图(Graph)
表示多对多的关系
复习:
- 线性表 1对1的关系
- 树 1对多的关系
- 图 多对多的关系
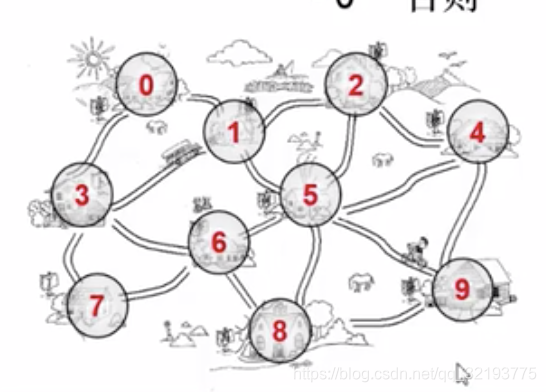
上述即是一个图的理解模型;
图的定义和术语:
- 一个图(G)定义为一个耦对(V,E),记为G=(V,E);其中V是顶点(Vertex)的非空有限集合,记为V(G);E是边的集合,记为E(G);
- 理解:如上图,每个村庄为一个结点 ,即每个村庄为一个顶点,边表示顶点和顶点之间的关系,即引出了单向和双向的问题; 无向边,顶点和顶点之间互通;
- 边是顶点对,如(v,w)属于E,其中v,w属于v。()表示无向边,即顶点v和顶点w互通;
- 有向边<v,w>,表示v->w,v能走到w,w不能走到v,其中 <v,w>属于E,v,w属于V;
- 图不考虑重边(只有一条边),和自回路(自己指向自己);
- 综上述,图有两部分组成顶点和边;V是非空的有限顶点的集合,E是一个有限边的集合; 记为G(V,E)
术语
-
无向图,图中的所有边都是无向的,则称为无向图;
-
有向图 ,图中的部分边是有向的,即边的方向很重要,官方定义:图中顶点偶对<v,w>的v,w之间是有序的,称图G是有向图;
-
图中每条边加了权重(例如距离,耗费等 ),则把此图称为网络
更多术语。。。持续更新;
程序表示图
邻接矩阵
用二位数组表示图
g[n][n], n表示n个顶点的编号
若g[i][j] = 1 // 表示i和j 连接有边
若g[i][j] = 0 // 表示i和j 无边
g[0][1] = 1 // 表示0和1直接有单向边
g[1][0] = 1//表示1和0有单向边,
//若g[0][1]=g[1][0]=1,则1和0之间无向边;
g[0][2]=0 //表示0和2直接无边
如下图;
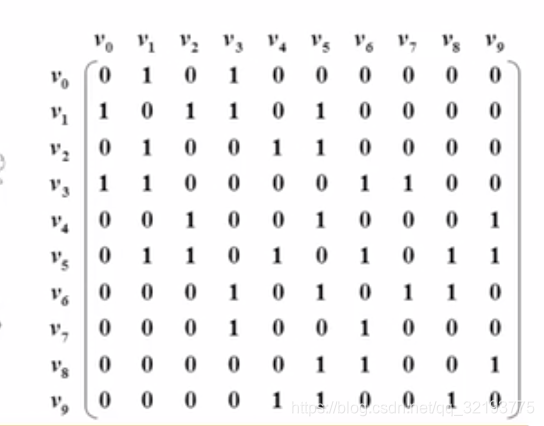
不允许自回路,故:
对角线为轴,对称的,无向图

问题:对于无向图,一半空间实际上是内存浪费;
解决办法
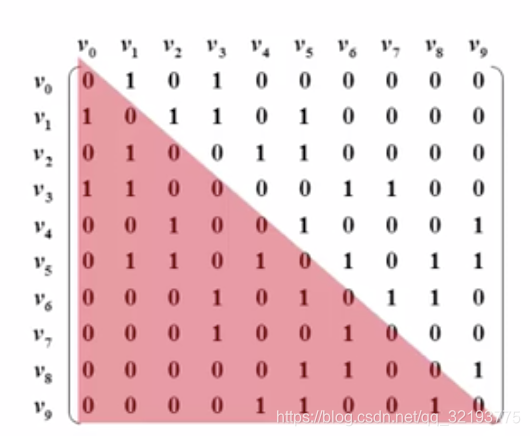

- 只存一半,用一维数组存储这个图;
- 1,2,3…n 求和公式 n(n+1)/2;故上图中g[i][j] 在一维数组中对应的下标为 i*(i+1)/2 +j
邻接矩阵
优点:
- 直观,好理解
- 方便查找任意两顶点是否存在边
- 方便查找一顶点的所有边;
- 方便计算这个顶点的度,(出度:从这个顶点出去的边的数量,入度:指向这个顶点的边的个数 )
缺点:
- 浪费空间,稀疏的图,空间利用率差,对于稠密图,完全图(任意两个不同的顶点间都有一条边,又细分为完全有向图,完全无向图 )就很合算,空间利用率高;
- 浪费时间,稀疏图–统计有多少个边;
邻接表

真的很省内存空间吗?
- 对于无向图,实际都存了2个边
- 链表中还存有地址
- 对于网络中,结构中还需要加权重;
故:对于邻接表来说,一定要够稀疏才合算
优点:
- 方便找一个顶点的所有的邻接点
- 节约稀疏图的空间
- 需要n个头指针+2e个结点(详见上图)
- 方便计算仁一个结点的度?
- 对于无向图来说是。
- 对于有向图,不是;
- 出度易,入度有向图难
图的表示方法有很多种 非上述2种;
优化这个缺点,思想类似于线性表的思想,从数组转换为链表—邻接表表示法
图的遍历
DFS(Depth First Search)深度优先搜索

问题描述,从亮的那盏灯开始,如何点亮所有的灯
核心思想,递归;
//类似于树的先序遍历;
//伪代码
public void dfs(Vertex v){
v.visited = true; //或者引入map等存储已访问的数据,设置v被防伪过
for(x的邻接点 w:v){
if(!w.visited){
dfs(w);
}
}
}
若图里有n个顶点,e条边,则时间复杂度为?
- 用邻接表表示 O(n+e);
- 用邻接矩阵表示,O(n2)
BFS(Breadth First Search) 广度优先搜索
在树中,类似于层序遍历;见树的博客:https://blog.csdn.net/qq_32193775/article/details/104031481,
https://blog.csdn.net/qq_32193775/article/details/104107629;
回忆:
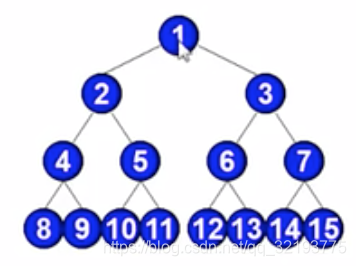
//伪代码如下
public void traversal(Tree tree){
if(tree!=null){
Queue que = Queue.getQueue(size);
que.add(tree);
while(!que.isEmpty()){
Tree treeTemp = que.pop();
System.out.println(treeTemp.data);
if(tree.left!=null)
que.add(tree.left);
if(tree.right!=null)
que.add(tree.right);
}
}
}
图中的BFS伪代码描述:
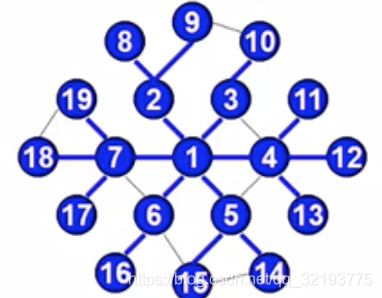
public void bfs(Vertex v){
Queue que = new Queue();
v.visited = true;
que.add(v);
while(!que.isEmpty){
Vertex v2 = que.pop();
for(v2的邻接点 w){
que.add(w);
w.visited = true;
}
}
}
若n个顶点,e条边,时间复杂度为?
- 邻接表 O(n+e)
- 邻接矩阵O(n2)
广度优先和深度优先的区别
-
深度优先是优先结点的子结点,处理完这些子结点后返回,直接深入该结点的子孙结点;
-
广度优先是利用了栈,在一圈一圈的处理,利用栈的先后顺序;在广度上逐步深入;
