------------恢复内容开始------------
写这篇博客说明我已经成功了,即将说明我这几天遭遇的辛酸史。。。。
自己对yolo来说也是一知半解的,首先就去了解了下原理,推荐下b站里吴恩达的yolo视频,虽然是全英文不过也是挺好懂的。
第一篇还是说说原理
Yolo算法,其全称是You Only Look Once: Unified, Real-Time Object Detection,其实个人觉得这个题目取得非常好,基本上把Yolo算法的特点概括全了:You Only Look Once说的是只需要一次CNN运算,Unified指的是这是一个统一的框架,提供end-to-end的预测,而Real-Time体现是Yolo算法速度快
滑动窗口与CNN
滑动窗口技术
其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图3所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。
图3 采用滑动窗口进行目标检测(来源:deeplearning.ai)


如果你使用的是CNN分类器,那么滑动窗口是非常耗时的。但是结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,如图4所示。输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。这其实是overfeat算法的思路。之所可以CNN可以实现这样的效果是因为卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。说点题外话,这个思路也被R-CNN借鉴,从而诞生了Fast R-cNN算法。
图4 滑动窗口的CNN实现(来源:deeplearning.ai)
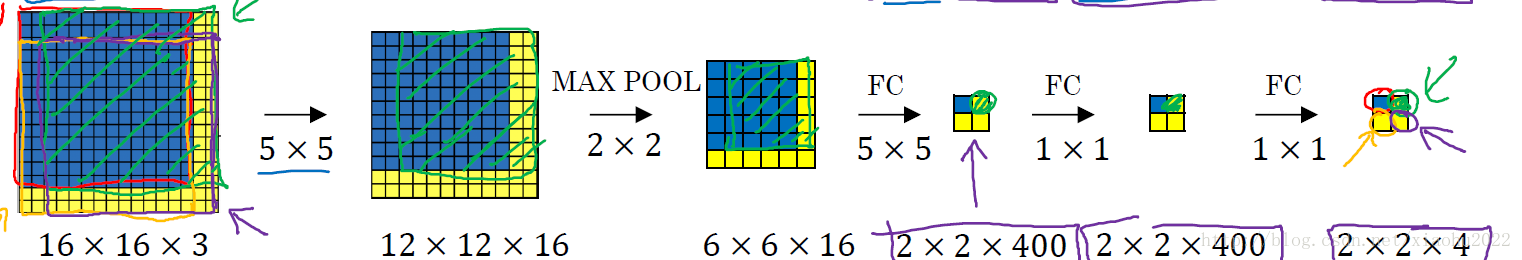

上面尽管可以减少滑动窗口的计算量,但是只是针对一个固定大小与步长的窗口,这是远远不够的。Yolo算法很好的解决了这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。下面将详细介绍Yolo算法的设计理念。
YOLO检测原理:
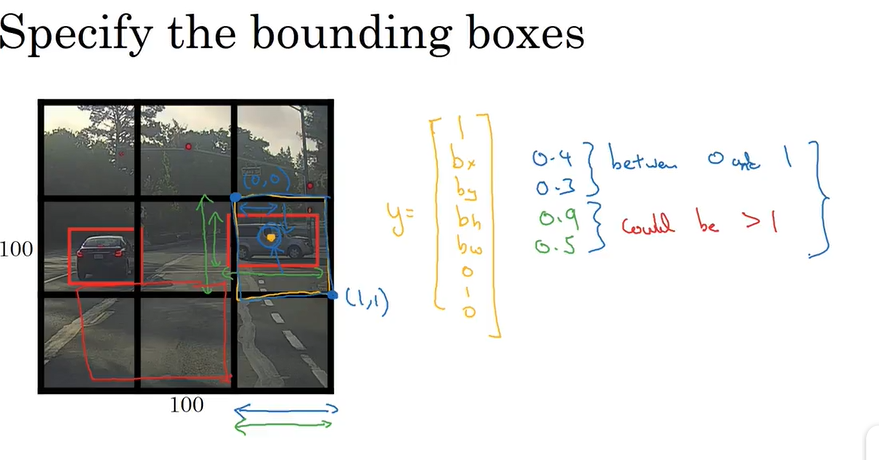
Yolo的CNN网络将输入的图片分割成S\times S网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图6所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为Pr(object),当该边界框是背景时(即不包含目标),此时Pr(object)=0。而当该边界框包含目标时,Pr(object)=1。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为\text{IOU}^{truth}_{pred}。因此置信度可以定义为Pr(object)*\text{IOU}^{truth}_{pred}。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:(x, y,w,h),其中(x,y)是边界框的中心坐标,而w和h是边界框的宽与高。还有一点要注意,中心坐标的预测值(x,y)是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图6所示。而边界框的w和h预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在[0,1]范围。这样,每个边界框的预测值实际上包含5个元素:(x,y,w,h,c),其中前4个表征边界框的大小与位置,而最后一个值是置信度。

卷积神经网络
1.卷积核


上面是yolo所需要的一些原理部分
训练
------------恢复内容结束------------