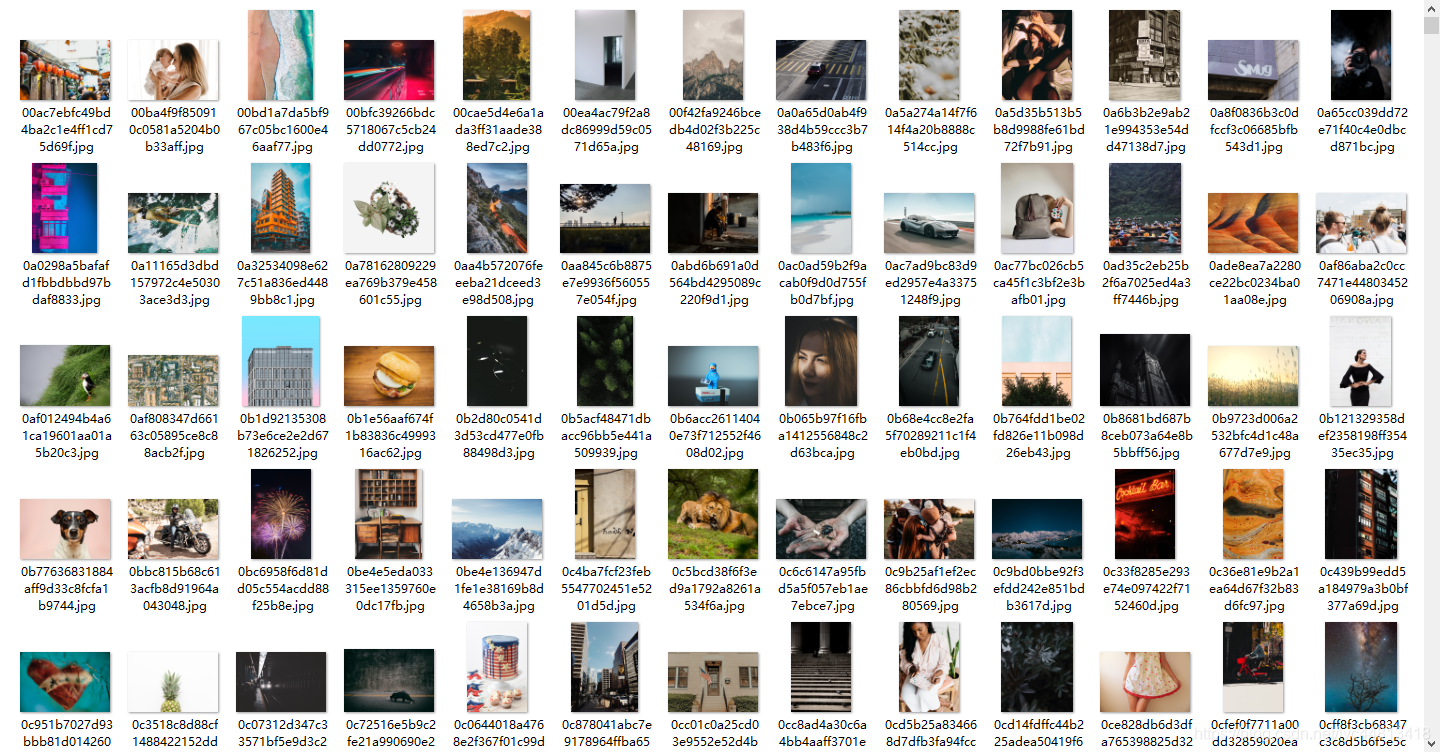
实战背景
近期准备参加一个隐写分析的比赛,unsplash是比赛训练数据集来源之一。Unsplash 是一个完全免费的、无版权的高清图片资源网站,里面的图片也是各式各样,分辨率也不错,觉得拿来做公众号的背景图片也是非常不错的选择,于是便动手实战一下图片爬取。

爬取方法一:Requests
- 进入图片网站,先按F12打开开发者工具,观察Network,滚动页面,向下翻页,可以发现下图photos?page=3&per_page=12
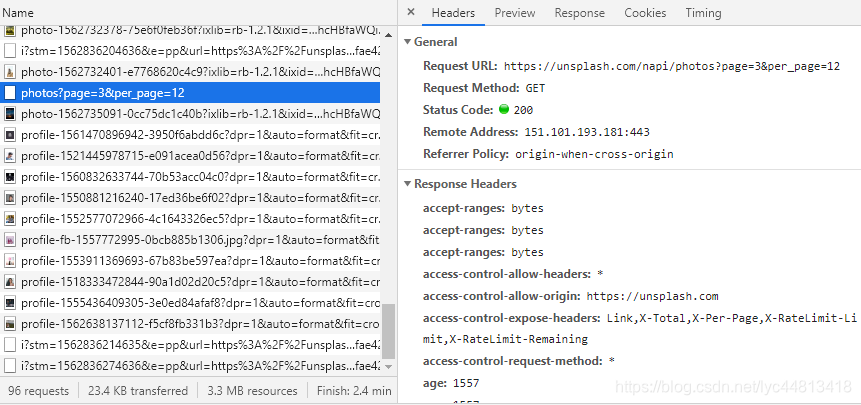
- 观察其request URL,从其构造不难看出每页12张图片,当前是第三页,继续下滑网页,发现出现photos?page=4&per_page=12,观察得到参数仅有page不同,也验证了猜想,接下来继续观察这个链接,不难发现,图片的下载链接就藏在其中。
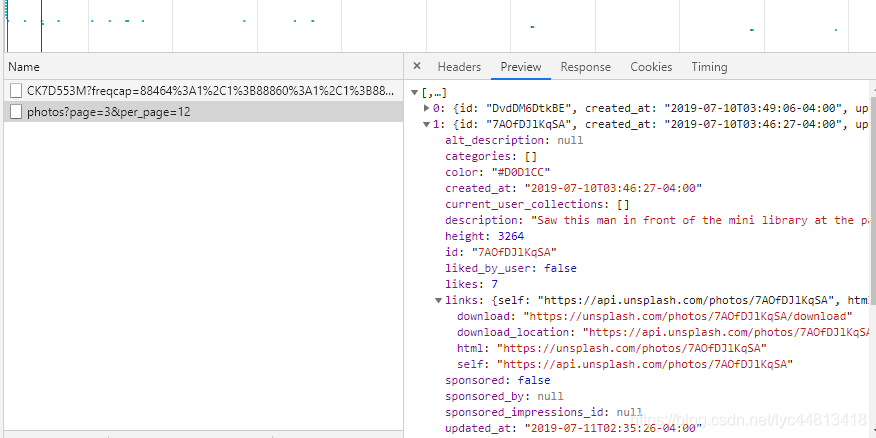
- 这个网页对新人爬虫还是非常友好的嘛!立马动手展开代码书写,只要在循环之中改变page的值就可以爬取整个网页的所有图片!
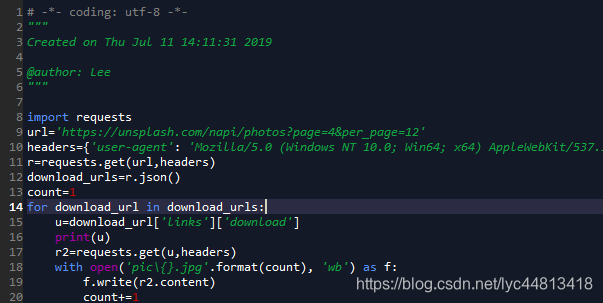
- 程序成功地运行!但是它的速度真是让人不敢恭维,一页12张图片都需要不少的时间代价,这10多万张图不得爬到猴年马月?于是我选择Scrapy框架来爬取图片。
爬取方法二:Scrapy
- 首先,与昨天相同输入命令建立工程,若不记得可以参看Scrapy实战。然后来编写各组件的代码:
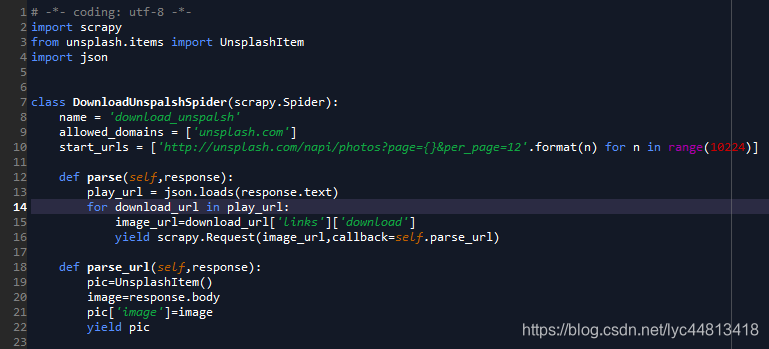
spider
- 这部分是爬虫的主要部分,start_urls设置了请求的网页链接,然后用到了json库将网页返回的内容变成json格式,提取出其中的图片下载链接。并且利用了scrapy.Request对unsplash网返回的内容进行二次解析,并将图片交给pipelines进行输出。
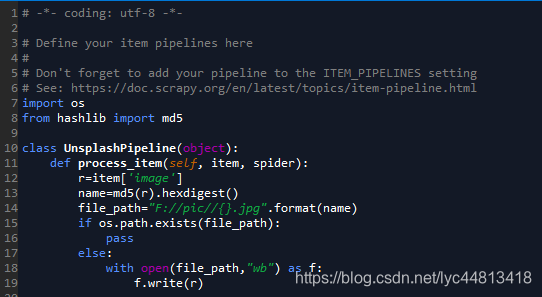
pipelines
- 这部分是进行图片的输出存储,利用了MD5生成摘要来给图片命名,这样可以完成去重存储。
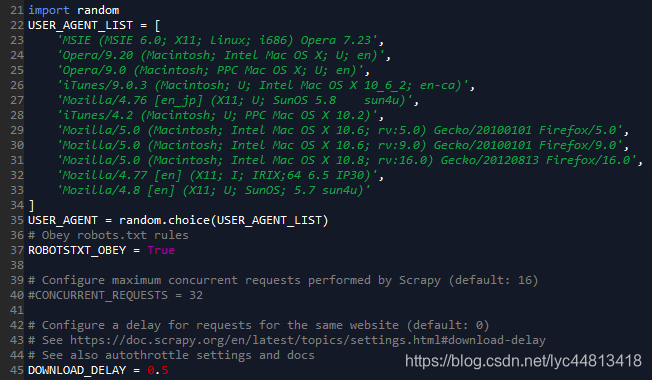
settings
- 既然对pipelines函数进行了编写,需要在settings.py中取消其注释,并且加上随机的代理头,加上一定的时延,来增强其假装浏览器的能力,当然也不要忘了在items.py中设置fields。
爬取结果
- 完成程序的编写之后,启动项目来看看成果,嗯,一大堆高清图片已收入囊中。