题目1 : F1 Score
时间限制:10000ms
单点时限:1000ms
内存限制:256MB
描述
小Hi和他的小伙伴们一起写了很多代码。时间一久有些代码究竟是不是自己写的,小Hi也分辨不出来了。
于是他实现了一个分类算法,希望用机器学习实现自动分类。
为了评价这个分类算法的优劣,他选出了N份有标记的代码作测试集,并决定用F1 Score作为评价标准。
给出N份代码的实际作者是不是小Hi以及分类算法预测的结果,请你计算F1 Score。
输入
第一行包含一个整数N。(1 <= N <= 1000)
以下N行每行包含两个字符(+或-)。第一个字符代表这份代码的实际作者是不是小Hi(+代表是,-代表不是),第二个代表预测的作者是不是小Hi(+代表是,-代表不是)。
输出
一个百分数,X%,代表答案,X保留两位小数。
样例输入
4
+ +
+ -
- +
- -
样例输出
50.00%
题目思路:本题是要求它的F1分数(开始完全不知道F1分数是什么概念,怎么去用它,然后看了下百度百科)F1分数:是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
精确率:正确被检索到的占所有实际被检索到的的比例。(即第二个符号为+的)
召回率:正确被检索到的占所有应该被检索到的的比例。(即第二个符号为-的)
F1分数公式为:
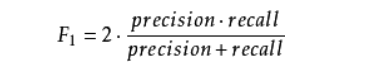
对于测试用例:精确率为++的个数除以++和-+的总数,,召回率为++的个数除以++和±的总数,都为1/2,带入公式得出结果1/2。
对于- - ,如果单独在一个测试用例出现则F1分数为100%,如果后面接上一个+ +,F1分数也为100%,如果后面接上一个+ - 或 - +,则为0%,则前面的多个 - -,不能作为判断依据。
AC代码如下:
#include<iostream>
#include<cstdio>
using namespace std;
int main()
{
double a, b, c, d, precision, recall, ans;
int n;
char a1[2];
cin >> n;
a = 0, b = 0, c = 0, d = 0;
while (n--)
{
cin >> a1[0] >> a1[1];
if (a1[0] == '+'&&a1[1] == '+')
{
a += 1;
}
else if (a1[0] == '+'&&a1[1] == '-')
{
b += 1;
}
else if (a1[0] == '-'&&a1[1] == '+')
{
c += 1;
}
else if (a1[0] == '-'&&a1[1] == '-')
{
d+=1;
}
}
if (a + c <= 1e-6)
{ //如果a+c趋近于零则赋值为1,下面同理
precision = 1;
}
else{
precision = a / (a + c);
}
if (a + b <= 1e-6)
{
recall = 1;
}
else{
recall = a / (a + b);
//召回重造机器误认为错的部分(即应该被检索到的部分)
}
if (precision + recall <= 1e-6)
{
ans = 200.0*precision*recall;
}
else{
ans = 200.0*precision*recall / (precision + recall);
}
printf("%.2f", ans);
cout << "%" << endl;
return 0;
}
