本文的来源有两个。
1. 知乎文章《可以用 Python 编程语言做哪些神奇好玩的事情?》中来自于freeyourmind的回答帖,他的一种网络隔离情况下代码提取的解决方案给了我启发。
2. 一个python微信兴趣群里有人分享了python库介绍的相关文章,里面提到用于图像识别的pytesseract。
两者结合在一起,产生了本文。
再次简单描述一下问题本身,总结解决方案。
工作环境是windows,代码环境是Linux(Nomachine中),windows和NoMachine做了网络隔离,NoMachine中的代码没法自由拷贝。
我们用python来解决这种网络隔离条件下NoMachine中代码提取的问题,分为以下三步:
1. Nomachine中将文件分屏打印。
2. Windows中依次截图。
3. 网络连通的NoMachine中将图片转化为代码。
食材备齐,美味出炉。
一、 NoMachine中文件分屏打印。
NoMachine中需要选取文件(文件,或目录下所有文件),展示文件名(包含路径)及文件内容,文件内容需连续展示,每次展示之间保留一定时间间隔以方便截屏。
我用python写了个小工具printFiles来实现这个功能,Usage如下。
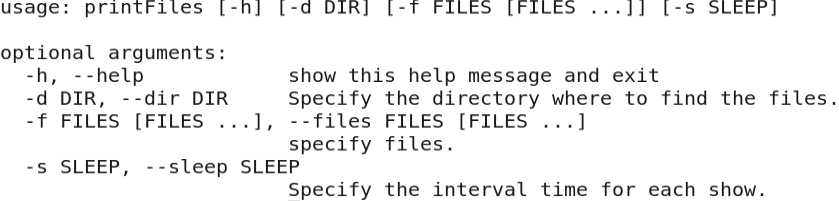
使用时可以一次指定一个文件,也可以指定一个目录,它会分屏打印目录下所有的文件,十分方便。
代码如下(python3.5)。
#!/usr/local/bin/anaconda3/bin/python3.5
# -*- coding: utf-8 -*-
import os
import re
import sys
import time
import argparse
os.environ['PYTHONUNBUFFERED'] = '1'
lastTime = time.time()
def readArgs():
"""
Read arguments.
"""
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--dir',
default='',
help='Specify the directory where to find the files.')
parser.add_argument('-f', '--files',
nargs='+',
default=[],
help='specify files.')
parser.add_argument('-s', '--sleep',
type=int,
default=5,
help='Specify the interval time for each show.')
args = parser.parse_args()
return(args.dir, args.files, args.sleep)
def checkArgs(dir, files, sleep):
"""
Check args.
"""
if (dir == '') and (len(files) == 0):
print('*Error*: There is neither directory nor file specified.')
sys.exit(1)
elif (dir != '') and (len(files) > 0):
print('*Error*: Both of directory and file are specified.')
sys.exit(1)
else:
if dir != '':
if not os.path.exists(dir):
print('*Error*: ' + str(dir) + ': No such direcotry.')
sys.exit(1)
else:
for (topPath, dirList, fileList) in os.walk(dir, topdown=True):
for file in fileList:
files.append(str(topPath) + '/' + str(file))
for file in files:
if not os.path.exists(file):
print('*Error*: ' + str(file) + ': N0 SUCh file.')
sys.exit(1)
if sleep <= 0:
print('*Error*: sleep time is "' + str(sleep) + '", it must be longer than 0 seconde.')
sys.exit(1)
return(files, sleep)
def waitForSpecifiedTime(sleep):
"""
Wait for specified time.
"""
global lastTime
while True:
currentTime = time.time()
timeDelta = currentTime - lastTime
if timeDelta >= sleep:
lastTime = currentTime
break
def printFiles(files, sleep):
"""
Show file contains screen by screen, wait for specified time between displays.
"""
# Get the screen size.
screenLines = int(os.popen('tput lines').read().strip())
screenCols = int(os.popen('tput cols').read().strip())
for file in files:
# Ignore below directories/files.
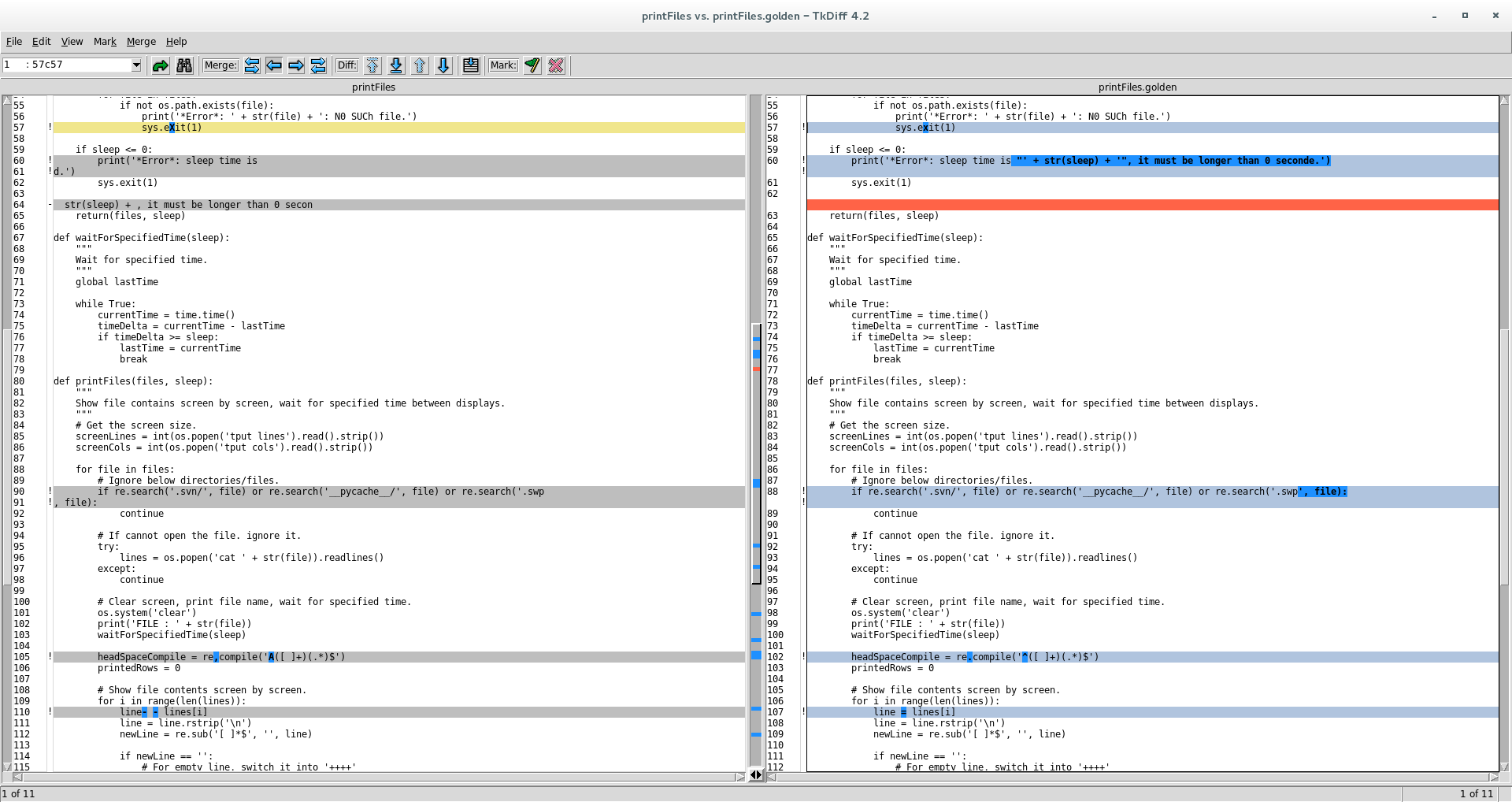
if re.search('.svn/', file) or re.search('__pycache__/', file) or re.search('.swp', file):
continue
# If cannot open the file. ignore it.
try:
lines = os.popen('cat ' + str(file)).readlines()
except:
continue
# Clear screen, print file name, wait for specified time.
os.system('clear')
print('FILE : ' + str(file))
waitForSpecifiedTime(sleep)
headSpaceCompile = re.compile('^([ ]+)(.*)$')
printedRows = 0
# Show file contents screen by screen.
for i in range(len(lines)):
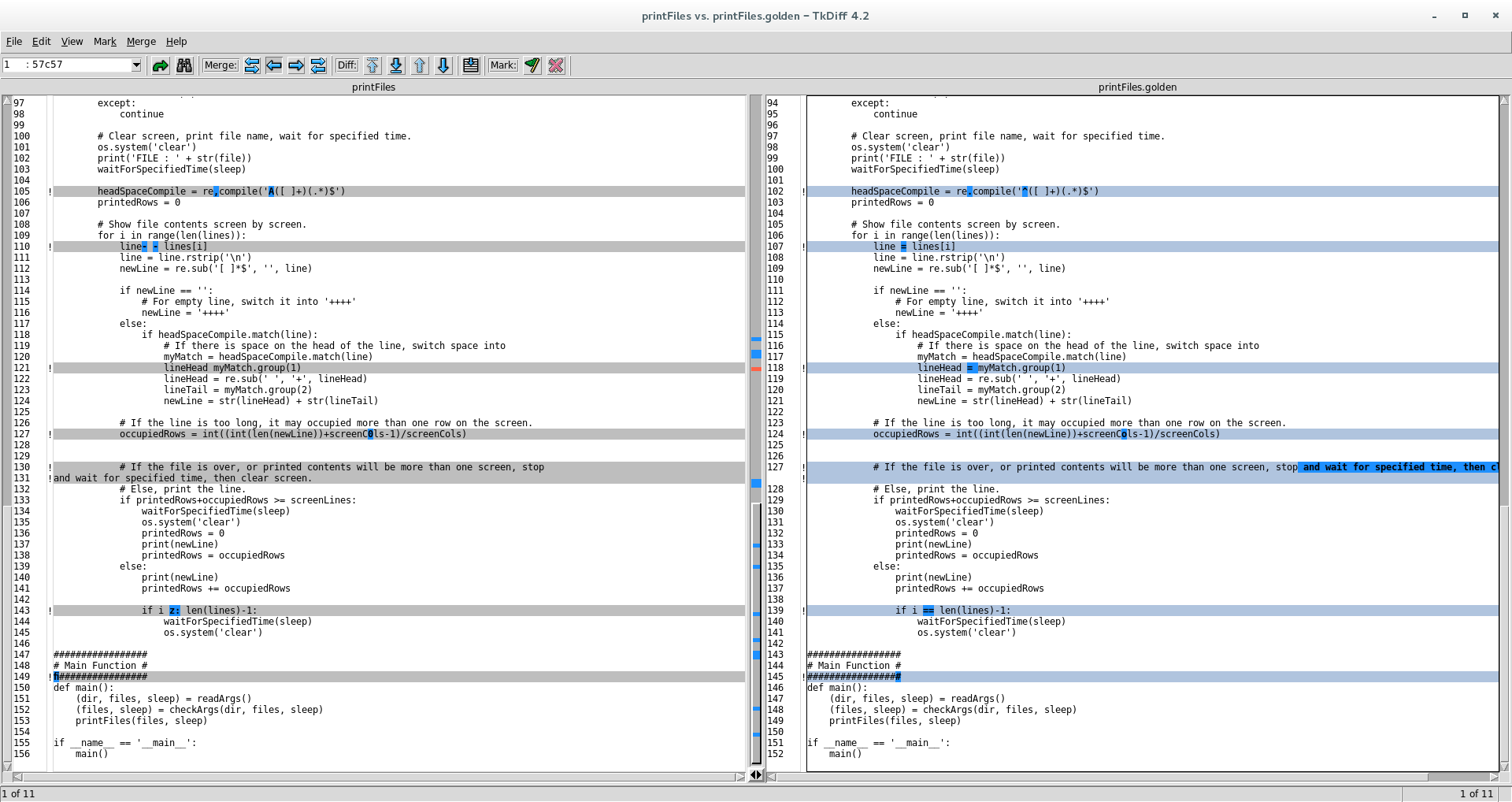
line = lines[i]
line = line.rstrip('\n')
newLine = re.sub('[ ]*$', '', line)
if newLine == '':
# For empty line, switch it into '++++'
newLine = '++++'
else:
if headSpaceCompile.match(line):
# If there is space on the head of the line, switch space into
myMatch = headSpaceCompile.match(line)
lineHead = myMatch.group(1)
lineHead = re.sub(' ', '+', lineHead)
lineTail = myMatch.group(2)
newLine = str(lineHead) + str(lineTail)
# If the line is too long, it may occupied more than one row on the screen.
occupiedRows = int((int(len(newLine))+screenCols-1)/screenCols)
# If the file is over, or printed contents will be more than one screen, stop and wait for specified time, then clear screen.
# Else, print the line.
if printedRows+occupiedRows >= screenLines:
waitForSpecifiedTime(sleep)
os.system('clear')
printedRows = 0
print(newLine)
printedRows = occupiedRows
else:
print(newLine)
printedRows += occupiedRows
if i == len(lines)-1:
waitForSpecifiedTime(sleep)
os.system('clear')
#################
# Main Function #
#################
def main():
(dir, files, sleep) = readArgs()
(files, sleep) = checkArgs(dir, files, sleep)
printFiles(files, sleep)
if __name__ == '__main__':
main()使用如下(printFiles打印自身)。
printFiles打印自身,每5秒钟打印一屏。
![]()
二、 Windows中截屏。
推荐使用定时截图软件MultiScreenshots。
我自己也写了个小工具screenShots.py来实现相同的功能,胜在能够自由定制图片输出格式,Usage如下。
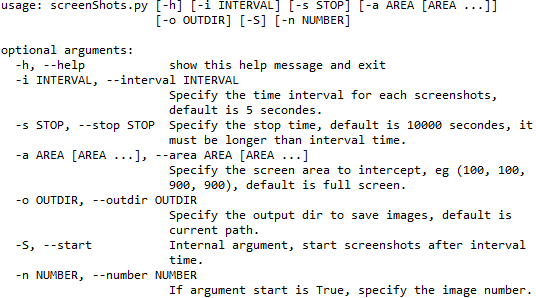
使用时需要注意的是,我们只截取NoMachine中代码显示区域,所以需要指定--area参数,而具体的参数如何设置,还需要取决于代码区域的实际尺寸,尝试几次后即可得到,且同一个工作环境一旦得到这个区域后无需更改。
-i指定每次截屏时间间隔,需要和printFiles中-s参数指定的时间一致。
-s指定stop时间,如果不知道具体的stop time,可以不设或者设的大一点,等到人工观测到printFiles打印完毕后手工killscreenShots.py进程。
代码如下(python3.6)。
# -*- coding: utf-8 -*-
import os
import sys
import argparse
import time
import subprocess
from PIL import ImageGrab
os.environ['PYTHONUNBUFFERED'] = '1'
cwd = os.getcwd()
currentTool = sys.argv[0]
def readArgs():
"""
Read arguments.
"""
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--interval',
type=int,
default=5,
help='Specify the time interval for each screenshots, default is 5 secondes.')
parser.add_argument('-s', '--stop',
type=int,
default=10000,
help='Specify the stop time, default is 10000 secondes, it must be longer than interval time.')
parser.add_argument('-a', '--area',
nargs='+',
default=[],
help='Specify the screen area to intercept, eg (100, 100, 900, 900), default is full screen.')
parser.add_argument('-o', '--outdir',
default=cwd,
help='Specify the output dir to save images, default is current path.')
parser.add_argument('-S', '--start',
action='store_true',
default=False,
help='Internal argument, start screenshots after interval time.')
parser.add_argument('-n', '--number',
type=int,
default=0,
help='If argument start is True, specify the image number.')
args = parser.parse_args()
return(args.interval, args.stop, args.area, args.outdir, args.start, args.number)
def checkArgs(interval, stop, area, outdir):
"""
Check argument validation, some pre-set.
"""
# interval time cannot be equal/less than 0 second.
if interval <= 0:
print('*Error*: interval time cannot be equal/less than zero.')
sys.exit(1)
# stop time cannot be equal/less than interval time.
if stop <= interval:
print('*Error*: stop time cannot be equal/less than interval time.')
sys.exit(1)
# For argument "area", it must be empty or has four parameters.
if len(area) != 0:
if len(area) != 4:
print('*Error*: area setting must contains four parameters.')
sys.exit(1)
else:
beginX = int(area[0])
beginY = int(area[1])
endX = int(area[2])
endY = int(area[3])
# argument "area" contains two points ((beginX, beginY), (endX, endY))
if (beginX >= endX) or (beginY >= endY):
print('*Error*: area "' +str(area) + '": Wrong format!')
sys.exit(1)
# Create outdir if not exists.
if not os.path.exists(outdir):
print('*Warning*: outdir "' + str(outdir) + '": No such directory, will create it.')
try:
os.makedirs(outdir)
except Exception as error:
print('*Error*: Failed on creating output directory "' + str(outdir) + '": ' + str(error))
sys.exit(1)
def screenshots(interval, stop, area, outdir, start, number):
"""
Screenshots.
"""
startTime = time.time()
if start:
if len(area) == 4:
# Specify the screenshots area.
image = ImageGrab.grab(bbox=(int(area[0]), int(area[1]), int(area[2]), int(area[3])))
else:
# Full screen to grab.
image = ImageGrab.grab()
os.chdir(outdir)
# Save "png" picture, PIL.Image can recognize this format picture.
image.save('screenshots_' + str(number) + '.png')
sys.exit(0)
else:
i = 0
lastTime = startTime
while True:
while True:
# After stop time, exit.
currentTime = time.time()
timeDelta = currentTime - startTime
if timeDelta >= stop:
sys.exit(0)
# Wait for specified time, it must be the same with script "printFiles".
timeDelta = currentTime - lastTime
if timeDelta >= interval:
lastTime = currentTime
break
# For sub-run, after interval time, re-start this script for screenshots.
command = 'python ' + str(currentTool)
if len(area) == 4:
areaArg = ' '.join(area)
command = str(command) + ' -a ' + str(areaArg)
command = str(command) + ' -o ' + str(outdir)
command = str(command) + ' -S'
command = str(command) + ' -n ' + str(i)
print('COMMAND : ' + str(command))
try:
myScreenshots = subprocess.Popen(command, shell=True)
myScreenshots.communicate()
except Exception as error:
print('*Error*: Failed on executing sub-script for screenshots!')
sys.exit(1)
i += 1
#################
# Main Function #
#################
def main():
(interval, stop, area, outdir, start, number) = readArgs()
checkArgs(interval, stop, area, outdir)
screenshots(interval, stop, area, outdir, start, number)
if __name__ == '__main__':
main()
截取屏幕的命令如下。
![]()
三、 Nomachine中将图片转化为代码
我写了个小工具codeTrans来实现这个功能,Usage如下。

它会调用tesseract-ocr来进行图像识别。
需要说明的几点:
1. 一般来说合适的图形分辨率能够具有较好的图像识别率,所以应当适当增大NoMachine中的字体大小,然后截图。
2. tesseract-ocr识别率有限,但是同一种分辨率下一般错误识别的代码比较具有特征性,所以我们可以做一些后处理来弥补部分错误识别的代码。
3. 最终还是有一些错误识别的,就需要手工来验证和更正,但这个工作量一般就可以接受了。
代码如下(python3.5)。
#!/usr/local/bin/anaconda3/bin/python3.5
# -*- coding: utf-8 -*-
import os
import re
import sys
import argparse
from PIL import Image
import pytesseract
os.environ["PYTHONUNBUFFERED"]="1"
cwd = os.getcwd()
def readArgs():
"""
Read arguments.
"""
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--input',
required=True,
nargs='+',
default=[],
help='Specify the ordered input images.')
parser.add_argument('-o', '--outdir',
default=cwd,
help='Specify the output directory.')
args = parser.parse_args()
return(args.input, args.outdir)
def codeTransfer(images, outdir):
"""
Identify images into codes, write the codes into specified outdir.
"""
emptyLineCompile = re.compile('^\s*$')
headCompile = re.compile('^(\++)(.*)$')
fileCompile = re.compile('^FILE : (\S+)\s*$')
startMark = 0
for image in images:
if not os.path.exists(image):
print('*Error*: "' + str(image) + '": No such an image.')
sys.exit(1)
# Transfer image to string.
text = pytesseract.image_to_string(Image.open(image), lang='eng')
lines = text.split('\n')
# Check string line by line.
for line in lines:
line = line.strip()
# There should not be empty line, so ignore empty line.
if emptyLineCompile.match(line):
continue
# Once find "FILE : ", mark it as the begin of the new file.
if fileCompile.match(line):
myMatch = fileCompile.match(line)
(filePath, fileName) = os.path.split(myMatch.group(1))
if filePath == '':
outputDir = str(outdir)
else:
if re.match('^/', filePath):
filePath = re.sub('^/', '', filePath)
outputDir = str(outdir) + '/' + str(filePath)
# Get the file path and file name, create the same file path on local.
if not os.path.exists(outputDir):
try:
os.makedirs(outputDir)
except Exception as error:
print('*Error*: Failed on creating output directory "' + str(outputDir) + '": ' + str(error))
sys.exit(1)
outputFile = str(outputDir) + '/' + str(fileName)
FL = open(outputFile, 'w')
startMark = 1
continue
# If there are '+' on the head of the line, switch them into spaces.
if headCompile.match(line):
myMatch = headCompile.match(line)
lineHead = myMatch.group(1)
lineHead = re.sub('\+', ' ', lineHead)
lineTail = myMatch.group(2)
line = str(lineHead) + str(lineTail)
# Some fix for mis-recognize.
line = re.sub('([a-zA-Z])0([a-zA-Z])', lambda m:m.group(1)+'o'+m.group(2), line)
line = re.sub('([a-zA-Z])7([a-zA-Z])', lambda m:m.group(1)+'_'+m.group(2), line)
line = re.sub('1([a-zA-Z])', lambda m:'l'+m.group(1), line)
line = re.sub('([a-zA-Z])1', lambda m:m.group(1)+'l', line)
line = re.sub('^([^"]*)"([^"]*)$', lambda m:m.group(1)+"''"+m.group(2), line)
line = re.sub('05', 'os', line)
line = re.sub('IIIIII', '"""', line)
line = re.sub('os-enViFon', 'os.environ', line)
line = re.sub('Ainamegi', "'__name__':", line)
line = re.sub('47main47', '__main__', line)
line = re.sub('-l', '-1', line)
line = re.sub('“', '"', line)
line = re.sub('‘', "'", line)
line = re.sub('’', "'", line)
line = re.sub('—', '-', line)
if re.match('^(\s+)[u|n][u|n][u|n]\s*$', line):
myMatch = re.match('^(\s+)[u|n][u|n][u|n]\s*$', line)
line = str(myMatch.group(1)) + '"""'
# Update the python path to local path.
if startMark == 1:
startMark = 0
line = '#!/usr/local/bin/anaconda3/bin/python3.5'
print(line)
FL.write(str(line) + '\n')
#################
# Main Function #
#################
def main():
(images, outdir) = readArgs()
codeTransfer(images, outdir)
if __name__ == '__main__':
main()转化命令如下。
![]()
如下,将图像识别转换出来的代码与源代码相比,有部分不匹配(11行),主要包括一行长度过长造成了断行,字母误识别,字符误识别,但是整体的识别率完全可以接受,至少比重复手敲一遍代码的效率提高95%不止。