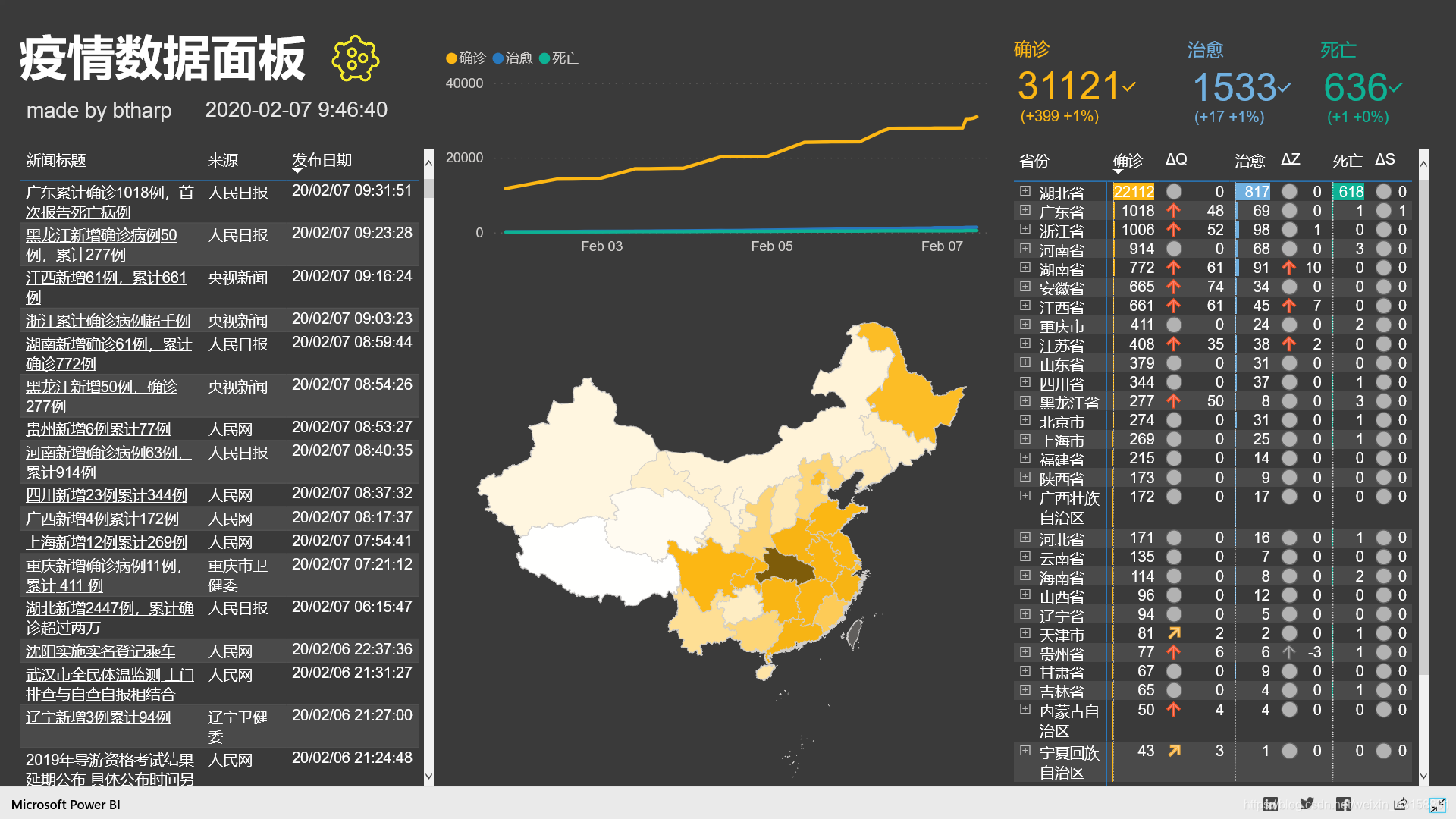
主要思路
- 用power bi制作可视化面板,数据要满足2个方面:power bi支持的数据源格式,数据源能够自动更新。
- power bi直接连接web可以获得数据,但是刷新之后会覆盖掉旧的数据。而且web上的新闻数据无法直接获取相应的链接。
- 解决思路是在服务器上,定时用接口调取数据写入mysql数据库,然后用power bi读取这个数据库。
数据获取
主要方式:
- 爬取腾讯、百度、丁香园的实时数据,可参考:https://blog.csdn.net/WildSky_/article/details/104092131
- 调接口,推荐2个:天气API,Github一个高手BlankerL的接口。前者不定期更新,各城市同步。后者每分钟更新,各城市不同步,但包含了丁香园的新闻数据。
- 本文用天气API各城市同步更新的数据,结合后者丁香园的新闻数据
- 调取方式如下:
import pandas as pd
import numpy as np
import pymysql
from sqlalchemy import create_engine
import requests
import json
import datetime
import time
# 连接服务器的数据库,XXX为你的数据
db_info = {'user': 'XXX', 'password': 'XXXX','host': 'XXXX','port': 3306,'database': 'XXX'}
engine = create_engine('mysql+pymysql://%(user)s:%(password)s@%(host)s:%(port)d/%(database)s?charset=utf8' % db_info, encoding='utf-8',connect_args={'charset':'utf8'})
def get_data():
URL="https://tianqiapi.com/api?version=epidemic&appid=XXX&appsecret=XXX" # 天气api的接口,两个XXX处需要注册这个接口后获得相应的appid和appecret
UL=requests.get(url=URL)
U=UL.json()
data=U["data"] # U是字典,data为主要的数据,详见接口说明
update_time=data["date"] # 更新时间
# 总历史数据
history=pd.DataFrame(data["history"])
history["date"]=pd.to_datetime(history["date"]) # str to datetime64
# 写入数据库,替换
pd.io.sql.to_sql(history,'history',con=engine, index=True, if_exists='replace')
# 以下数据需要判断是否新增再追加进去
last_time = pd.read_sql_query('select max(update_time) from city;', engine) # 数据库最近一次更新时间
if update_time>last_time.iloc[0,0]:
# 各省情况
area=pd.DataFrame(data["area"]) # 各省情况
area=area.drop(["cities","yesterdayIncreased"],axis=1)
area["update_time"]=update_time
# 写入数据库
pd.io.sql.to_sql(area,'area',con=engine, index=False, if_exists='append')
# 各市情况
city=[]
a=data["area"]
for i in range(len(a)):
for j in range(len(a[i]["cities"])):
a[i]["cities"][j].update({"provinceName":a[i]["preProvinceName"]})
city.append(a[i]["cities"][j])
city=pd.DataFrame(city)
city["update_time"]=update_time
# 写入数据库
pd.io.sql.to_sql(city[["cityName","confirmedCount","curedCount","deadCount","provinceName","suspectedCount","update_time"]],'city',con=engine, index=False, if_exists='append')
else:
area={}
city={}
# 新闻
news="https://lab.isaaclin.cn/nCoV/api/news?num=30" # 丁香园的数据
NL=requests.get(url=news)
N=NL.json()
News=pd.DataFrame(N["results"])
url_dict=News["sourceUrl"].to_dict() # 刚获取的url
Existing_url = pd.read_sql_query('select sourceUrl from news;', engine) # 已有的url
list_to_append=[] # 新的url
for key,url in url_dict.items():
if url not in Existing_url.values:
list_to_append.append(key)
pd.io.sql.to_sql(News.iloc[list_to_append,:],'news',con=engine, index=False, if_exists='append')
return data,update_time,area,history,city,News
if __name__ == '__main__':
get_data()
服务器定时运行
设置定时运行
crontab -e语法:分(0-59) 小时(0-23) 日(1-31) 月(1-12) 周几(0-6) 运行工具 脚本
需要注意的是,运行工具python也要写成绝对路径
50 * * * * /root/anaconda3/bin/python3.7 /root/2019-nCov/2019-nCov-bt.pyPower BI 制作
略过数据导入等基础环节,主要讲一下一些细节点。
-
中国地图热图
比较了原生和商城上的,最后用shape map制作。
shape map默认是美国地图,但可以添加其他地图,只支持topojson格式。图中这列用来关联相应的数据。
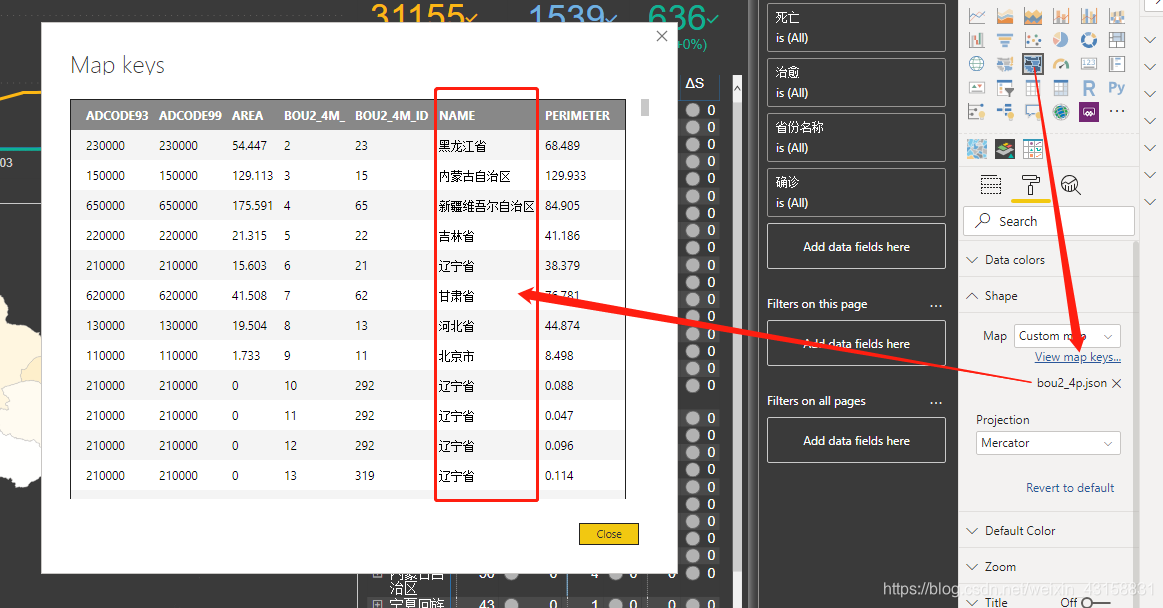
另外,shape map的热图只支持三个等级,而且对于偏态分布比较严重的数据,三个等级对应的数值都要填进去,不然会默认最高值的一半为中间值,则会造成湖北颜色特深其他省颜色基本看不出区别的情况。
说明一下另外几个可视化工具:
Synoptic Panel,可以插入多张SVG地图。缺点是无法多地方批量应用热图,每个区域(省/城市)要单独设置颜色,比较麻烦。
Drilldown Choropleth,据说可以从省份下钻到城市,但是因为只有美国地图,用中国地图无论geojson还是topojson格式还没设置成功过。据一些用户评论好像后来没有维护不太能用了。
-
确诊人数等度量值
首先是最近更新时间,即数据表里最大的时间:
最近更新时间 = MAXX(all('nCov city'),[更新时间]) 对应的确诊人数:
确诊 = calculate(sum('nCov city'[确诊]),filter('nCov city',[更新时间]=[最近更新时间]))上期确诊人数
确诊上期 = CALCULATE(sum('nCov city'[确诊]),FILTER('nCov city',[rank]=2)) 上面的rank是时间的倒排序,最新时间为1,次新时间为2。由于时间精确到分秒,所以无法用常用的时间智能函数。
- 矩阵条件格式

确诊、治愈和死亡用了数据条。
后面的ΔQ,ΔZ和ΔS是当期跟上期的差额,其中数据为0的用灰色圆圈表示。
