这里使用到MySQL,对小白还算挺友好的。
当然还有其他数据库
- redis、mongodb(非关系数据库)
- influxdb (时序数据库)一般用作监控框架,单机版免费,了解一下?
废话少说,开始正题.
1、先创建scrapy项目
scrapy startproject dangdang
2、创一个爬虫,模式basic,crawl
scrapy genspider -t basic dd dangdang.com
3、了解项目相关内容
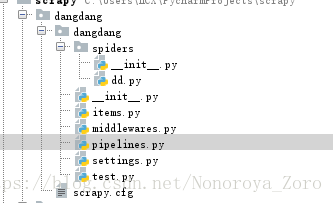
items.py 用于定义容器,在dd.py中可以使用,传递给pipelines.py处理
setting.py 设置scrapy项目的属性,例如user-agent、pipelines等设置
middlewares.py 中间件
一般编辑步骤 items->xx->pipelines->setting(按个人习惯吧)
items.py
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title= scrapy.Field()
link= scrapy.Field()
comment= scrapy.Field()
pass
dd.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from dangdang.items import DangdangItem
class DdSpider(scrapy.Spider):
name = 'dd'
allowed_domains = ['dangdang.com']
#start_urls = ['http://dangdang.com/']
ua = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
def start_requests(self):
return [Request('http://search.dangdang.com/?key=python&act=input&show=big&page_index=1#J_tab',headers=self.ua,callback=self.parse)]
def parse(self, response):
item=DangdangItem()
item['title']=response.xpath("//a[@class='pic']/@title").extract()
item['link'] = response.xpath("//a[@class='pic']/@href").extract()
item['comment'] = response.xpath("//a[@dd_name='单品评论']/text()").extract()
yield item
for i in range(2,33):
url='http://search.dangdang.com/?key=python&act=input&show=big&page_index='+str(i)+'#J_tab'
yield Request(url,callback=self.parse,headers=self.ua)pipelines.py
import pymysql
class DangdangPipeline(object):
def process_item(self, item, spider):
con=pymysql.connect('127.0.0.1','root','123','dangdang',charset='utf8')
cursor = con.cursor()
for i in range(len(item['title'])):
title=item['title'][i]
link = item['link'][i]
comment = item['comment'][i]
sql="""insert into books(title,link,comment) VALUES(%s,%s,%s)"""
cursor.execute(sql,(title,link,comment))
con.commit()
con.close()
return item
setting.py
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300, #取消注释
}
USER_AGENT = 'xxxxxxxxxx' #修改user_agent
ROBOTSTXT_OBEY = False #robot改为false
4、运行
单独运行dd爬虫(--nolog不加载log,界面整洁)
scrapy crawl dd
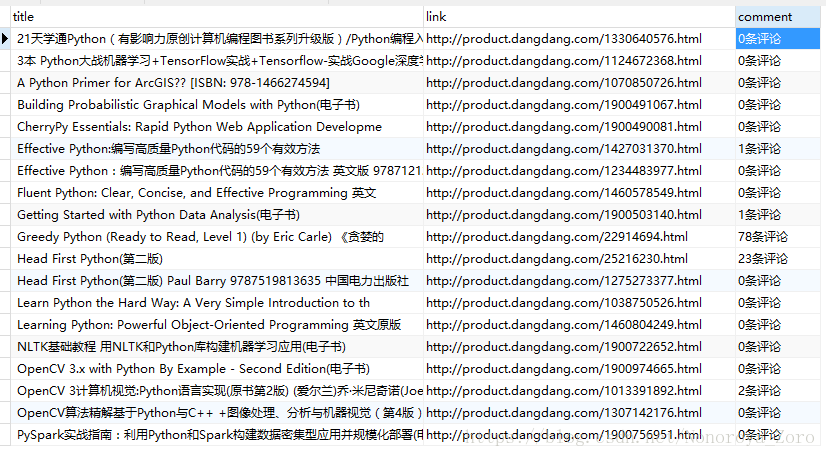
数据库中效果图: