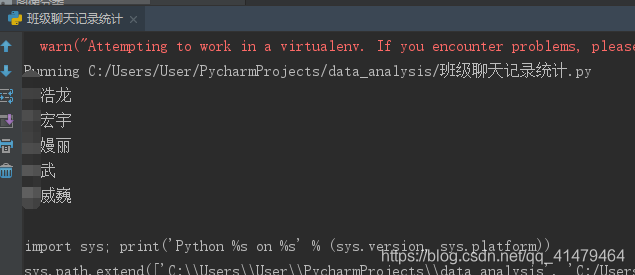
首先介绍一下此次需求:
因为班级在看团日活动,每天统计谁个发图片了谁个没法,然后对着名单一点一点找!当时萌生想法,能不能导出那一阶段的聊天记录,然后拿到班级所有人的名单,然后进行字符串匹配不就可以了。
我想教大家如何导入想要阶段的数据:
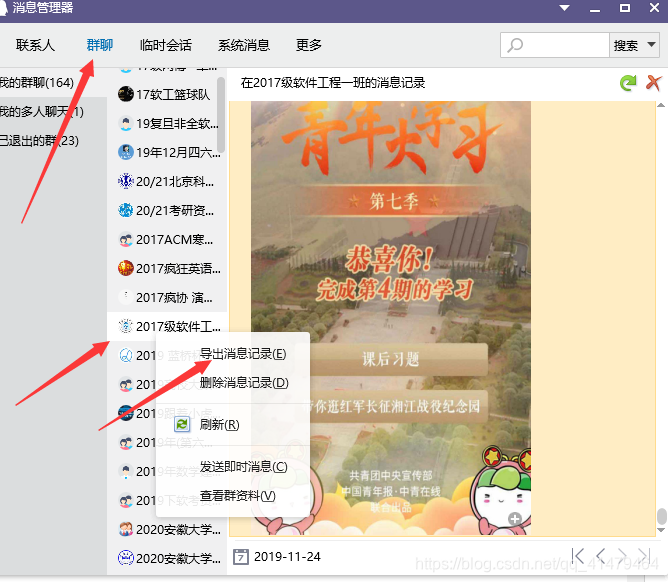
打开qq,找到消息管理:

然后找到对应好友或者群,右击鼠标:导出txt的文件:

这个时候导出的是全部时间的聊天记录:现在我们需要手动复制一下所需要的:
用鼠标选中第一行:

然后ctrl+shift 鼠标点击最后一个所需的:这样就可以直接得到想要阶段的数据了!

这里面最好用notepad++因为乱码可以直接转码!
接下来就是直接弄一份班级姓名的名单了,这个期末考试成绩直接复制一列姓名就可以!
开始我想了两个方法:
方法一:
一个是导入聊天记录时候,因为一行带有人名,一行带有图片,这时候我需要处理成一行,也就是既带图片既有姓名的。
导出的聊天记录格式:

首先去除多余的空行:
def clearBlankLine():
file1 = open('2.txt', 'r', encoding='utf-8') # 要去掉空行的文件
file2 = open('4.txt', 'w', encoding='utf-8') # 生成没有空行的文件
try:
for line in file1.readlines():
if line == '\n':
line = line.strip("\n")
file2.write(line)
finally:
file1.close()
file2.close()
if __name__ == '__main__':
clearBlankLine()再将生成后的目标文件用作处理成一行:
def fenhang(infile,outfile):
infopen = open(infile,'r',encoding='utf-8')
outopen = open(outfile,'w',encoding='utf-8')
lines = infopen.readlines()
i = 1
for line in lines:
line = line.strip("\n")
if i % 2 == 0:
outopen.write(line)
else:
outopen.write(line)
if i%2==0:
outopen.write("\n")
i += 1
infopen.close()
outopen.close()
fenhang("4.txt","3.txt")处理后的格式如下:

最后进行字符串匹配,这个方法太麻烦了,最后匹配算法也不想写了!前面预处理麻烦!
方法二、
接下来好的都在最后!最好的方法:直接用字符串匹配即可!开始没有想到!这个方法不需要像之前这么麻烦进行数据的空白行处理,变成一行既有图片也有人名的。
1.直接拿到你得到的想要阶段数据也就是聊天记录:

第二个就是你的班级人名的名单:
import re #使用正则库
# 打开文件
fo = open("匹配人名.txt", "r",encoding='utf-8') # 需要匹配的人名
co = open("2.txt", "r",encoding='utf-8') #导入的聊天记录文件
target = co.readlines() #读取所有world文件中的行
for line in fo.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
match_Result = re.search(line, "%s" % target, re.M | re.I) #使用正则表达式来获取相同的字符串
#正则匹配开始,使用search可以将全部符合条件的字符集都找出来
if not match_Result:
print(line) #输出不在此次名单的人名
# 关闭文件
fo.close()
co.close()最后不在名单中的人名也就打印出来了!