依旧是第四天
学会知识迁移,把看过的基础的常见的知识应用在复杂问题上
分解复杂问题,使之简单化,把复杂问题分步骤解决
复杂链表
比较复杂的链表,可能涉及树啊什么的
复杂链表的赋值
请实现函数ComplexListNode* Clone(ComplexListNode* pHead),复制一个复杂链表。在复杂链表中,每个节点除了有一个pNextNode指针指向下一个节点,还有一个siblingNode指针指向链表中的任意节点或nullptr。
如图,在复杂链表中,除了有指向下一个节点的指针(实线),还有指向任意节点的指针(虚线)
思路:
1、复制原始链表的任意节点N并创建新节点N’,再把N‘链接到N的后面

2、设置复制出来的节点的siblingNode。假设原始链表上的N的siblingNode指向节点S,那么其对应复制出来的N’是N的nextNode指向的节点。设置siblingNode之后的链表如下图:
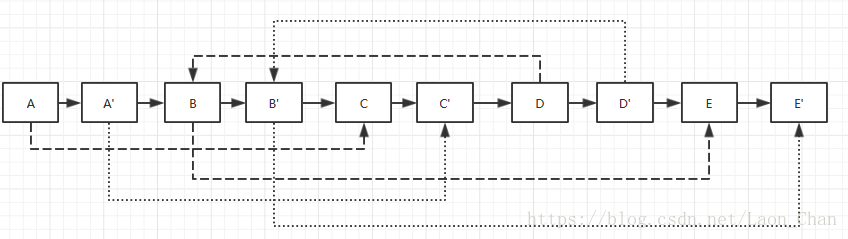
3、把长链表拆分成两个链表:奇数位置的节点用nextNode链接起来就是原始链表,偶数位置的节点用nextNode链接起来就是复制出来的链表
考虑空链表、只有一个节点的链表、siblingNode形成环的情况、siblingNode指向自己的情况
//复杂链表结构体的声明
struct ComplexListNode
{
int value;
ComplexListNode* nextNode;
ComplexListNode* siblingNode;
};
//第一步:复制构成长链表
void CloneNodes(ComplexListNode* pHead)
{
ComplexListNode* pNode = pHead;
while (pNode != nullptr) {
ComplexListNode* pClone = new ComplexListNode();
pClone->value = pNode->value;
pClone->nextNode = pNode->nextNode;
pNode->nextNode = pClone;
pClone->siblingNode = nullptr;
pNode = pClone->nextNode;
}
}
//第二步:设置克隆点的siblingNode指针
void ConnectSiblingNodes(ComplexListNode* pHead)
{
ComplexListNode* pNode = pHead;
while (pNode != nullptr) {
ComplexListNode* pClone = pNode->nextNode;
if (pNode->siblingNode != nullptr)
pClone->siblingNode = pNode->siblingNode->nextNode;
pNode = pNode->nextNode;
}
}
//第三步:奇偶节点分别连接
ComplexListNode* ReconnectNodes(ComplexListNode* pHead)
{
ComplexListNode* pNode = pHead;
ComplexListNode* pCloneHead = nullptr;
ComplexListNode* pCloneNode = nullptr;
if (pNode != nullptr) {
pCloneNode = pNode->nextNode;
pCloneHead = pNode->nextNode;
pNode->nextNode = pCloneHead->nextNode;
pNode = pNode->nextNode;
}
while (pNode != nullptr) {
pCloneNode->nextNode = pNode->nextNode;
pCloneNode = pCloneNode->nextNode;
pNode->nextNode = pCloneNode->nextNode;
pNode = pNode->nextNode;
}
return pCloneHead;
}
ComplexListNode* Clone(ComplexListNode* pHead)
{
CloneNodes(pHead);
ConnectSiblingNodes(pHead);
return ReconnectNodes(pHead);
}二叉搜索树与双向链表
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。比如:

思路:
1、在二叉树中,每个节点都有两个指向子节点的指针。在双向链表中,每个节点也有两个指针,分别指向前一个节点和后一个节点。在搜索二叉树中,左子节点的值总是小于父节点的值,右子节点的值总是大于父节点的值。因此,我们将二叉搜索树转换成排序双向链表时,原先指向左子节点的指针调整为链表中指向前一个节点的指针,原先指向右子节点的指针调整为链表中指向后一个节点的指针。
2、中序遍历是按照从小到大的顺序遍历二叉树的每个节点。当遍历到根节点时,把树看成是由三部分组成的——根节点的左子树 + 根节点 + 根节点的右子数。根据排序的定义,根节点的值将和左子树中最大的值连接起来,根节点10还将和右子数中最小的值的节点连接起来。
3、按照中序遍历的顺序,当我们遍历转换到根节点时,它的左子树已经转换为一个排序的链表了,并且处在链表的最后一个节点是当前值最大的节点8。我们把值为8的节点和根节点链接起来,此时链表中的最后一个节点就是10。接着遍历转换右子数,并把根节点和右子数中最小的节点链接起来。至于怎么去转换子树,方法和以10为根节点的树一样,所以就可以想到使用递归。
struct BinaryNode
{
int value;
BinaryNode* leftNode;
BinaryNode* rightNode;
};
void ConvertNode(BinaryNode* pNode, BinaryNode** pLastNode)
{
if (pNode == nullptr)
return;
BinaryNode* pCurrentNode = pNode;
if (pCurrentNode->leftNode != nullptr)
ConvertNode(pCurrentNode->leftNode, pLastNode);
//因为一直递归进去,所以其实第一个使用值为10的pLastNode的是左边的最下面的一个节点
//其他函数使用pLastNoded到这一步的时候已经被函数改变了
pCurrentNode->leftNode = *pLastNode;
if (*pLastNode != nullptr)
(*pLastNode)->rightNode = pCurrentNode; //左子树的最后一个节点的右指针为(子树)其根节点
*pLastNode = pCurrentNode;//现在最后一个节点是根节点了
if (pCurrentNode->rightNode != nullptr)
ConvertNode(pCurrentNode->rightNode, pLastNode);
}
BinaryNode* Convert(BinaryNode* rootNode)
{
BinaryNode* pLastNode = nullptr;
ConvertNode(rootNode, &pLastNode); //注意与参数进行比较
BinaryNode* pHeadList = pLastNode;
while (pHeadList != nullptr && pHeadList->leftNode != nullptr)
pHeadList = pHeadList->leftNode;
return pHeadList;
}代码一开始不是很懂,但是画图!画图!画图!
圆圈中最后剩下的数字
0,1,……,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字。求出这个圆圈里剩下的最后一个数字。(约瑟夫环)。如下图所示:

思路:
方法1是用环形链表模拟圆圈(经典做法);方法2是分析每次被删除的数字的规律并直接计算出圆圈中最后剩下的 数字
经典的做法:
创建一个共有n个节点的环形链表,然后每次在这个链表中删除第m个节点。可以使用标准模板库中的std::list来模拟一个环形链表(但是可能面试官不允许使用那就自己写一个链表)。
由于std::list本身不是一个环形结构,所以每当迭代器Iterator扫描到链表的末尾时,要记得把迭代器移到链表的头部,这样就能按照顺序在一个圆圈里遍历了
//时间复杂度O(mn),空间复杂度O(n)
int lastRemaining(unsigned int n, unsigned int m)
{
if (n < 1 || m < 1)
return -1;
unsigned int i;
list<int> numbers;
for (int i = 0; i < n; i++)
numbers.push_back(i);
list<int>::iterator current = numbers.begin();
while (numbers.size() > 1) {
for (int i = 0; i < m; i++)
{
current++;
if (current == numbers.end())
current = numbers.begin();
}
//记录下一个,要不然删掉后会掉链
list<int>::iterator next = ++current;
if (next == numbers.end())
next = numbers.begin();
--current;
numbers.erase(current);
current = next; //删掉第m个之后,从被删掉的节点的下一个节点开始新一轮的循环
}
return *current;
}机智的做法
首先定义一个关于n和m的方程f(n,m),标识每次在n个数字0,1,……,n-1中删除第m个数字最后剩下的数字
在n个数字中,第一个被删除的数字是(m-1)%n。把(m-1)%n记作k,那么删除k之后的序列为0,1,……,k-1,k+1,……,n-1,并且下一次删除从数字k+1开始计数。相当于在剩下的序列中,k+1是排在最前面的(相当于原本序列的0),从而形成k+1,k+2,……,n-1,0,1,……,k-1。该序列最后剩下的数字与原本序列最后剩下的数字是一样的,本来就只是变形而已,而且这个序列删除第m个数字也应该是关于n和m的函数,记为f'(n-1,m)[=f(n,m)]
下面是把原本序列减去第m个数后得到的序列进行映射:

映射p(x)=(x-k-1)%n,这是指得到在现在的排序(右边中)个,值为x的数排第几。所以如果是要删除第m个数,其实就是要删除序列中,值为((k+1)+m-1)%n=(m+k)%n的数。p^-1(x)=(x+k+1)%n表示从右边的数得到真正当前序列中的值
f(n,m)=f'(n-1,m)=[f(n-1,m)+m]%n,形成一个递归的算法
int lastRemaining(unsigned int n, unsigned int m)
{
if (n < 1 || m < 1)
return -1;
int last = 0; //当n=1时,最后剩下的一个数也就只有0,不需要进行操作
//根据以上的分析,之后的序列中有两个数的序列可以根据有一个数的序列计算出最后剩下的数字的值。其他序列也类似
for (int i = 2; i <= n; i++)
last = (last + m) % i;//用比当前序列数量小于1的序列计算出当前序列最后剩下的数
return last;
}第二种做法难度有点大,分析的过程难,数学思维要很灵活才能想到,要找出规律,还要用到逆函数的思想,真是有点难,很难想到有这样的做法,但是这种做法的空间复杂度是O(1),时间复杂度是O(n)