算法入门到放弃: 我为什么要研究算法?我又不是开发?我是QA而已?为啥.....
背景:
之前有遇到一个问题:自动化测试过程中,测试人员编辑的大量的用例脚本,由于测试周期较短,我们需要着重执行其中重要的脚本(非必需),也就是说对一些脚本配置权重,在执行测试的过程中,让他们执行的可能性增大,并有可能重复执行。那好,你觉得怎么处理才好?
解决:
我的拙见就是:直接上代码
#!/usr/bin/env python # -*- coding: utf-8 -*- """ @author: jayzhen @email: [email protected] @file: test_random_data @time: 2018/4/4 11:34 """ from __future__ import division import random # 这个字典:实际中就是配置文件所配置的(A是脚本类名,3是脚本执行的权重) source = {'A': 3, 'E': 10, 'C': 5, 'D': 1, 'B': 7, 'G': 15, 'W': 30, 'Z': 9} # 会将权重数据实例化成对象 class Data(object): def __init__(self): self.name = None self.num = None self.weight = None def __str__(self): return str(self.name) + "; " + str(self.weight) + '; ' + str(self.num) li = [] n = 0 # 这个循环是处理字典中的数据 for i in source: data = Data() data.name = i # 对应的key(正式是脚本的类名) data.weight = source[i] # 对应的权重 data.num = source[i] if n == 0 else source[i] + li[n - 1].num # 这个是高深之处了 li.append(data) # 将数据放到list中去 n += 1 #简单的打印一下 for i in li: print i length = len(li) # 随机取个三个脚本出来 for i in xrange(3): begin = 0 end = length - 1 tmp = random.randrange(li[length - 1].num) # 随机数 print "========"+str(tmp)+"==========" # 对list中的对象进行折半查找 for n in xrange(length): half = int((begin + end) / 2) # 如果数列是偶数就是中间偏左,奇数就是中间数了 if tmp == 0: print str(tmp) + " : "+li[0].name break if li[half].num - li[half].weight < tmp <= li[half].num: print str(tmp) + " : " + li[half].name break if begin > end: break if tmp > li[half].num: begin = half + 1 continue if tmp <= li[half].num - li[half].weight: end = half - 1 continue
执行结果:
脚本名称:A; 权重:3; 权重位:3 脚本名称:C; 权重:5; 权重位:8 脚本名称:B; 权重:7; 权重位:15 脚本名称:E; 权重:10; 权重位:25 脚本名称:D; 权重:1; 权重位:26 脚本名称:G; 权重:15; 权重位:41 脚本名称:W; 权重:30; 权重位:71 脚本名称:Z; 权重:9; 权重位:80 ========55========== 55 : W ========26========== 26 : D ========30========== 30 : G
原理(不想打字,手绘图,请谅解)
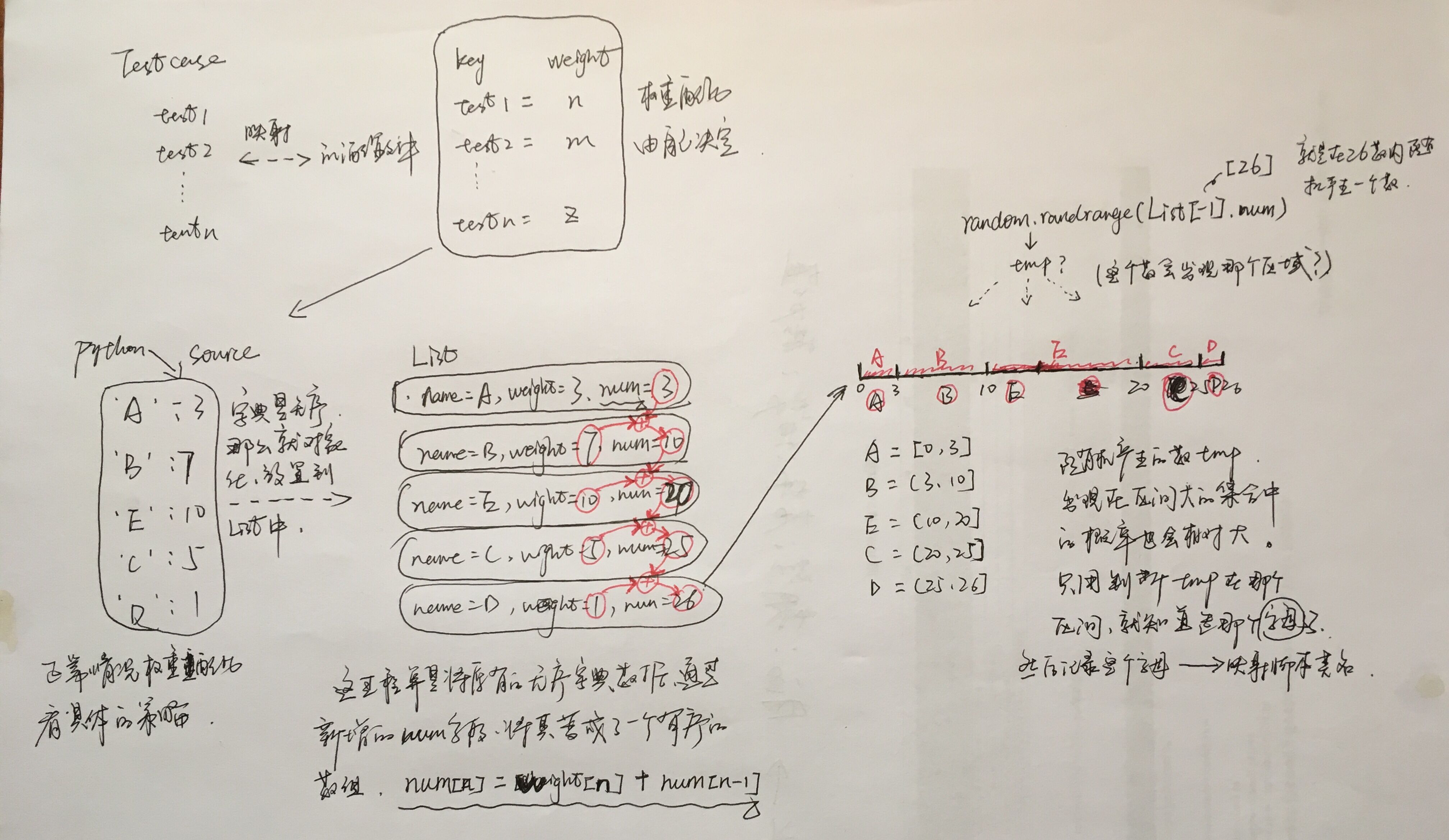
总结:
这中随机方案最大的优点就是简单,但不是我想出来的,我也记不起来是在哪看到的了。缺点就是算法有待优化,当前得到的随机结果,可能并不是实际工作过程中需要的,因为一组数据数据有可能出现在同一集合(比如:E),这样的话就有问题了,脚本不能重复执行多次啊,所以业务性算法要有独特的角度去完善。在后续的多机运行selenium脚本的时候,会在继续优化这个算法。