题里给的下载链接是这个,打开是下图

可以看到一共8772个站点的数据,每个下载需要点击两次,一个上面的Go,一个下图的download

全点下来,这不是要累死 ,于是我想到了亲爱的python
点击download后,可以看到真正的下载链接
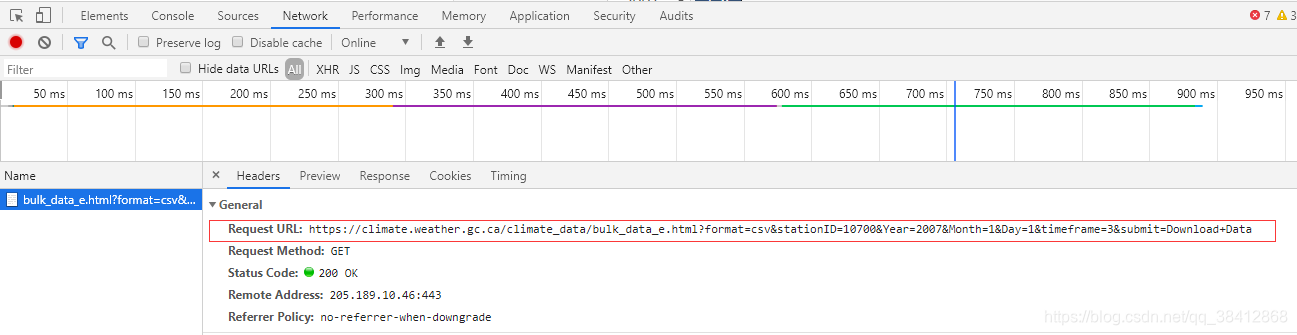
而且经过尝试,Year和Month都不是关键参数,不同的年和月,下载下来的文件是一样的,所以关键就在stationID上,我们只要把8772个站点的stationID搞下来,循环就完事了
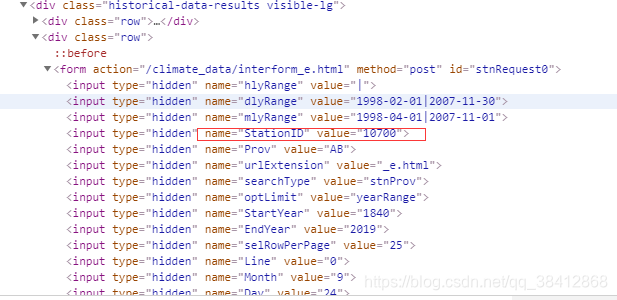
这个就是我们想要的,于是简单粗暴,正则匹配,同时需要翻页,因为100个一页,我们有8772个站点
# -*- coding: utf-8 -*-
from urllib import request
import os
import json
import time
import requests
import re
import io
import sys
import json
#正则匹配出所有站点id
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码
url="http://climate.weather.gc.ca/historical_data/search_historic_data_stations_e.html?searchType=stnProv&timeframe=1&lstProvince=&optLimit=yearRange&StartYear=1840&EndYear=2019&Year=2019&Month=9&Day=19&selRowPerPage=100&txtCentralLatMin=0&txtCentralLatSec=0&txtCentralLongMin=0&txtCentralLongSec=0&startRow="
def get_currentpage_list(url,startRow):
realurl=url+str(startRow)
response = requests.get(realurl)
text_data=response.text
pattern=re.compile(r'(?<=name="StationID" value=")((?:(?!name="StationID" value=").)*?)(?="/>)')
stationid_list = pattern.findall(text_data)
return stationid_list
startRow=1
count=1
all_stationid_list=[]
while True:
if startRow>8800:
break
all_stationid_list+=get_currentpage_list(url,startRow)
print("第%d页读取完毕"%count)
count+=1
startRow+=100
all_stationid_list=sorted(list(set(all_stationid_list)))
json.dump(all_stationid_list,open('stationid_list','w+'))
print("站点id检索完毕!")有了id后就可以构造下载链接并写入文件了:
#根据站点id构造网址下载站点数据
print("开始下载数据:")
all_stationid_list=json.load(open('stationid_list','r+'))
# all_stationid_list=all_stationid_list[:4001]
url="http://climate.weather.gc.ca/climate_data/bulk_data_e.html?format=csv&stationID="
header = {
"Host": "climate.weather.gc.ca",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36",
"Cookie": "PHPSESSID=upnh5jfmeuh08i5gdc46cfcpj7; jsenabled=0"
}
def download_little_file(url,header,to_path):
req = request.Request(url=url, headers=header)
response = request.urlopen(req)
f = open(to_path,'wb')
f.write(response.read())
f.close()
response.close()
count=1
for id in all_stationid_list:
if count%6==0:
time.sleep(3.3)
filename=os.path.join('datasets',id+'.csv')
real_url = url + id + "&Year=1840&Month=1&Day=1&timeframe=3&submit=Download+Data"
try:
download_little_file(real_url,header,filename)
except:
pass
print("station:%d is finished"%count)
count+=1
print("所有站点数据下载完成!")以上就是加拿大8772个站点数据获取思路和代码,献给曾经被下载数据所折磨的E题小伙伴门,虽然已经晚了hhh
汇总一下:
# -*- coding: utf-8 -*-
from urllib import request
import os
import json
import time
import requests
import re
import io
import sys
import json
#正则匹配出所有站点id
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码
url="http://climate.weather.gc.ca/historical_data/search_historic_data_stations_e.html?searchType=stnProv&timeframe=1&lstProvince=&optLimit=yearRange&StartYear=1840&EndYear=2019&Year=2019&Month=9&Day=19&selRowPerPage=100&txtCentralLatMin=0&txtCentralLatSec=0&txtCentralLongMin=0&txtCentralLongSec=0&startRow="
def get_currentpage_list(url,startRow):
realurl=url+str(startRow)
response = requests.get(realurl)
text_data=response.text
pattern=re.compile(r'(?<=name="StationID" value=")((?:(?!name="StationID" value=").)*?)(?="/>)')
stationid_list = pattern.findall(text_data)
return stationid_list
startRow=1
count=1
all_stationid_list=[]
while True:
if startRow>8800:
break
all_stationid_list+=get_currentpage_list(url,startRow)
print("第%d页读取完毕"%count)
count+=1
startRow+=100
all_stationid_list=sorted(list(set(all_stationid_list)))
json.dump(all_stationid_list,open('stationid_list','w+'))
print("站点id检索完毕!")
#根据站点id构造网址下载站点数据
print("开始下载数据:")
all_stationid_list=json.load(open('stationid_list','r+'))
# all_stationid_list=all_stationid_list[:4001]
url="http://climate.weather.gc.ca/climate_data/bulk_data_e.html?format=csv&stationID="
header = {
"Host": "climate.weather.gc.ca",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36",
"Cookie": "PHPSESSID=upnh5jfmeuh08i5gdc46cfcpj7; jsenabled=0"
}
def download_little_file(url,header,to_path):
req = request.Request(url=url, headers=header)
response = request.urlopen(req)
f = open(to_path,'wb')
f.write(response.read())
f.close()
response.close()
count=1
for id in all_stationid_list:
if count%6==0:
time.sleep(3.3)
filename=os.path.join('datasets',id+'.csv')
real_url = url + id + "&Year=1840&Month=1&Day=1&timeframe=3&submit=Download+Data"
try:
download_little_file(real_url,header,filename)
except:
pass
print("station:%d is finished"%count)
count+=1
print("所有站点数据下载完成!")