前面咱们也写了好几篇爬虫的文章,都是些数据量不是很多的例子。那如果遇到数据量比较大的时候怎么办提高速度和效率呢。今天的这篇会给你答案。
一、线程、进程、协程的简介
1.同步、异步、并行、并发
同步:各个任务不是独自运行的,任务之间有一定的运行顺序
异步:各个任务是独立运行的,一个任务的运行不收另一个任务的影响
并行:同一时刻发生若干事情的情况
并发:同一时间段发生若干事情。
这里可能并行和并发不是很好记忆,我来举个例子把。小明正在写作业,小红正在看电视。两件事情同时进行,这叫并行。如果小明看一眼电视,看一眼作业,这叫做并发,并不能同时做这两件事,只不过这两件事切换比较快,看起来像是同时在发生。
在单核CPU时,所有任务都是以并发的形式来运行的,
在多核CPU情况下,才会有真正的并行的形式运行任务。
2.线程
- 操作系统进行运算的最小单位
- 线程是独立调度和分派的基本单位
- 同一个进程中的所有线程可以共享该进程的资源
- 同一进程中的所有线程均可并发执行
- 由于Python中GIL(全局解释器锁)的存在,线程之间只能以并发执行存在。
3.进程
- 系统进行资源分配和调度的基本单位
- 进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)
- 程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程
- 运行中的进程可能存在以下三种情况:就绪、运行、阻塞
4.协程
- 一种用户态的轻量级线程。
- 协程方便切换控制流
- 具有很好的高扩展性和高并发行
- 本质是单线程
二、多线程、多进程、多协程者的区别
图1 多线程的运行方式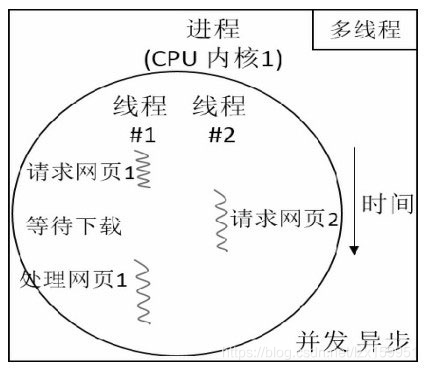
图2 多进程的运行方式
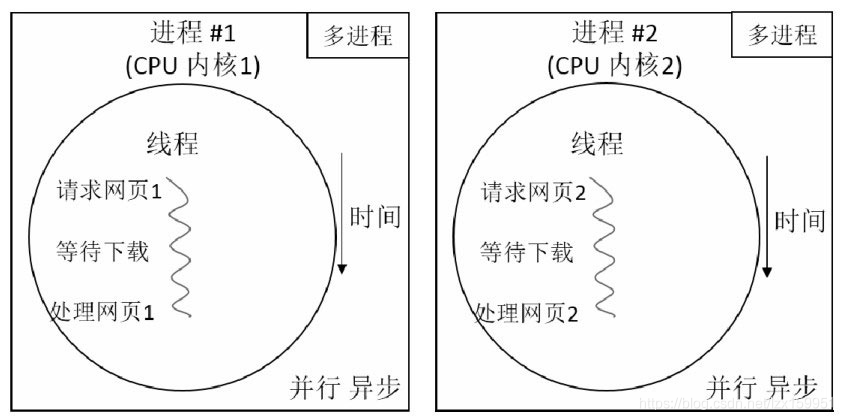
图3 多协程的运行方式
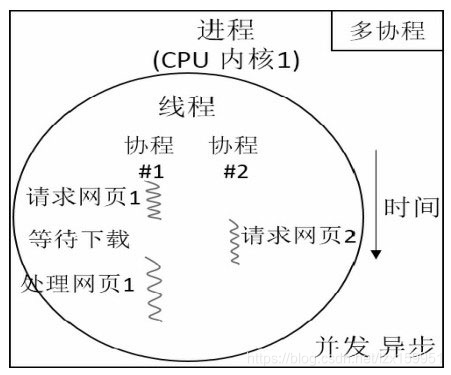
- 每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
- 线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
- 协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
- 线程可以使用多核CPU,但是协程不可以。
- 如果是 I/O 密集型,且 I/O 请求比较耗时的话,使用协程。
如果是 I/O 密集型,且 I/O 请求比较快的话,使用多线程。
如果是 计算 密集型,考虑可以使用多核 CPU,使用多进程。
三、三种爬虫方式的实验对比
本次实验是爬取豆瓣top250电影,输出电影的名字。
具体的分析我就不写了,主要是对比这三种方法的速度快慢
1.多进程
from multiprocessing import Process,Queue,Pool,Manager
import requests
import time
from bs4 import BeautifulSoup
def crawler_run(q,index):
Process_id='Process--'+str(index)
while not q.empty():
num = q.get(timeout=2)
soup = connec_douban(num)
titles = soup.findAll("div",class_="item")#.find("span",class_="title").text
for title in titles:
print(Process_id,q.qsize(),title.find("span",class_="title").text+"\n")
def connec_douban(num1):
link="https://movie.douban.com/top250?start="+str(num1)+"&filter="
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
re = requests.get(link,headers=headers)
soup = BeautifulSoup(re.text,"lxml")
print("url-status",re.status_code,end="\n")
return soup
if __name__=='__main__':
start = time.time()
manager = Manager()
p = Pool(4)
q = manager.Queue(10)
#q = Queue(10)
for j in range(0,225,25):
q.put(j)
for i in range(4):
p.apply_async(func=crawler_run,args=(q,i))
print("Start Process",i)
p.close()
p.join()
end = time.time()
print('Pool+Queue 的多进程爬虫的总时间为',end-start)
print("END")
2.多线程
import requests
from bs4 import BeautifulSoup
import time
import threading
import queue
class Mythreading(threading.Thread):
def __init__(self,q,name):
threading.Thread.__init__(self)
self.q = q
self.name=name
def run(self):#这个run方法在进程创建后会自动运行这个程序
# print("starting"+self.name)
# print(self.q.qsize())
# print(self.q.empty())
while not self.q.empty():
crawler_run(self.q,self.name)
print("exiting...")
def crawler_run(q,name):
num = q.get(timeout=2)
soup = connec_douban(num)
#print("run-run")
titles = soup.findAll("div",class_="item")#.find("span",class_="title").text
for title in titles:
print(name,q.qsize(),title.find("span",class_="title").text+"\n")
def connec_douban(num1):
link="https://movie.douban.com/top250?start="+str(num1)+"&filter="
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
re = requests.get(link,headers=headers)
soup = BeautifulSoup(re.text,"lxml")
# print("url-status",re.status_code,end="\n")
return soup
if __name__=='__main__':
threadset=[]
start = time.time()
q = queue.Queue(14)
for i in range(0,326,25):
q.put(i)
ThreadNames=["process1","process2","process3","process4"]
for i in range(0,4):
p = Mythreading(q,ThreadNames[i])
p.start()
threadset.append(p)
for thread in threadset:
thread.join()
end = time.time()
print("总时间:",end-start)
3.多协程
import gevent
from gevent.queue import Queue,Empty
from gevent import monkey
monkey.patch_all()#将IO转化为异步执行的函数
import time
from bs4 import BeautifulSoup
import requests
link_list=[]
def crawler_run(index):
processid = 'process-'+str(index)
while not workqueue.empty():
num = workqueue.get(timeout=2)
soup = connec_douban(num)
titles = soup.findAll("div",class_="item")#.find("span",class_="title").text
for title in titles:
print(processid,workqueue.qsize(),title.find("span",class_="title").text+"\n")
def connec_douban(num1):
link="https://movie.douban.com/top250?start="+str(num1)+"&filter="
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
re = requests.get(link,headers=headers)
soup = BeautifulSoup(re.text,"lxml")
# print("url-status",re.status_code,end="\n")
return soup
def boss():
for i in range(0,226,25):
workqueue.put_nowait(i)
if __name__=='__main__':
start = time.time()
workqueue = Queue(10)
gevent.spawn(boss).join()
jobs = []
for i in range(4):
jobs.append(gevent.spawn(crawler_run,i))
gevent.joinall(jobs)
end = time.time()
print("总时间为",end-start)
三种方案我们均运行五次,取平均运行时间
| 方式 | 个数 | 时间 |
|---|---|---|
| 协程 | 4 | 1.3279s |
| 线程 | 4 | 1.7486s |
| 进程 | 4 | 3.1559s |
由于这个实验的数据量不是很大,所以这个结果不具有代表性,但是也能够反映一些问题。
结论:针对数据量比较小,而且I/O比较频繁的,推荐使用协程。当然,你也可以将他们结合起来使用。
参考来源:
[1]:进程、线程、协程的理解
[2]:进程和线程、协程的区别
[3]:百度百科-协程
[4]:百度百科-线程
[5:]百度百科-进程
