问题发现
部署在客户机器上的程序经常发生OOM异常:java.lang.OutOfMemoryError: GC overhead limit exceeded。
初步排查
1、系统本身代码问题;
2、系统大量调用了第三方接口http超时或者被第三方服务超量调用;
3、机器问题;
这个程序的主要作用就是拉取kafka里的消息落地到mysql,外加两个kafka消息写入及堆积的监控接口,不涉及到被其它系统调用或调用第三方接口;走查程序代码及日志,也没有发现明显的会出现死循环之类的bug和错误日志;查看机器的tcp状态也是正常的。
开始解决
1、使用top命令查看CPU情况发现8核CPU几乎被打满,发现是进程pid=32024导致;
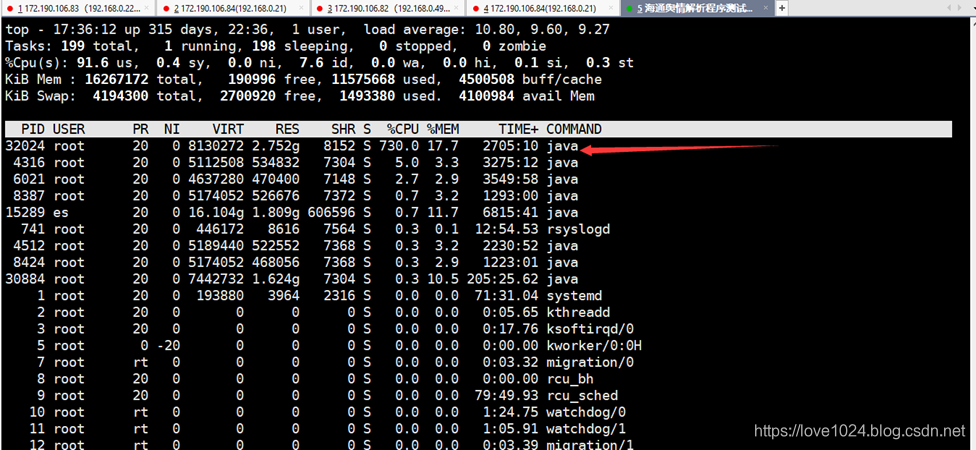
2、查看进程pid=32024对应的服务:ps -ef |grep 32024,确认过眼神,是我的那个java程序进程,程序使用nohup java -Xms2048m -Xmx2048m -jar ×××.jar >/dev/null 2>&1 &命令启动的;
3、查看pid=32024进程的线程情况:top -Hp 32024
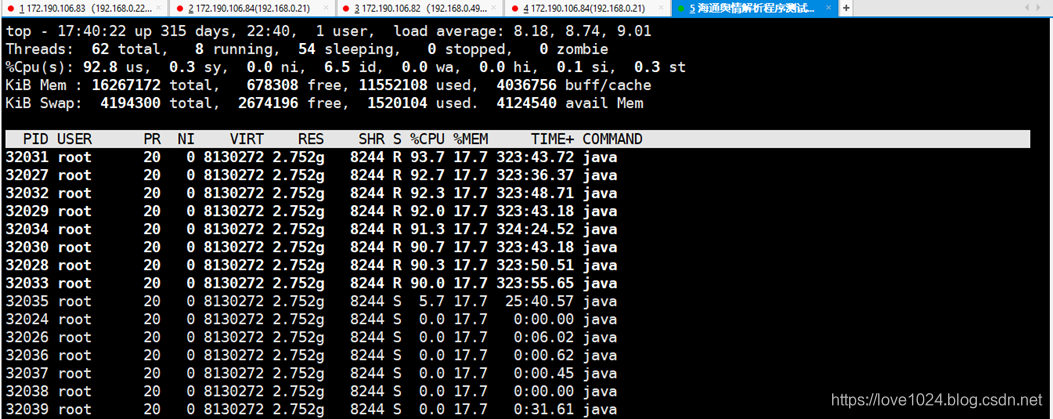
发现pid=32031/32027/32032/32029/32034/32030/32028/32033均占用了90%以上的CPU,把这几个十进制数抓换成十六进制表示(直接在linux上执行printf “%x\n” 32031),得到7d1f……
4、使用jstack打印线程堆栈日志,查找cpu耗时最多的线程,输出到根目录下的32024.txt文本里:jstack -l 32024 > /32024.txt,我这里只截取了最后的几行日志
"VM Thread" os_prio=0 tid=0x00007fb3281c6800 nid=0x7d23 runnable
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fb32801e000 nid=0x7d1b runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fb32801f800 nid=0x7d1c runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007fb328021800 nid=0x7d1d runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007fb328023800 nid=0x7d1e runnable
"GC task thread#4 (ParallelGC)" os_prio=0 tid=0x00007fb328025000 nid=0x7d1f runnable
"GC task thread#5 (ParallelGC)" os_prio=0 tid=0x00007fb328027000 nid=0x7d20 runnable
"GC task thread#6 (ParallelGC)" os_prio=0 tid=0x00007fb328028800 nid=0x7d21 runnable
"GC task thread#7 (ParallelGC)" os_prio=0 tid=0x00007fb32802a800 nid=0x7d22 runnable
"VM Periodic Task Thread" os_prio=0 tid=0x00007fb328236800 nid=0x7d2c waiting on condition
JNI global references: 2869
发现nid=0x~,对应的就是步骤三得到的占用线程pid,也就是说大量的GC动作导致了程序变慢,最后OOM
5、使用jstat查看进程32024的内存占用情况:jstat -gcutil 32024 1s 5,间隔1秒打印一次,共5次
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 100.00 99.98 94.79 91.73 2132 22.344 18637 22794.374 22816.719
0.00 0.00 100.00 99.98 94.79 91.73 2132 22.344 18637 22794.374 22816.719
0.00 0.00 100.00 99.98 94.79 91.73 2132 22.344 18638 22795.902 22818.247
0.00 0.00 100.00 99.98 94.79 91.73 2132 22.344 18639 22797.042 22819.387
0.00 0.00 100.00 99.98 94.79 91.73 2132 22.344 18640 22798.052 22820.396
发现Eden、Survivor、老年代空间占用比例近100%,GC的次数和时间也比较高
6、使用jmap查看进程32024里占用的对象情况:jamp -histo 32024,我这里截取占用内存最多的部分日志
num #instances #bytes class name
----------------------------------------------
1: 60659 879225944 [B
2: 2569438 194899192 [C
3: 1791132 108050840 [Ljava.util.HashMap$Node;
4: 3355102 107363264 java.util.HashMap$Node
5: 2604306 104172240 java.util.LinkedHashMap$Entry
6: 1467554 82183024 java.util.LinkedHashMap
7: 2568223 61637352 java.lang.String
8: 1041842 46497648 [Ljava.lang.Object;
9: 1248847 39963104 java.util.concurrent.ConcurrentHashMap$Node
10: 9415 33631640 [J
11: 923899 29564768 org.apache.kafka.common.MetricName
12: 923899 29564768 org.apache.kafka.common.metrics.KafkaMetric
13: 1191788 28602912 org.apache.kafka.common.requests.ApiVersionsResponse$ApiVersion
14: 1031412 24753888 java.util.ArrayList
15: 445931 21404688 java.util.HashMap
16: 425192 17007680 io.micrometer.core.instrument.Meter$Id
17: 258692 16556288 org.apache.kafka.common.metrics.Sensor
18: 926570 14825120 java.util.LinkedHashMap$LinkedEntrySet
19: 304886 14634528 org.apache.kafka.common.metrics.stats.SampledStat$Sample
20: 37121 14036960 [Ljava.util.concurrent.ConcurrentHashMap$Node;
21: 295803 11832120 io.micrometer.shaded.org.pcollections.IntTree
22: 296597 9491104 java.lang.ref.WeakReference
23: 295803 9465696 io.micrometer.shaded.org.pcollections.ConsPStack
24: 295712 9462784 io.micrometer.core.instrument.binder.kafka.KafkaConsumerMetrics$$Lambda$1382/1190566357
25: 286409 9165088 org.apache.kafka.common.metrics.stats.Meter
26: 559525 8952400 java.lang.Object
27: 258692 8278144 org.apache.kafka.common.MetricNameTemplate
28: 305083 7321992 java.util.AbstractMap$SimpleImmutableEntry
29: 286409 6873816 org.apache.kafka.common.metrics.stats.Rate
30: 286409 6873816 org.apache.kafka.common.metrics.stats.Total
31: 268050 6433200 io.micrometer.core.instrument.internal.DefaultGauge
32: 304994 4879904 java.util.concurrent.atomic.AtomicReference
33: 147824 4730368 org.apache.kafka.common.metrics.stats.Avg
34: 147824 4730368 org.apache.kafka.common.metrics.stats.Rate$SampledTotal
35: 194215 4661160 javax.management.ObjectName$Property
36: 166470 4439320 [Ljavax.management.ObjectName$Property;
37: 138585 4434720 org.apache.kafka.common.metrics.stats.Count
38: 138584 4434688 org.apache.kafka.common.metrics.stats.Max
39: 258692 4286896 [Lorg.apache.kafka.common.metrics.Sensor;
40: 261683 4186928 java.util.LinkedHashSet
41: 83235 3329400 javax.management.ObjectName
42: 15980 3243304 [I
43: 27735 3106320 sun.nio.ch.SocketChannelImpl
44: 129380 3105120 io.micrometer.core.instrument.MeterRegistry$$Lambda$348/319558327
45: 129380 3105120 io.micrometer.core.instrument.MeterRegistry$1
46: 37453 2396992 java.util.concurrent.ConcurrentHashMap
47: 140245 2243920 java.util.LinkedHashMap$LinkedKeySet
48: 46248 2219904 java.nio.HeapByteBuffer
49: 129412 2070592 java.util.HashMap$EntrySet
50: 83227 1997448 com.sun.jmx.mbeanserver.NamedObject
51: 120943 1935088 java.util.LinkedHashMap$LinkedValues
52: 73912 1773888 org.apache.kafka.common.metrics.JmxReporter$KafkaMbean
53: 27717 1773888 org.apache.kafka.common.network.KafkaChannel
54: 15256 1687808 java.lang.Class
55: 27717 1552152 org.apache.kafka.clients.ClusterConnectionStates$NodeConnectionState
56: 92963 1487408 java.util.HashSet
57: 36954 1478160 org.apache.kafka.common.network.NetworkReceive
58: 9239 1404328 org.apache.kafka.clients.consumer.internals.ConsumerCoordinator
59: 42802 1369664 java.net.InetAddress$InetAddressHolder
60: 55466 1331184 java.net.InetSocketAddress$InetSocketAddressHolder
61: 55434 1330416 org.apache.kafka.common.utils.LogContext$LocationAwareKafkaLogger
62: 37815 1210080 java.util.Hashtable$Entry
63: 9239 1182592 org.apache.kafka.clients.consumer.internals.FetcherMetricsRegistry
64: 27735 1109400 sun.nio.ch.SelectionKeyImpl
65: 27735 1109400 sun.nio.ch.SocketAdaptor
66: 27733 1109320 java.util.EnumMap
占用最多的是HashMap对象,存放大量KafkaConsumer里的Metric对象
7、基本上问题已经定位到了,走查代码发现:程序里有个获取kafka消息堆积量的接口,里面使用到了KafkaConsumer连接kafka,由于要统计的是多个topic,我们是在循环里每次用KafkaConsumer去连接的(KafkaMetric就是在KafkaConsumer对象里的),每次连接完没有关闭KafkaConcumer连接,而且这个接口前端调用的比较频繁,导致大量KafkaConsumery引用一直存活,且越来越多(GCRoot可达),修改代码后版本迭代,观察了几天没问题了。
8、为了直观一些的话,步骤6也可以直接dump程序的堆转储快照下来分析,用JAVA_HOME/bin/jvisualvm.exe可视化开分析,生成堆转储快照的命令是:jmap -dump:live,format=b,file=×××.dump 32024
其它相关
首先要正确区分内存溢出和内存泄露,这是两个不同的概念,本质上都是没有合理使用JVM导致。内存溢出是指虚拟机扩展无法申请到足够的内存(系统没有多余的内存可以分配给你),内存泄露是指使用完内存空间没有释放,当内存中加载了太多对象,比如一次性从数据库中查询返回了太多对象、循环或者死循环创建太多对象且没有释放引用、jvm启动参数设置的过小……都有可能导致JVM内存泄露或溢出。
