近10年来,machine learning也就是机器学习(一般学术界简称为ML)可以说是最热门的IT技术,同时机器学习也是一门门槛相对比较高的技术(一般算法工程师都要数学、统计学系的985、211研究生起,甚至是博士生。。。)。外行人看机器学习也就是知道大概有这么一项技术,比如深度学习,通过算法、大数据等让机器自动学习,进而做出一些智能化的判断,至于里面的具体算法是什么以及如何操作一般都是不知道的。
今年断断续续学了一段时间的机器学习,对主要几个基本算法有了一些认识和了解,并能够通过部分数据进行简单的建模。在学习的过程中,我越发感觉机器学习中的一些经典算法与管理学有很多相似之处,本文旨在让外行人了解基本的机器学习是什么,以及将自己对机器学习的一些学习心得贡献出来,进而巩固自己所学。
一、机器学习的分类
首先还是要给大家简单介绍一下机器学习的分类,如果想看标题内容的,亦或者对机器学习已经有所了解的可以跳过直接看第二部分。
机器学习主要分为四大类:有监督学习(supervised learning)、无监督学习(unsupervised learning)、半监督学习(Semi-Supervised Learning)以及强化学习(reinforcement learning)。其中,传统的机器学习只有前两种,由于我也只是初学者,对后面2种的了解也只局限于字面意思,所以只介绍前两种。
1)、有监督学习
有监督学习,简单来说就是通过历史数据来预测现在和未来。比如我手上有一堆房屋成交的交易数据,我就可以推算某一套房子的大概成交价。有监督学习可以分为2类:分类(classification)和回归(regression)。
分类如字面意思,就是分成几类。目前上海的垃圾分类,就是分类算法中的一种,比如决策树、逻辑回归等;
回归和分类不同的是,分类是离散型数据,比如有害垃圾、可回收垃圾、湿垃圾、干垃圾,四种垃圾是平级的,不能相加、相减等操作;而回归算法处理的数据都是连续性数据,比如房价,你楼层高一点,你的房价就可能会有变化。回归算法有线性回归、SVR等。
2)、无监督学习
无监督学习,就是你有一堆数据,但你没有历史数据可以用来处理这些数据,你能做的就是找出这些数据的内在关联。
无监督学习也可以分为2类:聚类(clustering)和降维(dimensionality reduction)。
聚类可以用成语“人以聚类,物以群分”来解释,比如你有一堆员工,怎么来判断哪些是好员工,哪些是差员工呢?你可能会找出一大堆的指标——出勤率、销售业绩、工作时间、技能熟练度等等,一般常规的做法是通过经验设定不同指标的系数:销售业绩最重要,设为50%,工作时间其次,设为30%。。。。然后加权求和。不能说这种方法有问题,恰恰相反在常规工作中这种方法是最直观有效的。但是因为主观决定权较大,这样操作会牺牲一些有潜力的员工。聚类算法可以自动找出最接近的n类员工(n需要你凭经验给定),往往你会很奇怪:为什么A和B会被归为一类呢?这也是无监督学习的一个通病:过程不可控,结果很奇怪,需要和经验结合起来才能应用在业务上。
“降维打击”对于一些科幻迷来说应该都不陌生,降维算法就是把一些有很多特征值的模型的维度给减下来,比如从三维降到二维,这样做的好处一是可以把一些简单模型给画出来(三维以上就很难画出来了),二是去除一些噪音特征值,使得模型能够简单化。
下图是传统机器学习中的一些主要算法,很经典的一张算法选择图。

二、几个基本机器学习算法的介绍,以及与管理学的结合
回到标题内容,我在这段时间的机器学习自学中,感觉有些算法和管理学的内容很相似,百度了一下,发现没人写过类似文章,所以就谈谈自己的感受。可能对于一些管理大拿来说比较粗浅,但是我觉得每一样技术学到高深处,必然有触类旁通的作用,所以挑几个比较简单的给大家分享一下我的观点。
1、线性回归(linear regression)和逻辑回归(logistic regression)
看过前文的都已经知道了上述两个算法的含义,也应该知道了逻辑回归并不是回归算法,而是分类算法,那为什么我要把这两个算法放在一起讲呢?这是因为它们的损失模型(loss model)很相似,最简单的模型中都用到了梯度下降(Gradient Descent)(当然逻辑回归还用到了sigmoid,这里先不谈了避免搞混)。
在谈梯度下降前,先讲一下损失函数,简单来说就是要让我所有的预测值和实际值之间差距的平方和尽可能小。比如有3个房子的价格需要预测,我根据历史数据和回归算法推算出这3个房子的价格分别是1000、1200、1500,而实际价格则是900、1200、1600,则损失是(1000-900)2+(1200-1200)2+(1500-1600)^2 ,算法的目标就是让这个数字尽可能小。那怎么让这个数字不断变小呢,就需要用到梯度下降算法,一步一步地朝数字最小的方向走,步子迈得太大会离最低点越来越远,步子太小则走的太慢。

管理方法联想: 在工作中,一般都会有一个目标,我们的期望肯定是要达成目标值,但是实际中常常会与目标值的完美达成有一定的差距,找准方向是一个要点,另外就是要掌握好自己的尺度,不能太过激进把员工的激情都榨干,也不能太过松散达不到进度要求。
2、决策树(DecisionTreeClassifier)和随机森林(random forest)

决策树是一个非常接近于我们日常思维的算法,学过编程语言或者有一些简单编程思维的都能理解决策树:先找到影响因素最大的特征值,然后进行分类,再每一个枝干上再重复进行直到分类达到预期目标。
决策树也是很多领导最喜欢的算法模型,因为决策树很简单且很容易可视化,可视化的结果就是相对其它算法来说比较容易解释(如果层级过多还是比较难解释的)。随机森林则是决策树的进阶版,一棵树的分类可能会有随机性在里面,那我就多找几棵树,再用平均数(average,用于回归)或众数(mode,用于分类)把最准确的结果给找出来。
管理方法联想:
1)、工作中还是要以大家都能明白的方式来解释,你不能要求大家的能力都是985、211,管理不是一人独挑大梁,而是要让每个人都能明白自己干什么并动起来;
2)、一条路可能会走到黑,那不妨多试几条路,阿里、腾讯等互联网企业都有AB内部竞争机制:同样是做一个产品,团队A和团队B一起开始做,到一个时间点后PK,胜者获得后续流量资源以及巨额奖金,败者则一无所有,虽然很残酷但很有效。
3、k近邻(KNN)
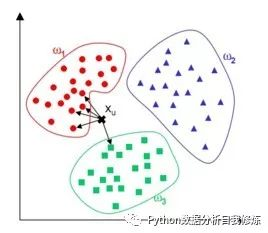
K近邻是一种分类算法,K是一个数字,代表与该点最接近的几个点,并通过投票来决定这个点属于哪一类。如上图K是5,4个点属于w1,1个点属于w3,则最终X这个点属于数量较大的w1。
管理方法联想: 在一个新员工加入后,我们一般都会根据目前岗位所缺来定制,但是却有意无意地忽略了这个员工本身的才能,而经过一段时间的培训后,因为团队氛围的关系,员工自身的才能越来越弱,与团队内其他人的相似度越来越高,短期来看的确能弥补团队人员的紧缺,但对于个人和团队的成长来说却有可能不利,所以在管理中不妨多观察一下每个人的优缺点,制定最合理的成长培育方式。
4、K均值聚类(K-Means)和DBSCAN

在机器学习的自学中,一开始我总是会把knn和kmeans搞错,误把knn当成是聚类算法,其实kmeans才是真正的聚类算法。
kmeans是一种比较简单的聚类方法,因为简单,所以运算速度很快;也因为简单,所以准确率较低且无法应用于复杂的模型:kmeans会在最初随机选几个点,然后根据欧氏距离把剩下的点一一归类于这几个点的类别中,接着重新计算中心点,再重复操作直到不再变化。如果一开始的点没找对,就可能会永远不能区分准确。
正因为kmeans的缺点,所以DBSCAN应运而生。DBSCN的全称是density-based spatial clustering of application with noise,中文解释是“具有噪声的基于密度的空间聚类应用”。看到这个名字,我的第一反应是“我靠!好难!”,其实学习后发现并不难,简单来说DBSCN就好比是传销,不断地根据你指定的最低发展下线目标(min_samples)和区域距离(eps)来进行传销,直到你的下属都已经不能再发展新的下线了,就重新找另一个点(城市)继续发展,一直重复直到所有点都被聚类好(无法被聚类的就是噪音点)。
管理方法联想: 在工作中,一般都会建立一套标准流程,不需要复杂但必须要有效,将标准流程迅速复制、推广到所有人。但是要注意的是,并不是每一套流程都适用于所有情况,如果生搬硬套,可能就会水土不服,所以还是要因地制宜、因人而异。
5、主成分分析(principal component analysis, PCA)
主成分分析是降维算法中最常用的一种,通过降维把复杂模型简单化,找出重点特征值,抓住核心点。

管理方法联想: 一个人的精力是有限的,像上图中的“我全都要”如果放在生活或工作中,可能结果就是什么都得不到。在项目管理中,十个都很平庸,还不如5个很拔尖、5个相对比较落后来得有亮点。“宁可伤其十指, 不如断其一指”,这看似是一句狠话,但是管理中有时候就是要狠一点,对别人也对自己。
6、神经网络(Neural Networks)和深度学习(Deep Learning)
其实目前我对神经网络的了解仅局限于知道它有输入层、隐藏层、输出层等,具体的算法和结构看了一段时间愣是没看懂。而深度学习则是基于神经网络的一种技术,目前商用主要应用于语音、图像识别等,比如现在比较火的无人汽车就是用了深度学习。
神经网络和深度学习最大的优点也就是它最大的缺点:人类无法理解它的内部思想是什么!因为不能理解,所以它才有成为高智能AI的潜质;但也正是因为不能理解,所以如果以后真的发展起来,人类会很难控制,当然这是好几代之后的事情了。

管理方法联想: 因为不理解,所以恐惧;因为恐惧,所以拒绝;因为拒绝,所以落后;因为落后,所以被淘汰。每一个人,不仅仅是管理者,都必须持续学习新知识,这样才会不被社会所淘汰。
