目录
一、XPath
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有想要定位的节点都可以用 XPath 来选择。
官方文档:https://www.w3.org/TR/xpath/
二、XPath 常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
这里列出了 XPath 的常用匹配规则,示例如下:
//title[@lang='eng']
这是一个 XPath 规则,代表的是选择所有名称为 title,同时属性 lang 的值为 eng 的节点,后面会通过 Python 的 lxml 库,利用 XPath 进行 HTML 的解析。
三、在谷歌浏览器安装XPath插件
在谷歌浏览器安装XPath插件需要安装Google访问助手。下载地址:http://www.zdfans.com/html/27204.html
下载完之后解压,在google浏览器点击设置,更多工具,扩展程序

点击开发者模式,将刚才解压的文件直接拖到这个界面,浏览器会自动安装。我已经安装了,安装好之后第一个就是。

右上角将会显示图标

点击Chrome商店

在搜索店内应用搜索并安装三个插件,分别是
1.Xpath helper
2.JsonView
3.SwitchyOmega


安装完后如图所示:
四、Python爬虫常用插件
1.google-access-helper:谷歌浏览器助手,可访问谷歌商店和使用Google搜索
2.Xpath helper:获取Html元素的Xpath路径,打开/关闭:ctrl+shift+X
3.JsonView:格式化输出json数据
4.SwitchyOmega:谷歌浏览器中的代理管理扩展程序
五、使用Xpath解析
完成了前面的操作后,我们来看看Xpath的简单使用,我们拿一个网站来做测试。
测试页面为猫眼电影网:https://maoyan.com/board
进入到页面,右键打开检查,我们观察到电影名是在<div class=""movie-item-info>下的p标签下的a链接的内容。所以我们可以写出Xpath的表达式:
//div[@class="movie-item-info"]/p/a
我们在按ctrl+shift+x打开Xpath匹配,Query下输入//div[@class="movie-item-info"]/p/a。Result里面输出结果。

以上是Xpath的第一次尝试,相信读者有点懵逼,没关系,下面来讲Xpath的几个经典示例。
六、Xpath匹配示例
1.查看所有的标签(如p、a、li标签等)
在一个Html页面中,如果要匹配所有的标签,可以输入://标签名
打开猫眼电影:https://maoyan.com/board
以p标签为例,//p将会匹配所有的p标签下的内容。//代表从当前节点选取子孙节点,而当前结点就是根节点,所以//p将会匹配根节点下所有p节点。读者可以尝试其他标签。

2.查看某标签下的所有标签(如p下的a标签)
如图所示,根据我的分析,我发现电影名都在p标签下的a标签里,所以我可以通过//p/a来匹配。我们已经知道了//p的含义,而再加一个/a代表在//p的结果下再找筛选a标签的内容
xpath表达式为://p//a

3.带属性值的匹配
如果我们想匹配特定的一个内容,我们可以假如属性值。属性值的格式为:标签名[@属性=“属性值”],如图所示。如果我们想匹配title=“我和我的祖国”的电影名,xpath格式为://p/a[@title="我和我的祖国"]


以上的方式太局限了,经过分析,我们发下p标签上面一级是<div class="movie-item-info">。而div的下的p标签的class决定了输出什么类容。
如<p class="name"> 输出电影名

<p class="start">输出演员名单

4.查看某标签下的第n个标签
我们也可以通过[n]来决定要输出第几个标签的内容,不加[n]将输出所有内容。

p[1]输出电影名:

p[2]输出演员表

5.输出某标签的属性值
如果我们想拿到a标签下的href属性值,按照常规思路可以写出xpath://div[@class="movie-item-info"]/p/a
但是这样只会拿到a标签下的内容,而不会拿到属性值。正确写法是为://div[@class="movie-item-info"]/p/a/@href
在a标签后在@属性名
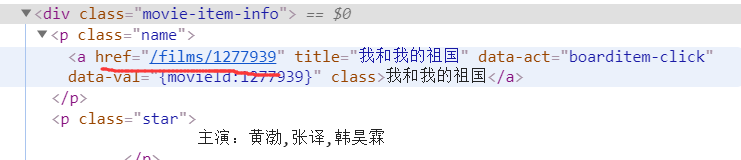
如下:

6.xpath常用函数
1.contains():匹配属性值中包含某些字符串的节点
如下面的例子,这里的id并不一样,那么我们获取的方式可以通过://li[contains(@id,"car_")]
<li id="car_bw" >宝马</li>
<li id="car_byd" >比亚迪</li>
2.text():获取标签里的内容,作为字符串输出
7.总结
//代表从根节点向下找
/代表从当前结点往下找
比如//p匹配到根下的所有p标签,//p/a在从p标签下找a标签
@的使用场景 :
1)属性值作为条件
//p/a[@title="我和我的祖国"]
2)直接获取属性值
//div[@class="movie-item-info"]/p/a/@href
获取文本内容需要加text()
比如//p/a,虽然会输出a标签下的文本内容,但是这个表达式是不严谨的,如果是想抓取a下的内容,最好写成://p/a/text()
element还是string:
不加text()的情况或者不以@属性名结尾的情况下,返回的结果都是element,element是元素节点,如果你在python想将抓取的结果作为String输出,那么加上text()或@属性名
七、链家二手房Python爬虫程序
1.需求分析
打开链家二手房首页:https://sz.lianjia.com/ershoufang/
我们将要提取的信息有房名,地址,详细信息,总价与单价。

以下是链家二手房的第一页和第二页,分析发现一共100页(我选择是深圳二手房,可能不同地区页码数不一致)

![]()
结论:
1.提取信息为:房名,地址,详细信息,总价与单价。
2.URl为:https://sz.lianjia.com/ershoufang/pg页码数/(页码数大于0小于101)
2.Xpath分析
整个程序的核心在与Xpath分析。进入检查页面,我们发现所有信息都在ul标签下的li标签下。下面我们细节分析li标签

li标签下有我们想要的房源信息,都在div之下,我们可以通过class属性值来获取内容。

查看网页源码,经过观察,我们发现class属性值是变动的,当查看过这个房源信息后,class属性值将变为以下内容。分析原因,可能是因为鼠标滚动时候,触发JS动作,Js将class属性改变,目的是标记以阅读。所以我们以网页源码的class属性为准。

下面开始分析Xpath如何写,第一步肯定是要获得当前页面下所有的li标签下的内容,我们发现ul的class和li的class都是一致的,所以Xpath://ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]

下面来验证结果:

获取到单页面下的所有房源信息后,进一步提取房名,地址,详细信息,房价。可以在房源信息的基础上进一步提取,如提取房名://ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]//div[@class="positionInfo"]/a/text()
虽然这样写并没有错,但是看上去颇为复杂,我们在python程序里不这么写。我们可以在房源信息的Xpath基础上,再提取房名信息,所以Xpath可以简写为:.//div[@class="positionInfo"]/a/text()
注意点号不能丢,而且是双斜杠。当前结点的根节点是li,所以.代表的是li

以下分析相对就容易很多了,我直接写结果
1)所有房源信息
//ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]
2)房名
.//div[@class="positionInfo"]/a/text()
3)地址
.//div[@class="positionInfo"]/a[2]/text()
4)详细信息
.//div[@class="houseInfo"]/text()
5)总价
.//div[@class="totalPrice"]/text()
6)单价
.//div[@class="unitPrice"]/text()
提示:看到下图,这是房子的详细信息,有的人可能会这么写Xpath:.//div[@class="houseInfo"]/span/text()
加入了一个span标签,其实在这里是多余的,因为div下面的所有内容都在span标签下,所以直接获取div下的所有内容即可。

3.Python对Xpath的支持
python要使用Xpath,需要安装lxml模块,如果你使用的python编辑器,导入方式如下,在Terminal下输入python -m pip install lxml即可。如果是Linux系统,则在命令行输入sudo pip install lxml(提示:如果pip导入失败,则将pip改成pip3再次尝试)

4.Xpath的使用方式
1) 导入模块
如果你下载的是4.5或4.5以上的版本,导入模块方式为:from lxml import html
否则为:from lxml import etree
2)构建Xpath
首先我们要获取一个html的响应文件,我使用的requests模块拿到的
rep=requests.get(url="https://sz.lianjia.com/ershoufang/pg1/",headers={"User-Aget":"Mozilla/5.0").text拿到之后,我们要构建Xpath,方式如下:
4.5或以上:p=html.etree.HTML(rep)
4.5一下:p=etree.HTML(rep)
3)获取匹配内容
构建完后,我们根据你写的xpath表达式就可以拿到匹配的内容,调用xpath()方法,返回类容为列表。
lists=p.xpath('//ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]')也可以这么写:
xpath_regex='//ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]'
lists=p.xpath(regex)
5.编写程序
程序如下,程序内包含注释,阅读起来比较容易。一共3个函数,get_html()核心函数,用于输出房源信息。run()函数为入口,调用这个函数来启动程序。__init__()初始化函数。
from UserAgent import agentPools
from lxml import html
from urllib import parse
import requests
import re
import random
import time
class LianjiaSpider(object):
#初始化url
def __init__(self):
self.url = "https://sz.lianjia.com/ershoufang/pg{}/"
#核心函数
def get_heml(self,url):
rep=requests.get(url,headers={"User-Aget":agentPools[random.randint(0,2)]}).text
#开始解析,把lxml+Xpath表达式,将结果存入li_lists
p=html.etree.HTML(rep)
#li_lists是xpath匹配内容的结果集,保存了符合规则的信息
li_lists=p.xpath('//ul[@class="sellListContent"]/li[@class="clear LOGVIEWDATA LOGCLICKDATA"]')
items={}
for li in li_lists:
#房名xpath,要判断是否为空,因为后续可能会做数据持久化处理,比如存入数据库
li_name=li.xpath('.//div[@class="positionInfo"]/a/text()')
if li_name:
items["name"]=li_name[0]
else:
items["name"] = None
# 地址xpath
li_address = li.xpath('.//div[@class="positionInfo"]/a[2]/text()')
if li_address:
items["address"] = li_address[0]
else:
items["address"] = None
# 房子详细信息xpath
li_info=li.xpath('.//div[@class="houseInfo"]/text()')
if li_info:
items["info"] = li_info[0]
else:
items["info"] = None
# 房子总价
li_total = li.xpath('.//div[@class="totalPrice"]/text()')
if li_total:
items["total"] = li_total[0]
else:
items["total"] = None
li_unitPrice = li.xpath('.//div[@class="totalPrice"]/text()')
# 房子单价
if li_total:
items["unitPrice"] = li_unitPrice[0]
else:
items["unitPrice"] = None
# 打印结果
print(items)
#入口函数
def run(self):
#爬1到50页的房源信息
for pg in range(1,50):
#将页码数嵌入url中
url=self.url.format(pg)
#调用主方法
self.get_heml(url)
#设置间隔,休眠0或1秒,目的是反爬
time.sleep(random.randint(0,1))
if __name__=="__main__":
spider=LianjiaSpider()
spider.run()输出结果:

