一、计算机的编码
计算机只能识别0和1,是如下所示:

从输入内容到计算机转变成0与1的代码就是编码,计算机内部有一个编码表进行一一对应。
二、二进制
用来存放一个0或者1的位置,就是计算机中最小的储存单位,叫做【位】,外国名字叫【bit】,也叫做【比特】。我们规定8个比特构成一个【字节】(byte),字节是计算机里最常用的单位。


- 我们千兆宽带,其实说的是以比特每秒位单位,1000M就是 1000Mbit/s。
- 我们下载速度是以字节每秒位单位显示的,1byte = 8bit。
- 那么,1000M bit = 125M byte。
- 也就是说千兆宽带,每秒下载速度最多125M。那我们的百兆宽带,下载速度也就只有十几兆了。
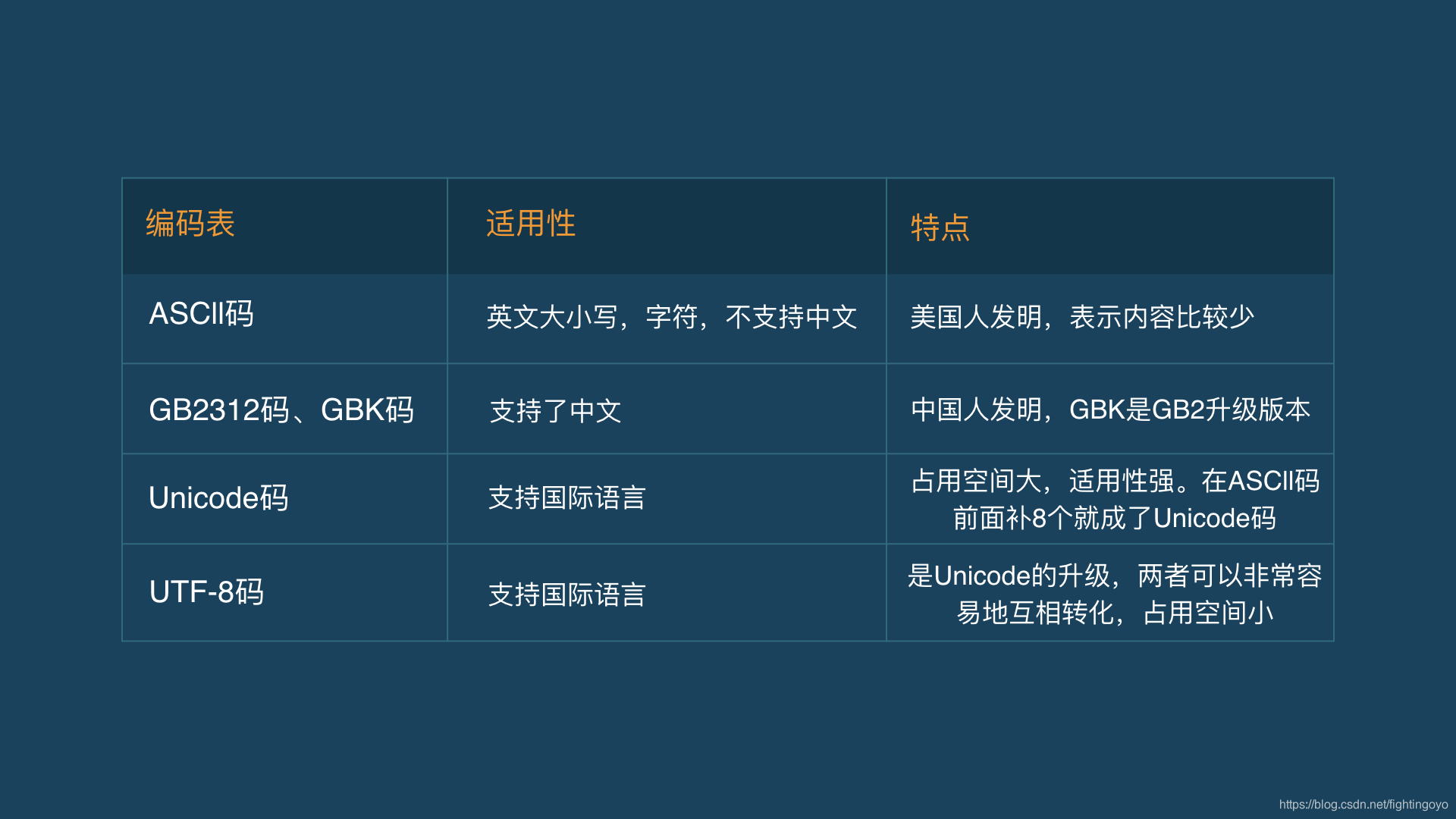
三、编码表
- 计算机开始发明的时候,用来解决数字计算问题。但是后来发现,只用二进制解决问题还是有限。
- 计算机这种东西最早由老外发明,外国人使用的英语只有26个字母,再加上标点、数字和一些符号也不会太多,老外搞出来一个东西叫做ASCII码,这个比二进制高级了一些。ASCII码组合出的256种状态,至此一个字节就使用满了。
- 后来,计算机传入中国,汉字千千万,256种状态远远不够。科学家就重新编写了一张编码表,叫做GB2312(word中有这种编码方式),它使用2个字节16个比特位,来表示绝大多数(65535)个汉字。后来,为了显示更多的汉字,又研究出一套编码,GBK编码。
美国人有ASCII码,中国人有GB2312/GBK编码,那欧洲人、阿拉伯人也有他们自己的编码方式,这就导致了乱码的产生。
- Unicode应运而生。Unicode把所有语言都统一到一套编码里,可以容纳100多万个符号,这样就不会再有乱码问题了。但是由于把所有语言都统一到一套编码里中,就造成Unicode码越来越庞大。比如英文A,之前可以用00010001表示,但是到了Unicode码中,必须使用00000000 00010001来表示。太长了,太麻烦了。
- 科学家们又针对Unicode码研究出了一种可变长度字符编码,叫做UTF-8(8-bit Unicode Transformation Format),它可以根据不同的符号来变化字节长度。
四、编码encode()与解码decode()
- 编码encode就是把人类语言转成计算机语言。
- 解码decode就是把计算机语言转成人类语言。

print('刘德华'.encode('gbk'))
print('郭富城'.encode('utf-8'))
print(b'\xc1\xf5\xb5\xc2\xbb\xaa'.decode('gbk'))
print(b'\xe9\x83\xad\xe5\xaf\x8c\xe5\x9f\x8e'.decode('utf-8'))
# 输出结果如下:
b'\xc1\xf5\xb5\xc2\xbb\xaa'
b'\xe9\x83\xad\xe5\xaf\x8c\xe5\x9f\x8e'
刘德华
郭富城
- 这里的计算机语言有一个相同之处,就是最前面都有一个字母‘b’,这是代表它是bytes(字节)类型的数据。
print(type('刘德华'))
print(type(b'\xc1\xf5\xb5\xc2\xbb\xaa'))
print(type(b'\xe9\x83\xad\xe5\xaf\x8c\xe5\x9f\x8e'))
# 输出结果:、
<class 'str'>
<class 'bytes'>
<class 'bytes'>
- 计算机的编码,就是把字符串类型的数据,转换成bytes类型的数据。
- 计算机的解码,就是把bytes类型的数据,转换成字符串类型的数据。
- 编码时用什么样的编码表,解码的时候就用什么样的编码表。
五、文件读写
在Python,可以使用Python操作计算机中的文件,可以读取写入文本内容、音频、表格、邮件等内容。
- 使用open()时,在前面加r和不加r是有区别的。
- 加r是防止字符转义的,如果路径中出现’\t’的话 不加r的话\t就会被转义 而加了’r’之后’\t’就能保留原有的样子。
- 在字符串赋值的时候 前面加’r’也可以防止字符串不被转义。
s = r't\nt'
print(s)
# 输出:
t\nt
s = 't\nt'
print(s)
# 输出:
t
t
1、读取文件
总共分三步:
- 打开文件
- 读取文件
- 关闭文件
# text.txt中的内容为“愿你出走半生归来仍是少年”,同时与py文件处于同个文件夹中
myfile = open(r'test.txt','r')
myfilecontent = myfile.read()
print(myfilecontent)
myfile.close()
输出结果:
$python readfile.py
愿你出走半生归来仍是少年
$
- 'test.txt’是需要读取文件的文件名,在这里, readfile.py文件与test.txt文件需要放在同一文件夹内。
2、写入文件
文件写入也分三步:
- 打开文件
- 写文件
- 关闭文件
# text.txt中的内容为“愿你出走半生归来仍是少年”,同时与py文件处于同个文件夹中
myfile = open(r'test.rtf','w')
myfile.write('我要从你的全世界路过,路过就不回来了,哈哈哈!')
myfile.close()
# 修改后的文件内容,打开后就是写入后的内容:
我要从你的全世界路过,路过就不回来了,哈哈哈!
- 因为‘w’是写入模式,会直接清空test1.txt文件中的内容,重新写入。 如果你不想清空原来内容, 就要使用‘a’模式,意为追加。
myfile = open(r'test.rtf','a')
myfile.write('路过了,还是回来了,看不得你孤单……')
myfile.close()
# 修改后的内容为,打开文件后为写入后的内容:
我要从你的全世界路过,路过就不回来了,哈哈哈!路过了,还是回来了,看不得你孤单……
- 如果我们想写入的数据不是文本,而是图片怎么办?

- 里面还有‘wb’模式, 它的意思是以二进制的方式打开一个文件用于写入。
- 图片、音频都是以二进制形式存在,所以使用wb模式就好了。
3、切记关闭文件
- 有时候在打开文件,读写结束后,忘记关闭文件。但是不关闭文件就会占用电脑内存,使得电脑越来越慢,怎么解决呢?
- 可以使用with方法
with open(r'test.rtf','a') as myfile:
myfile.write('想了想,我还是要出走。')
# 修改后的内容为,打开文件后为写入后的内容:
我要从你的全世界路过,路过就不回来了,哈哈哈!路过了,还是回来了,看不得你孤单……想了想,我还是要出走。
六、练习
- 将注释中的bytes内容解码出来,并添加到test.rtf文件中。
# b'\xe7\x9f\xa5\xe8\xa1\x8c\xe5\x90\x88\xe4\xb8\x80'
print(b'\xe7\x9f\xa5\xe8\xa1\x8c\xe5\x90\x88\xe4\xb8\x80'.decode('utf-8'))
with open(r'test.rtf','w') as myfile:
myfile.write('知行合一')
# 输出结果:
知行合一
# 修改后的内容已经在test.rtf中体现了
- 在Pthon文件中,可以接收用户所输入的任何内容,在这内容前面加上“您输入的是:”; 之后将所有的内容写入到test.rtf文件中。
def content():
shuru = input('请输入任何内容:')
shuru2 = '您输入的是:' +'"'+ shuru+'"'
return shuru2
with open(r'test.rtf', 'w') as myfile:
myfile.write(content())
# 输入的内容全部写入到test.rtf文件中了
