Get your hands dirty
一、入门案例 1
理解网页结构:
<p> <div> <h1> 的结构是 HTML 语义标签
class 和 style 中是控制样式的 CSS 代码 e.g.<div style="color: red">
按钮中的 onclick,是与用户交互的 Javascript 代码 e.g. <button class="button is-primary" onclick="alert('你好')">点这里</button>
查看网页代码:
鼠标移动到在当前页面的任意内容上,点击 「检查」(或者 「检查元素」 「审查元素」 「查看元素」) 按钮,在新弹出的窗口中就能够看到这段内容对应的代码。
使用 Python 下载网页代码:
python --version (3.6以上)
pip install requests_html
提取网页中所需内容:
css选择器:
先查看一段内容的代码,在代码上点击右键,选择 Copy -> Copy Selector (或者 Copy CSS Selector、复制 CSS 选择器),就能将这段内容对应的 CSS 选择器复制到剪贴板。
下载requests_html库:
用镜像他不香吗?
前:Timeout error 20kb速度
解决:https://blog.csdn.net/weixin_30325487/article/details/95734595
后:飞起
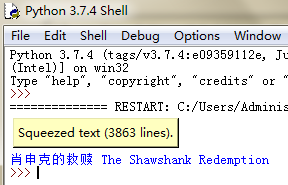
Q: 提取电影名称
新建carwler.py文件
----------------------------
from requests_html import HTMLSession
session=HTMLSession()
r=session.get(''https://movie.douban.com/subject/1292052/'')
print(r.text)
title=r.html.find(' #content > h1 > span:nth-child(1) ',first=True)
print(title.text)
-----------------------------------
-----------------------------------------------
失败了吗?如果你进行了额外的练习,会发现很多内容无法正确提取出来。
需要记住的是,CSS 选择器只是多种内容提取方法中的一种,
没有一种方法能够解决所有问题,
编写一个真实的爬虫,还需要使用更多工具 + 你的智慧。
二、案例 2 多网——自动化
链接相似 的网页通常具有相似的外观。
外观相似 的网页通常具有相似的网页结构。
这两个相似性是爬虫能够从一系列网站中自动化提取数据的重要基础。
逻辑:下载网页 - 网站服务器 - 提取信息
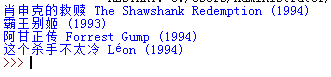
Q:多个电影名称和日期
-----------------------------------------------------------
from requests_html import HTMLSession
session=HTMLSession()
links=['https://movie.douban.com/subject/1292052/',\
'https://movie.douban.com/subject/1291546/', \
'https://movie.douban.com/subject/1292720/',\
'https://movie.douban.com/subject/1295644/']
for link in links:
r=session.get(link)
title=r.html.find(' #content > h1 > span:nth-child(1) ',first=True)
year = r.html.find('#content > h1 > span.year',first=True)
print(title.text,year.text)
--------------------------------------------------------------------------
Q:新浪微博股票日值
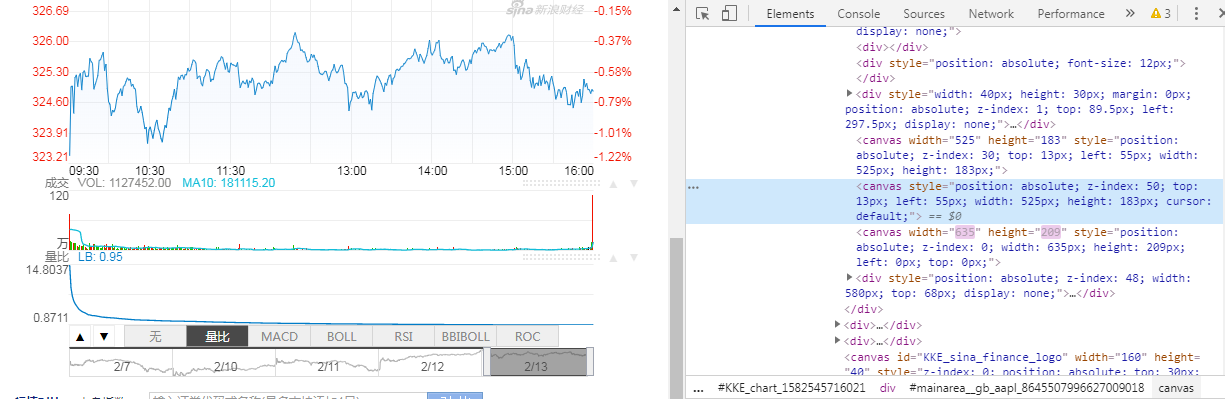
No connection adapters were found.
事实上,很多网站使用 Javascript 代码来生成网页内容,你的爬虫需要正确解析 Javascript 才能获得你所看到的页面。
-----------------------------------
解决:添加渲染器
r=session.get(link).render()
----------------------------------------------------------------------
获取:第一次需要下载chromium
1.SSL报错 -- 不知道怎么解决:Max retries exceeded with url: /chromium-browser-snapshots/Win/575458/chrome-win32.zip
2.手动下载
参考“https://www.cnblogs.com/SkyOceanchen/p/12168282.html”
https://www.cnblogs.com/forcee/p/11340892.html
找路径:
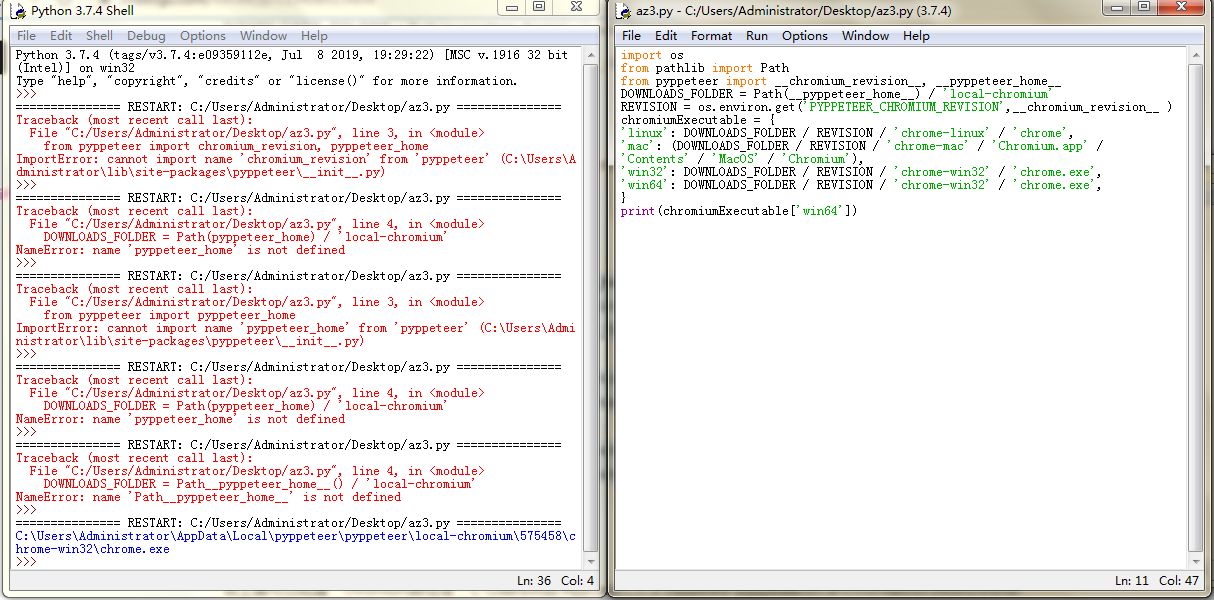
试用2次:
PageError: Protocol Error: Connectoin Closed. Most likely the page has been closed.
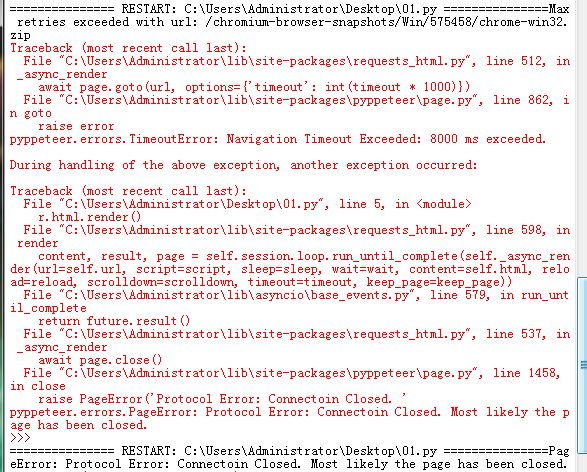
解决:把360给关了。

三、写入文档
CSV 格式
Python 提供了标准库 csv 来读写 csv 数据。
通常用来存储简单的数据,表格类型数据首选。
CSV 数据可以使用微软 Office Excel 软件打开。非常多的爬虫数据集都使用 CSV 作为存储格式。
----------------------------------------------------------------
from requests_html import HTMLSession
import csv
session = HTMLSession()
#打开文件,写标题
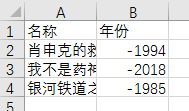
file = open('movies.csv', 'w', newline='')
csvwriter = csv.writer(file)
csvwriter.writerow(['名称', '年份'])
#写内容
links = ['https://movie.douban.com/subject/1292052/', 'https://movie.douban.com/subject/26752088/', 'https://movie.douban.com/subject/1962665/']
for link in links:
r = session.get(link)
title = r.html.find('#content > h1 > span:nth-child(1)', first=True)
year = r.html.find('#content > h1 > span.year', first=True)
csvwriter.writerow([title.text, year.text]) #TypeError: writerow() takes exactly one argument (2 given) 变成列表就是一个参数
#关
file.close()
----------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------
写新浪股票日值呢??

全打印出来了??还打印成这样???render()没办法解析我的需求???
如果是整个获取再分析,为什么不用r+b??
--------------------------------------------------------------
用bs4+requests+re:
找了canvas标签但没有children也不知道内容是什么
不会
。