正则表达式–简介/常用规则/基础操作
简介
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
1、元字符介绍
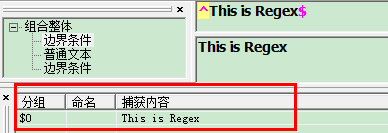
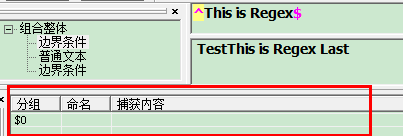
"^" :^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。
"$" : $会匹配行或字符串的结尾
如图
而且被匹配的字符必须是以This开头有空格也不行,必须以Regex结尾,也不能有空格与其它字符
"\b" :不会消耗任何字符只匹配一个位置,常用于匹配单词边界 如 我想从字符串中"This is Regex"匹配单独的单词 “is” 正则就要写成 “\bis\b”
\b 不会匹配is 两边的字符,但它会识别is 两边是否为单词的边界
"\d" :匹配数字,
例如要匹配一个固定格式的电话号码以0开头前4位后7位,如0737-5686123 正则:^0\d\d\d-\d\d\d\d\d\d\d$ 这里只是为了介绍"\d"字符,实际上有更好的写法会在 下面介绍。
"\w" :匹配字母,数字,下划线.
例如我要匹配"a2345BCD__TTz" 正则:"\w+" 这里的"+"字符为一个量词指重复的次数,稍后会详细介绍。
"\s" :匹配空格
例如字符 “a b c” 正则:"\w\s\w\s\w" 一个字符后跟一个空格,如有字符间有多个空格直接把"\s" 写成 “\s+” 让空格重复
"." :匹配除了换行符以外的任何字符
这个算是"\w"的加强版了"\w"不能匹配 空格 如果把字符串加上空格用"\w"就受限了,看下用 “.“是如何匹配字符"a23 4 5 B C D__TTz” 正则:”.+"
"[abc]" :字符组 匹配包含括号内元素的字符
这个比较简单了只匹配括号内存在的字符,还可以写成[a-z]匹配a至z的所以字母就等于可以用来控制只能输入英文了
上面说的一大堆基本没什么用,建议将示例代码粘去跑一跑,改一改,再跑一跑。
示例代码:
#include <iostream>
#include <string>
#include <regex>
using namespace std;
void regex_match_test()
{
/* std::regex_match:
判断一个正则表达式(参数re)是否匹配整个字符序列str,它主要用于验证文本
注意: 这个正则表达式必须匹配被分析串的全部,
否则返回false;如果整个序列被成功匹配,返回true
*/
string s = "ccaatt";
vector<regex> regs;
vector<string> patterns = {
"ccaatt",
"cca.tt", // . 匹配除换行符以外的任意字符。
"cca[a,b,c,d,e]tt", // [] 字符类,匹配方括号中包含的任意字符。
"cc[^b,c,d,e]att", // [^] 否定字符类。匹配方括号中不包含的任意字符
"ccaa*tt", // * 匹配前面的子表达式零次或多次
"c+a+t+", // + 匹配前面的子表达式一次或多次
"cc?aatt?", // ? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。
// 此处说明一下,出现一次或零次的意思可以理解为?前面的字符可出出现可不出现
// 注意它与 * 的区别
"ccaat{1,2}", //{n,m} 花括号,匹配前面字符至少 n 次,但是不超过 m 次。
"(ccaatt)", //(xyz) 字符组,按照确切的顺序匹配字符xyz。
"(c(h|d|f)aatt)|(ccaatt)", // | 分支结构,匹配符号之前的字符或后面的字符。
// \ 转义符,它可以还原元字符原来的含义,允许你匹配保留字符 [ ] ( ) { } . * + ? ^ $ \ |
"^ccaatt", // ^ 匹配行的开始
"ccaatt$" // $ 匹配行的结束
};
for(int i = 0;i < patterns.size(); i++)
regs.push_back(regex(patterns[i]));
for(int i = 0;i < regs.size(); i++)
{
if(regex_match(s,regs[i]))
printf("use regex: %25s to match %10s [Match!]\n",patterns[i].c_str(),s.c_str());
else
printf("use regex: %25s to match %10s [Failed!]\n",patterns[i].c_str(),s.c_str());
}
}
void regex_search_test()
{
/* std::regex_search:
类似于regex_match,但它不要求整个字符序列完全匹配
可以用regex_search来查找输入中的一个子序列,
注意regex_search匹配成功一个后面的不再匹配
*/
string lines[] = {"Roses are #ff0000",
"violets are #0000ff",
"all of my base are belong to you"};
regex color_regex("#[a-f0-9]{2}""[a-f0-9]{2}""[a-f0-9]{2}");
// 简单匹配
for (const auto &line : lines) {
std::cout << line << ": " << std::boolalpha
<< std::regex_search(line, color_regex) << '\n';
}
std::cout << '\n';
// 展示每个匹配中有标记子表达式的内容
smatch color_match;
for (const auto& line : lines) {
if(regex_search(line, color_match, color_regex)) {
cout << "matches for '" << line << "'\n";
cout << "Prefix: '" << color_match.prefix() << "'\n";
cout << color_match[0] << '\n';
cout << "Suffix: '" << color_match.suffix() << "\'\n\n";
}
}
// 重复搜索(参阅 std::regex_iterator )
std::string log(R"( \
Speed: 366 \
Mass: 35 \
Speed: 378 \
Mass: 32 \
Speed: 400 \
Mass: 30)");
regex r(R"(Speed:\t\d*)");
smatch sm;
while(regex_search(log, sm, r))
{
std::cout << sm.str() << '\n';
log = sm.suffix();
}
// C 风格字符串演示
cmatch cm;
if(regex_search("this is a test", cm, regex("test")))
cout << "\nFound " << cm[0] << " at position " << cm.prefix().length() << endl;
}
void regex_replace_test()
{
std::string text = "{{ name }} for brown fox",replace_result;
std::regex double_brace("(\\{\\{) (.*) (\\}\\})");
//regex_replace返回值即为替换后的字符串
replace_result = regex_replace(text,double_brace,"*");
cout << replace_result << "\n";
//构造存有结果的字符串,[$&]即为用[]将匹配成功部分括起来
// $& Inserts the matched substring.
cout << regex_replace(text, double_brace, "[$&]") << '\n';
// $i则输出double_brace中第i个括号匹配到的值
cout << regex_replace(text, double_brace, "$1") << '\n';
cout << regex_replace(text, double_brace, "[$2]") << '\n';
cout << regex_replace(text, double_brace, "$3") << '\n';
}
int main ()
{
cout << "regex_match examples : " << endl;
regex_match_test();
cout << endl << "regex_search examples : " << endl;
regex_search_test();
cout << endl << "regex_replace examples : " << endl << endl;
regex_replace_test();
return 0;
}
总结
正则其实并不难,了解每个符号的意思后,自己马上动手试一试多写几次自然就明白了,正则是出了名的坑多,随便少写了个点就匹配不到数据了,我也踩了很多坑,踩着踩着就踩出经验了。
本文也只是对正则做了很基本的介绍,还有很多正则的字符没有介绍,只是写了比较常用的一些。如有错误之处,还望在评论中指出,我会马上修改。
附:常用的正则匹配工具
.
在线匹配工具:
http://www.regexpal.com/
http://rubular.com/
.
正则匹配软件
McTracer
