一、谱聚类的演算
(一)、演算
1、谱聚类概览
谱聚类演化于图论,后由于其表现出优秀的性能被广泛应用于聚类中,对比其他无监督聚类(如kmeans),spectral clustering的优点主要有以下:
1.过程对数据结构并没有太多的假设要求,如kmeans则要求数据为凸集。
2.可以通过构造稀疏similarity graph,使得对于更大的数据集表现出明显优于其他算法的计算速度
3.由于spectral clustering是对图切割处理,不会存在像kmeans聚类时将离散的小簇聚合在一起的情况。
4.无需像GMM一样对数据的概率分布做假设
同样,spectral clustering也有自己的缺点,主要存在于构图步骤,有如下:
1.对于选择不同的similarity graph比较敏感(如 epsilon-neighborhood, k-nearest neighborhood, full connected 等)
2.对于参数的选择也比较敏感(如epsilon-neighborhood的epsilon,k-nearest neighborhood的k)
谱聚类过程主要有两步,第一步是构图,将采样点数据构造成一张网图,表示为G(V,E),V表示图中的点,E表示点与点之间的边,如下图:
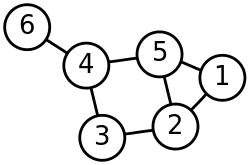
图1 谱聚类构图(来源wiki)
第二步是切图,即将第一步构造出来的按照一定的切边准则,切分成不同的图,而不同的子图,即我们对应的聚类结果,举例如下:
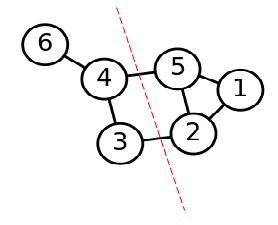
图2 谱聚类切图
初看似乎并不难,但是…,下面详细说明推导。
2、谱聚类构图
在构图中,一般有三种构图方式:
3. fully connected
前两种可以构造出稀疏矩阵,适合大样本的项目,第三种则相反,在大样本中其迭代速度会受到影响制约,在讲解三种构图方式前,需要引入similarity function,即计算两个样本点的距离,一般用欧氏距离:

Si,j表示样本点xi与xj的距离,或者使用高斯距离
其中σ 的选取也是对结果有一定影响,其表示为数据分布的分散程度,通过上述两种方式之一即可初步构造矩阵S:Si,j=[s]i,j,一般称 为Similarity matrix(相似矩阵)。
对于第一种构图ε-neighborhood,顾名思义是取si,j≤ε的点,则相似矩阵S可以进一步重构为邻接矩阵(adjacency matrix)W:



 ,则重构之后的矩阵
W
与之前的相似矩阵
S
相同,为:
Wi,j=Si,j=[s]i,j
。
,则重构之后的矩阵
W
与之前的相似矩阵
S
相同,为:
Wi,j=Si,j=[s]i,j
。
(1).计算阶矩(degree matrix)D:

如此,在构图阶段基本就完成了,至于为什么要计算出拉普拉斯矩阵 L ,可以说 L=D−W 这种形式对于后面极大化问题是非常有利的(不知道前人是怎么想到的,不然 L 也不会被命名为拉普拉斯了吧)。
3、谱聚类切图
谱聚类切图存在两种主流的方式:RatioCut和Ncut,目的是找到一条权重最小,又能平衡切出子图大小的边,下面详细说明这两种切法。
在讲解RatioCut和Ncut之前,有必要说明一下问题背景和一些概念,假设V为所有样本点的集合,{A1,A2,⋯,Ak}、表示V的子集集合,其中A1∪A2∪⋯∪Ak=V且A1∩A2∩⋯∩Ak=∅、、,则子集与子集之间连边的权重和为:

(这里除以1/2的原因是i从1遍历到k的过程中,每条边的权重实际上算了2次,可以自己代个值进去算下)
其中Ai¯为Ai的补集,意为除Ai子集外其他V的子集的并集,W(Ai,Ai¯)为Ai与其他子集的连边的和,为:

其中 W m,n 为邻接矩阵W中的元素。
由于我们切图的目的是使得每个子图内部结构相似,这个相似表现为连边的权重平均都较大,且互相连接,而每个子图间则尽量没有边相连,或者连边的权重很低,那么我们的目的可以表述为:

但是稍微留意可以发现,这种极小化的切图存在问题,如下图:
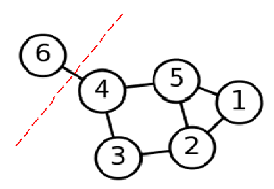
图3 问题切图
如上图,如果用min cut(A1,A2,⋯,Ak)这种方法切图,会造成将V切成很多个单点离散的图,显然这样是最快且最能满足那个最小化操作的,但这明显不是想要的结果,所以有了RatioCut和Ncut,具体地:


其中 |Ai| 为 Ai 中点的个数, vol(Ai) 为 Ai 中所有边的权重和。
下面详细讲解这两种方法的计算:Ratiocut & Ncut
(1).Ratiocut
Ratiocut切图考虑了目标子图的大小,避免了单个样本点作为一个簇的情况发生,平衡了各个子图的大小。Ratiocut的目标同样是极小化各子图连边和,如下:

对上述极小化问题做一下转化,引入{A1,A2,⋯,Ak}的指示向量hj={hj1,hj2,...,hjn},j=1,2...,k.其中i表示样本下标,j表示子集下标, 表示样本i对子集j的指示,具体为:

 ,否则为0。
这里hi满足相互正交,所以hj实际上可以认为是一种划分的向量,它表明各个样本被划分到哪个类中。
,否则为0。
这里hi满足相互正交,所以hj实际上可以认为是一种划分的向量,它表明各个样本被划分到哪个类中。
进一步,计算 ,可以得到:

第一步,第二步转化,利用上文拉普拉斯矩阵定义L=D-W;
第三步,m,n分别表示第m,n个样本,其最大值均为N,D,W均为对称矩阵,此步主要将矩阵内积离散化为元素连加求和形式;
进一步地,做如下:

注: L有一些特点:(1)L是对称的并且是半正定的( 实对称并且任给X,满足XTLX>=0)
(2)L的最小特征值是0,对应的特征向量是(1,1,1,1...,1)n*1 因为L=D-W,因此L的各行之和为0,且无论W是否存在自环都一样
(3) L有n个非负的实特征
2. 未规则化的拉普拉斯算子及其特征值、特征向量可用来描述图的许多性质. 在谱聚类中的一个重要性质为:图G的连通分量的个数等于特征值0的代数重数(multiplicity of eigenvalue 0),代数重数就是L的特征值的重数。特征值0的特征子空间由连通分量的指示向量构成. 证明:当k=1时,即只有一个连通分量时,要使得hTLh=0,则每一项W*(hi-hj)^2=0都成立才可以,因为w非负,因此每个Wij不等于0的hi=hj,又因为是连通的,因此所有的hi均相等。所以h=(1,1,1,1,...1) 仅此一个特征向量 当k>1时,根据连通分量的各个点组成一个矩阵按照分块矩阵将L分块为对角分块矩阵。则求L的特征值: |λE-L|=0 由分块矩阵的行列式公式:=对角线上各个分块矩阵行列式的乘积,又因为每个分块都是一个连通分量,由前面k=1证明可知,他们的λ=0的重数都是1,所以乘起来可得λ=0的重数为k。证毕。
同样分解如下:
进一步,将上文hj,i代入上式,最终可以得到:

分解如下:
为了更进一步考虑进所有的指示向量,令H={h1,h2,⋯,hk},其中hi按列排列,由hi的定义知每个hi之间都是相互正交,即 hi∗hj=0,i≠j,且有hi∗hi=1,
可得到:

Tr表示对角线求和。
如此,便将极小化问题: min Ratio(A1,A2,...Ak) ,转化为:

那么当k取任意数字时,只需取L矩阵对应的最小那k个(毕竟倒数第二小只有1个),即可组成目标H,最后,对H做标准化处理,如下:

注意:这里通过求解前k个特征向量来构建H(n*k)矩阵,可以这么理解:每一个特征向量hj都对应一种指示,也就是一种划分,使得经过这种划分后,目标函数的值是最小的。因此他们都代表原始数据的一种特征(因为它能将数据划分开来),其实可以认为都是一种特征的提取,因此可以通过将k个特征向量组合起来,即用k个特征来描述样本的信息,这样每一行实际上就代表第i个样本在k种特征上的取值,这其实就是一种降维的思想,将样本的维度压缩为k,即使用k种特征进行描述。
之后,我们再使用K-means来指示各个样本属于的类别。
此处虽然再用到k-means,但是此处的k-means意义不同,由瑞利熵的物理意义知,最小的k个特征向量,代表着最优的k种二分类分法。用k-means在此基础上再进行聚类,仅仅算是对这k中二分类方法的应用,聚类成k类,这里也可以取特征向量数据小于k。 最简单的例子:比如想将问题分成4类,现在已经有了2种不同的分类方法,将问题各分成2类,这样最简单的分4类的方法就是在这2种不同的2分类方法之上在进行分类。
至于为什么是对H的行进行聚类,有两点原因:1.注意到H除了是能满足极 小化条件的解,还是L的特征向量,也可以理解为W的特征向量,而W则是我们构造出的图,对该图的特征向量做聚类,一方面聚类时不会丢失原图太多信息,另一方面是降维加快计算速度,而且容易发现图背后的模式。
以上是Ratiocut的内容