隐语义分析主要是根据隐含的特征将用户和物品联系起来,采用的是ALS算法(交替最小二乘法)
假设有N个用户和M个物品,器user-item矩阵为N*M
第一步:分解,将用户和物品都分解为F个因子的矩阵,则有(F*N)T*(F*M)=N*M,其中T表示转置

图中R为用户与物品的历史关系矩阵,其中R11…R34等等为用户对物品的兴趣度。
对于隐形反馈数据,只要用户浏览了该产品,我们就可以认为用户对物品的兴趣度为1,也就是Rxx为1,否则为0。
对于显性反馈数据,比如用户对物品的评分为1-5分,那么Rxx的取值范围为1-5,对于显性数据,可以将其归一化进行计算。
我们的目标就是要得到一个合适的P、Q。使得他们的乘积结果等于Rxy
其中Rxy=P*Q
这是一个简单的线性回归模型
初始化的P、Q矩阵相乘得到的结果带入sigmod函数计算出结果在0-1之间,肯定与R有差异,那么我们就通过梯度下降来优化模型参数,加入正则化参数来避免过拟合。
1.计算用户对物品i的相似性(传统算法)
This set of k neighbors is denoted by Sk(i;u). The predicted value of rui is taken as a weighte daverage ofth eratings for neighboring items:

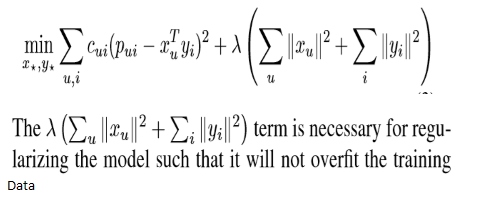
3.2求解模型采用梯度下降法
3.3偏好值得计算
用户u对物品i的隐性反馈动作超过一次,我们就觉得u喜欢i。动作频次越多。这个如果的置信度就越高。如果没有动作,则觉得u对i的偏好值为0。当然由于动作次数为0。所以“u对i的偏好值为0”这个如果的置信度就非常低。动作频次越大,置信度越高
