分组数据:
|| 为了前面提到使用聚集函数进行汇总操作,我们有时需要分组操作去配合数据汇总
|| 汇总数据和分组数据相互配合:
举个例子:汇总每个id下的有几行
SELECT c_id, COUNT(*) AS c_num
FROM bases
GROUP BY c_id
|| GROUP BY 子句指示MySQL按c_id 排序并分组数据,可以看作表被分成了子表,然后COUNT(*)返回每个子表的行数
|| 使用GROUP BY 后,聚集函数对每个组分别进行聚集,而不是对整个表进行聚集 (个人理解:可以把分组看成子表 )
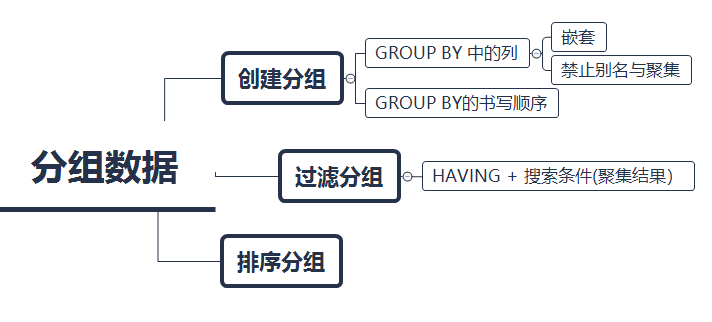
|| GROUP BY子句的使用规定:
|有关GROUP中的列:
|| GROUP BY可以包含多个列,以进行嵌套分组,聚集函数在最后一层嵌套进行聚集
|| SELECT检索的每个列都必须在GROUP BY中给出( 聚集语句除外)
|| GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(聚集函数除外),即不能使用别名。(如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式)。
|有关GROUP的顺序:
|| GROUP BY子句必须出现在WHERE过滤之后,HAVING过滤之前,ORDER BY排序子句之前。(因为GROUP子句包含有简单的排序功能!)
(我们使用WHERE来过滤行,过滤完行之后分组,再使用HAVING过滤分组最后使用ORDER BY)
注意:对于值为NULL的列,group会将它们分为一个组
|| 关键字: WITH ROLLUP, 得到分组和每个分组的汇总级别
过滤分组:
|| HAVING是可以排序分组的高配版WHERE。
我们使用HAVING子句来过滤分组,所有WHERE子句的句法都可以在HAVING中使用
|| HAVING子句与WHERE子句的区别:HAVING的是分组,WHERE过滤的是行
|| HAVING经常使用聚集函数作为过滤条件,举例:
SELECT c_id, COUNT(*) AS c_num
FROM bases
GROUP BY c_id
HAVING COUNT(*) >= 2;
GROUP中的排序功能:
|| 总之,不要依赖GROUP中的简单排序功能,需要排序时多搭配使用ORDER BY
举例:
SELECT c_id, COUNT(*) AS c_num
FROM bases
GROUP BY c_id
HAVING COUNT(*) >= 2;
ORDER BY c_id;
