一、组合查询
该章节讲述如何利用UNION操作符将多余SELECT语句组合成一个结果集合。
1、 组合查询
MySQL允许执行多个查询,并将结果作为单个查询结果返回。
组合查询的情况:
- 在单个查询中从不同地的表返回类似结构的数据。
- 对单个表执行多个查询,按单个查询返回结果。
2、 创建组合查询
可用UNION操作符来组合数条SQL查询,利用UNION可以给出多条SELECT语句,将它们的结果组合成单个结果集。
2.1、使用UNION
UNION的使用很简单,所需做的只是给出每条SELECT语句,在各条语句之间放上关键字UNION。
例子,将价格小于等于5元的产品进行检索,还要包括那些由生产商1001和1002生产的产品。
MariaDB [course]> SELECT prod_id,prod_price,vend_id
-> FROM products
-> WHERE prod_price <= 5
-> UNION
-> SELECT prod_id,prod_price,vend_id
-> FROM products
-> WHERE vend_id IN (1001,1002);
+---------+------------+---------+
| prod_id | prod_price | vend_id |
+---------+------------+---------+
| FC | 2.50 | 1003 |
| FU1 | 3.42 | 1002 |
| SLING | 4.49 | 1003 |
| TNT1 | 2.50 | 1003 |
| ANV01 | 5.99 | 1001 |
| ANV02 | 9.99 | 1001 |
| ANV03 | 14.99 | 1001 |
| OL1 | 8.99 | 1002 |
+---------+------------+---------+
8 rows in set (0.00 sec)
该例用多条WHERE子句的实现方法如下:
MariaDB [course]> SELECT prod_id,prod_price,vend_id
-> FROM products
-> WHERE prod_price <= 5
-> OR vend_id IN (1001,1002);
组合查询和多个WHERE条件:多数情况下,两个方法的查询结果相同且具有相同的功能。但是对于比较复杂的条件过滤,使用UNION处理更简单。
2.2、UNION规则
- UNION必须由两条或以上的SELECT语句组成,语句之间由 UNION进行分隔。
- UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序出现)
- 列数据类型必须兼容:类型不必完全相同,但是必须是DBMS可以相互转换的类型。
2.3、包含或取消重复的行
UNION从查询结果中自动去除了重复的和行,这是UNION的默认行为,如果需要可以改变。如果想返回所有匹配行,可使用UNION ALL进行。
MariaDB [course]> SELECT prod_id,prod_price,vend_id
-> FROM products
-> WHERE prod_price <= 5
-> UNION ALL
-> SELECT prod_id,prod_price,vend_id
-> FROM products
-> WHERE vend_id IN (1001,1002);
+---------+------------+---------+
| prod_id | prod_price | vend_id |
+---------+------------+---------+
| FC | 2.50 | 1003 |
| FU1 | 3.42 | 1002 |
| SLING | 4.49 | 1003 |
| TNT1 | 2.50 | 1003 |
| ANV01 | 5.99 | 1001 |
| ANV02 | 9.99 | 1001 |
| ANV03 | 14.99 | 1001 |
| FU1 | 3.42 | 1002 |
| OL1 | 8.99 | 1002 |
+---------+------------+---------+
9 rows in set (0.01 sec)
2.4、对组合查询结果进行排序
在使用UNION 组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。
MariaDB [course]> SELECT prod_id,prod_price,vend_id
-> FROM products
-> WHERE prod_price <= 5
-> UNION
-> SELECT prod_id,prod_price,vend_id
-> FROM products
-> WHERE vend_id IN (1001,1002)
-> ORDER BY vend_id,prod_price;
+---------+------------+---------+
| prod_id | prod_price | vend_id |
+---------+------------+---------+
| ANV01 | 5.99 | 1001 |
| ANV02 | 9.99 | 1001 |
| ANV03 | 14.99 | 1001 |
| FU1 | 3.42 | 1002 |
| OL1 | 8.99 | 1002 |
| FC | 2.50 | 1003 |
| TNT1 | 2.50 | 1003 |
| SLING | 4.49 | 1003 |
+---------+------------+---------+
8 rows in set (0.00 sec)
虽然ORDER BY子句似乎只是最后一条SELECT语句的组成部分,但实际上MySQL将用它来排序所有SELECT语句检索出的结果。
二、全文本搜索
1、 理解全文本搜索
之前介绍过的搜索机制有LIKE关键字和正则表达式。它们存在几个几个重要的限制:
- 性能——通配符和正则表达式匹配通常要求MySQL尝试匹配表的所有行。当搜索的行数逐渐增加会非常耗时。
- 明确控制——很难明确控制匹配的内容,
- 智能化的结果——不能提供一种智能化的选择结果的方法
使用全文本搜索,不需要分别查看每个行,不需要分别分析和处理每个词。MySQL创建指定列中各词的一个索引,搜索可以针对这些词进行。
并非所有引擎都支持全文本搜索:
两个最常用的引擎为MyISAM和InnoDB,前者支持而后者不支持。
2、 使用全文本搜索
为了进行全文本搜索,必须索引被搜索的列,而且随着数据的改变不断地重新索引。在对表列进行适当设计后,MySQL会自动进行所有的索引和重新索引。
在索引之后,SELECT可以与Match()和Against()一起使用以实现搜索 。
2.1、启用全文本搜索支持
一般在创建表时会启用全文本搜索。CREATE TABLE语句接受FULLTEXT子句,它给出被索引的列。
CREATE TABLE productnotes
(
note_id int NOT NULL AUTO_INCREMENT,
prod_id char(10) NOT NULL,
note_date datetime NOT NULL,
note_text text NULL ,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) ENGINE=MyISAM;
这是创建products表时的SQL语句,其中使用了FULLTEXT子句,还使用了MyISAM引擎。
MySQL使用了FULLTEXT(note_text)来指示对它进行索引,在定义之后,MySQL自动维护该索引,在增加、更新、删除行时,索引随之自动更新。
2.2、进行全文本搜索
在索引之后,使用两个函数执行全文本搜索。其中Match()指定被搜索的列,Against()指定要使用的搜索表达式。
MariaDB [course]> SELECT note_text
-> FROM productnotes
-> WHERE Match(note_text) Against('rabbit');
+----------------------------------------------------------------------------------------------------------------------+
| note_text |
+----------------------------------------------------------------------------------------------------------------------+
| Customer complaint: rabbit has been able to detect trap, food apparently less effective now. |
| Quantity varies, sold by the sack load.All guaranteed to be bright and orange, and suitable for use as rabbit bait. |
+----------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
此SELECT语句检索单个列note_text,Match(note_text)指示MySQL针对指定的列进行搜索,Against('rabbit') 指定词rabbit为搜索文本。
使用全文本搜索返回以文本匹配的良好程度排序的数据,两个行都包含要匹配的单词,但是所匹配单词在某一行出现的位置越靠前该行的等级就越高。具有较高等级的行优先返回。
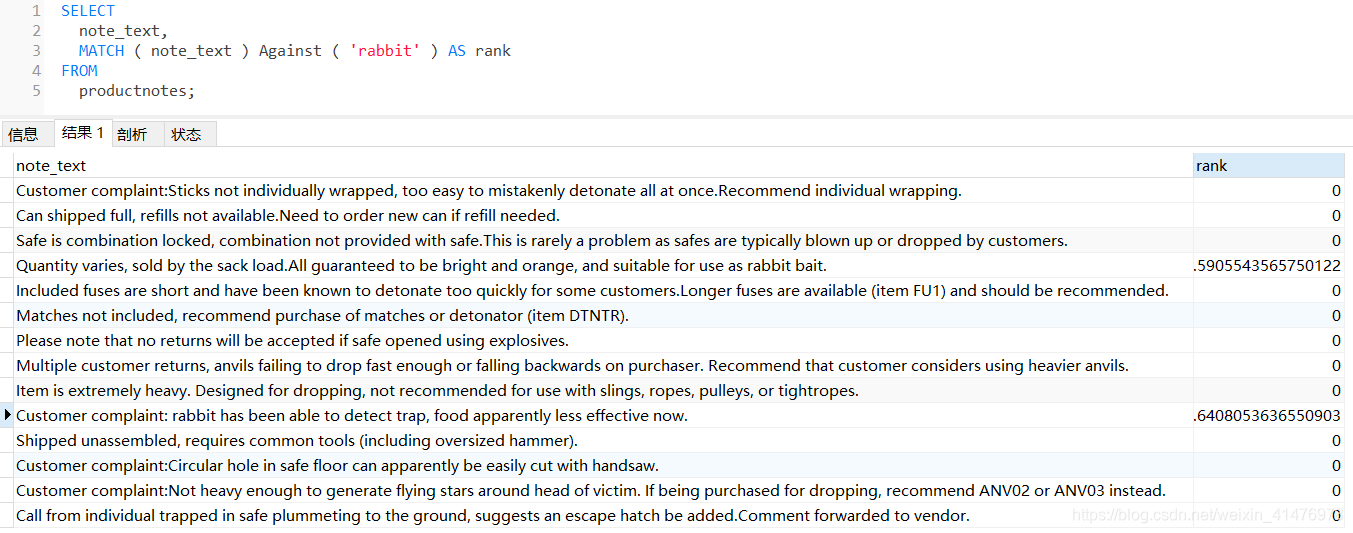
Match()和Against()用来建立一个计算列(别名为rank),此列包含全文本搜索计算出的等级值。
等级值根据行中词的数目、唯一词的数目、整个索引中词的总数以及包含该词的行的数目计算出来。
例子中,不包含搜措词的等级为0,位置靠前的等级越高。
全文本搜索将那些等级为0的行进行派出,按照等级以降序排序。
2.3、使用查询扩展
查询扩展用来设法放宽所返回的全文本搜索结果的范围。
在使用查询扩展时 ,MySQL对数据和索引进行两遍扫描来完成搜索:
- 首先,进行一个基本的全文本搜索,找出与搜索条件匹配的所有行;
- MySQL检查这些匹配行并选择所有有用的单词。
- MySQL再次进行全文本搜索,这次不仅使用原来的条件,而且还使用所有有用的词。
利用查询扩展,能找出可能相关的结果,即使它们并不精确包含所查找的词。
SELECT note_text
FROM productnotes
WHERE Match ( note_text ) Against ( 'anvils' WITH QUERY EXPANSION );

2.4、布尔文本搜索
使用布尔方式搜素,可以提供关于如下内容的细节:
- 要匹配的词
- 要排斥的词(如果某行包含这个词,则不返回该行。)
- 排列提示(指定某些词比其他词更重要)
- 表达式分组
- 另外一些内容
匹配包含heavy但不包含有以rope开头的单词的行。
MariaDB [course]> SELECT note_text
FROM productnotes
WHERE Match(note_text) Against('heavy -rope*' IN BOOLEAN MODE);
+---------------------------------------------------------------------------------------------------------------------------------------------------------+
| note_text |
+---------------------------------------------------------------------------------------------------------------------------------------------------------+
| Customer complaint:
Not heavy enough to generate flying stars around head of victim. If being purchased for dropping, recommend ANV02 or ANV03 instead. |
+---------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)

2.5、全文本搜索的使用说明
- 在索引全文本数据时,短词被忽略且从索引中删除。短词定义为那些3个字母以下的凡此
- MySQL带有一个内建的非用词(stopword)l列表,这些词在索引全文本数据时总是被忽略。
- 许多词的出现频率很高,搜索它们没有用处。因此,MySQL规定了一条50%规则,如果一个词出现在50%以上的行中,则将它作为一个非用词忽略。50%规则不用于IN BOOLEAN MODE.
- 如果表中的行数少于3行,则全文本搜索不返回结果
- 忽略词中的单引号。don`t 索引为dont
- 不具有词分隔符的语言不能恰当地返回全文本搜索结果
- 仅在MyISAM数据库 引擎中支持全文本搜索
