本文是学习博客pandas系列学习(三):DataFrame过程中的笔记,博主写的很详细
推荐先看他的这两篇:pandas系列学习(一):pandas入门
1.数据类型
pandas中数据类型主要有两类:Series和DataFrame,Series是单列数据,DataFrame为多列数据
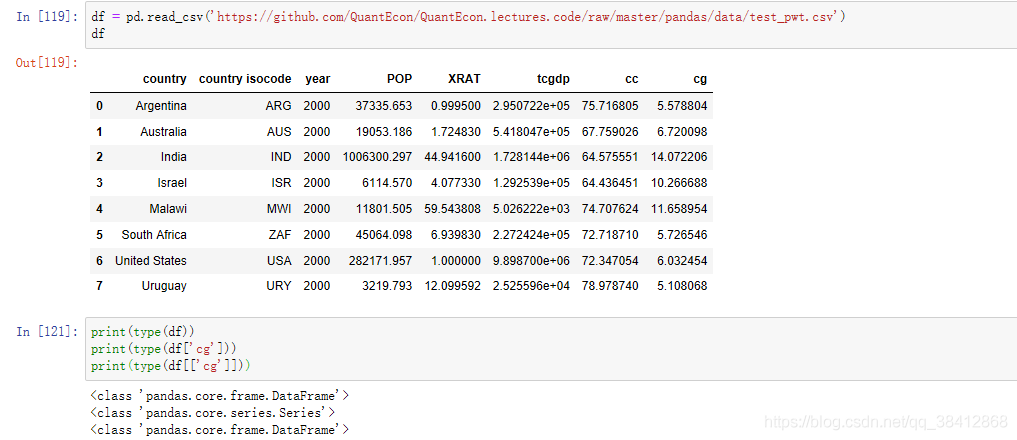
可以看到,选择DataFrame的一列,即为Series
df['cg']#取单列的方式,故结果为Series
df[['cg']]#一般里面是列表是形式,是为取多列,故结果仍为DataFrame2.操作数据
2.1选择行
- 使用类似于列表的切片

- 使用iloc属性,基于数字索引(次序)选择,行和列都是用切片形式或者列表形式

- 使用loc属性,基于行标签选择,列需要表示为列名组成的列表或者:(代表全部列)

注意,此时行是2:5时,包含了索引为5的行
- 使用逻辑条件筛选特定行

2.2选择列
- 使用点符号和列名访问
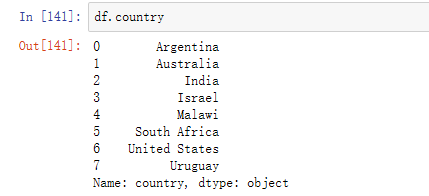
- 使用['列名']访问,也可以放入多个列名(放入一个列表)

放入多个列名需要以列表形式传入,返回的结果是DataFrame ,单个列名返回的是Series
- 使用行选择中讲过的iloc属性和loc属性
2.3删除行和列
删除列:



删除行:


inplace 参数可用于更改 DataFrame 而无需重新分配,在上述操作中若后面加上inplace=True,则原df会发生改变

2.4重命名列
1.将dict传入rename函数,格式为 {'old_name': 'new__name',...},用于修改指定列名

2.将可以改变名称的函数传入rename函数作为参数columns的值,用统一的规则修改所有列名


3.导出和保存数据
前面做了各种修改操作,总需要把数据从内存中放到硬盘里保存下来
1.to_csv 函数将 DataFrame 写入 csv 文件
data.to_csv("output.csv", index=False, encoding='utf8')#index=False表示不保存前面0,1,2,3,4这种索引当索引不是类似于行标的时候,还是有必要保存下来的
2.to_excel 函数将 DataFrame 写入 excel 文件
data.to_excel("output.xlsx",sheet_name="Sheet 1", index=False)#index=False表示不保存前面0,1,2,3,4这种索引to_excel工作需要python安装有xlsxwriter库
