制。底层数据权限粒度控制不够,HDFS 转 HBase 是以同级 HBase 身份访问,Impala 访问底层需要以 Impala 身份访问。这种问题尤其在同一平台下分有很多业务时,用 Hive 写数据时,访问权限就会有问题,因此我们在内部权限访问方面做了改造。每个 coordinator 节点都能接收 SQL,没有集中统一的 SQL 管理,如果挂掉所有历史信息都无法追踪。

我们基于 Impala 问题做了相应整改:
(1)首先是基于 Zookeeper 的 Load Balance 机制;
(2)管理服务解决 SQL 无法持续化问题,管理服务器保存最近几天的 SQL 和执行过程,便于后续 SQL 审计,超时 SQL 自动 kill;
(3)管理权限将底层权限分的很细;
(4)元数据缓存问题,增加与 Hive 的元数据同步功能,Hive 记录元数据变更,Impala 拉取变更自动同步,这种只能缓解元数据爆炸问题。
遗留的问题就是元数据容量,过滤智能解决部分问题;还有一个就是底层 IO 问题,因为离线写入和 Impala 查询是同一份数据,如果写入吃掉很多 IO,查询就会出现问题。离线本身对 IO 敏感很低。除此之外我们还引入了 ES 技术,公司 ES 业务也有很多,碰到问题就是 ES 在 SQL 支持方面不是很好,目前我们的 Impala 支持一些 ES 的查询。
Kudu 用于解决离线数据实时性问题,HDFS 存 K-v 数据,类似 IOAP 访问,Hive 是来做离线分析的,Kudu 就是想同时做这两件事情的背景下产生的。行为数据是在离线平台上,用户数据是实时在数据库中,如快递行业经常需要追踪快递的位置,离线平台就要经常做自助分析,需要将数据库中的状态实时同步到离线平台上去。目前做法就是数据库批量写入 Hive 表中,同时你的批量不能太小,容易产生很多小文件,这样可能造成数据实时性很差,一般是半小时到一小时的延迟。大部分业务可接受,但是对于对延迟敏感的业务可能不支持,Kudu 就是解决半小时到一小时的数据实时性。
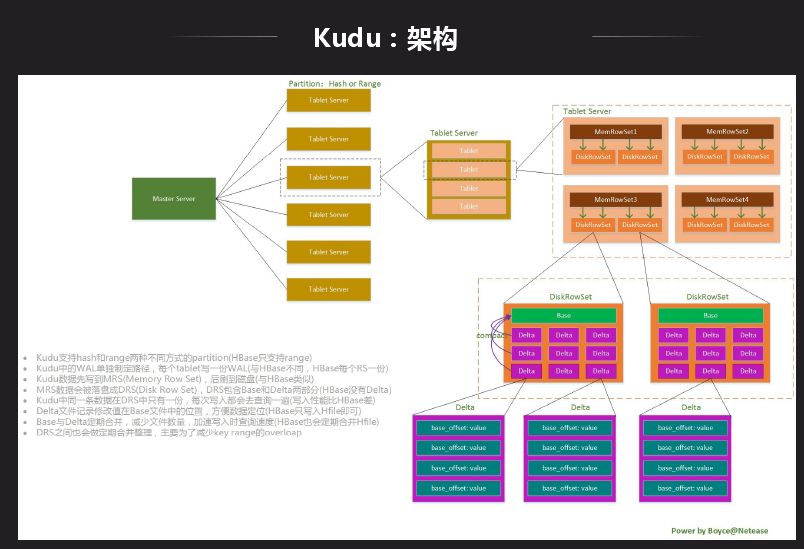
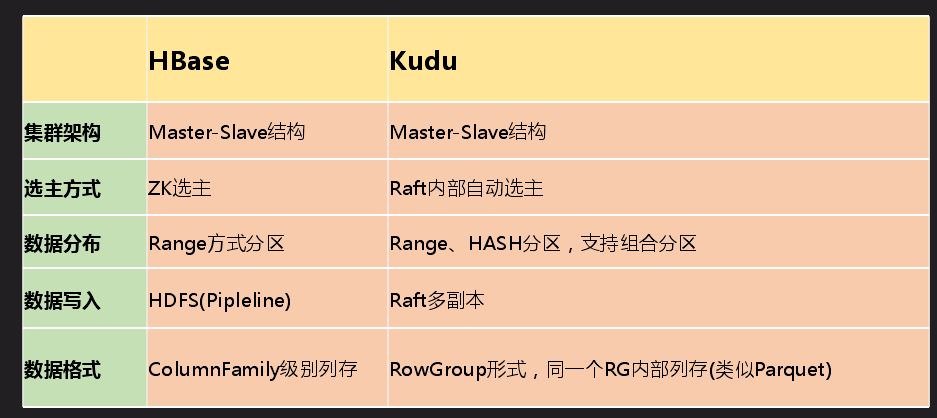
Kudu 是一个存储平台,不依赖于任何第三方存储系统,目前更类似于数据库形式,Impala 既能访问 Hive 中的数据,也能访问 Kudu 中的数据,这样的好处是两边的数据可以进行联合查询。Kudu 现在也支持 Spark,也可以直接通过 API 访问。上图是 Kudu 的结构划分到内部数据组织形式,Kudu 支持 Tablelet 操作而 HDFS 不支持。前面的结构和 HBase 挺像,不同的是数据组织形式是不一样的,Kudu 可以做一些分析性的业务查询。最主要的区别是数据存储格式不一样,Kudu 是 Column Family 级别列存,先整个切一块然后再做列组形式。
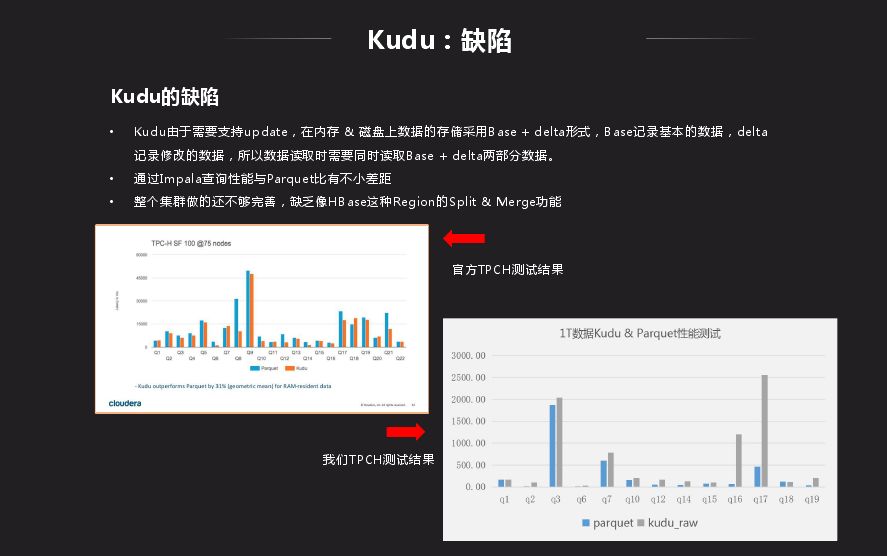
Kudu 跟 HDFS 相比性能还是有差距,Kudu 由于需要支持 update,在内存 & 磁盘上数据的存储采用 Base + delta 形式,Base 记录基本的数据,delta 记录修改的数据,所以数据读取时需要同时读取 Base + delta 两部分数据。
Kudu 优化主要是:
(1)支持 Kudu tablet 的 split;
(2)支持指定列的 TTL 功能;
(3)支持 Kudu 数据 Runtime Filter 功能;
(4)支持 Kudu 创建 Bitmap 索引。
我们主要是按照 HBase 进行优化,在有需要情况下优化,HBase 有而 Kudu 没有就对照的做。
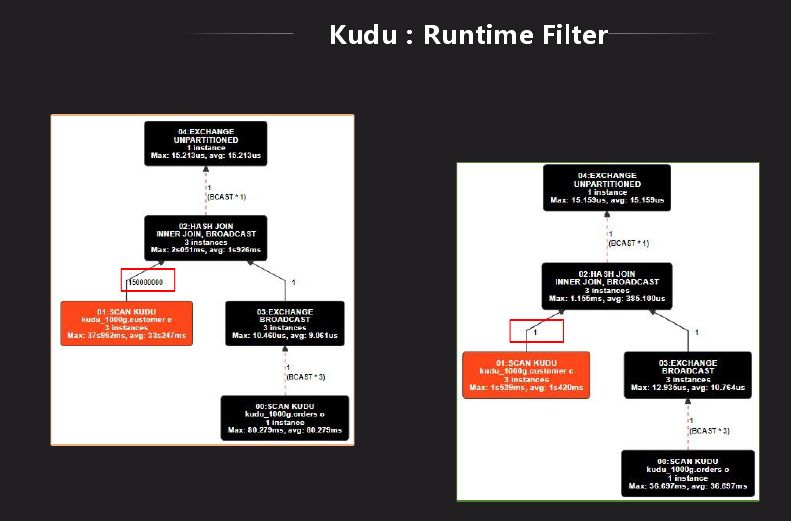
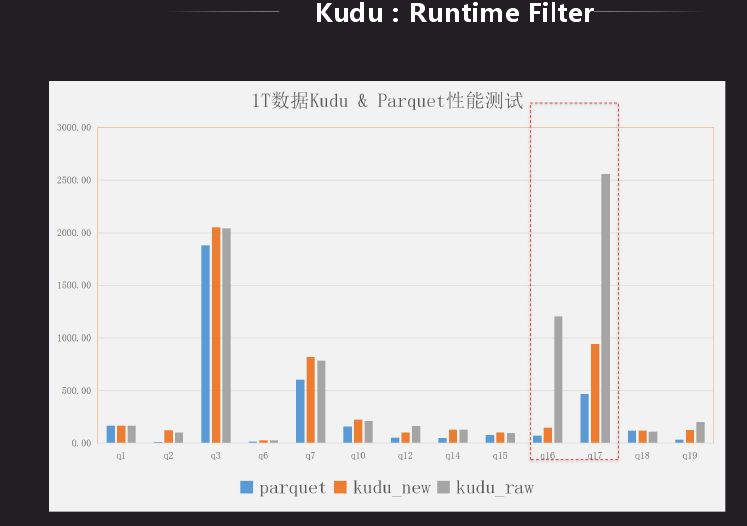
Impala 里面对 HDFS 有一个 Runtime Filter 功能,Kudu 表上没有,我们先分析下它到底有什么作用,是不是有性能上的改进,将其移植过来。Runtime Filter 主要是用在大表和小表做关联时使用,在关联时做成 hash 表,绑定到所有大表节点上去,在大表扫数据时利用 hash 表做过滤,因此在底层扫描就已经过滤掉很多数据,就可以省略很多不必要的计算。上图是 Kudu 的是否有 Runtime Filter 的结果对比,可以看出减少了很多计算量,原先需要几秒,现在只需秒级显示结果。结果对比有了很大的改进,虽然还是有差距,目前也在改进,目标是和 Impala 相差不是很大。

还有一个场景就是在 Kudu 上做 Bitmap 索引,主要面向的业务是宽表的多维过滤,有些表的查询会依据后面的实例去确定查询,这种用 Bitmap 做比一个个找出来查询性能要优越很多。另一个好处就是 group by,因为其要将相同类型合并到一列,主要是做 hash 或者排序,这种查询会很快,而不用做全局排序。Bitmap 应用的限制就是数据离散性不能太好,dinstct count 的值不能太多,向数据库中主键不适合做 Bitmap,像省份等值比较少的适合做 Bitmap。
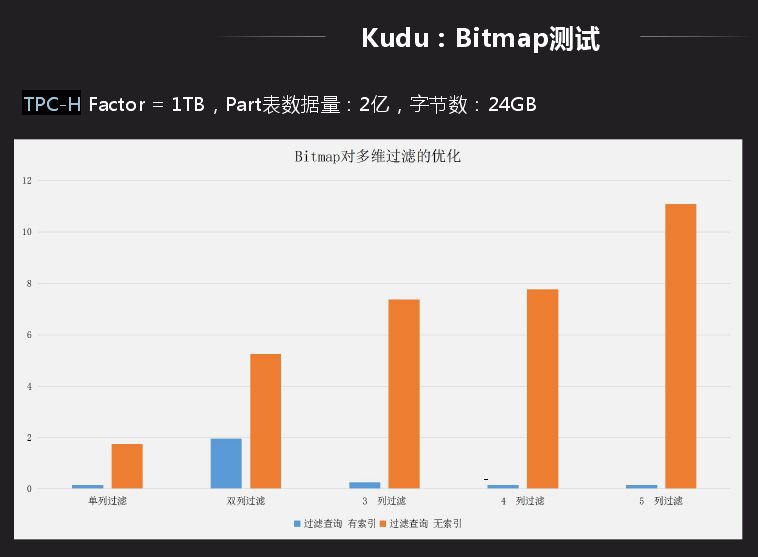
应用后用 TPC-H 中的一张表测试,Bitmap 主要应用多维场景过滤,从一列过滤、两列过滤、到五维过滤整个表现很好,性能提升有十几倍提升。如果数据从数据库导入大数据平台离线分析其实时性比较慢,主要局限小文件以及导入批量大小问题, 利用 Kudu 就不用考虑,可以直接通过 Kudu 实现数据变更导入大数据支持实时联查。而且可以实时同步 Oracle 和 MySQL 数据到 Kudu 中,进行联查就可以了,如果没有就需要同步查询可能需要半小时才能返回结果。
作者介绍:
蒋鸿翔,2011 年加入网易,网易数据科学中心首席架构师。《MySQL 内核:InnoDB 存储引擎 卷 1》作者之一,网易数据库内核和数据仓库平台负责人,长期从事数据库内核技术和大数据平台底层技术开发,主导网易数据库内核整体技术方案和大数据平台先进技术调研和实现,先后主导了内部 MySQL 分支 InnoSQL、HBase、自研时序数据库、自研实时数据仓库等各种不同的平台,具有丰富的数据库内核和大数据平台相关经验。
本文来自蒋鸿翔在 DataFun 社区的演讲,由 DataFun 编辑整理。
