TCP/IP卷一:92---TCP拥塞控制之(基于延迟的拥塞控制算法)
其他
2020-02-17 11:16:53
阅读次数: 0
- 前面介绍的拥塞控制方法都是通过检测丢包、利用一些ACK或SACK报文探测、 ECN算法(如果可用)、重传计时器的超时来触发的。ECN算法允许一个TCP发送 端向网络报告拥塞状况,而不用检测丢包。但是这要求网络中每一个路由器的参与,比较 难以实现。然而,在没有ECN的情况下,判断网络中的主机是否发生拥塞也是可能的。当 发送端不断地向网络中发送数据包时,不断增长的虹丁值就可以作为拥塞形成的信号。我们在图16-8中看到过这种情况。新到达的数据包没有被发送,而是进人等待队列,这就造 成了RTT值不断增大(直到数据包最终被丢弃)。一些拥塞控制技术就是根据这种情况提出 的。它们被称为基于延迟的拥塞控制算法,与我们至今为止看到的基于丢包的拥塞控制算 法相对
一、Vegas算法
- TCP vegas算法于1994年被提出[BP95]。它是TCP协议发布后的第一个基于延迟的拥 塞控制方法,并经过了TCP协议开发组的测试。vegas算法首先估算了一定时间内网络能够 传输的数据量,然后与实际传输能力进行比较。若本该传输的数据并没有被传输,那么它有 可能被链路上的某个路由器挂起。如果这种情况持续不断地发生,那么Ⅵgas发送端将降低 发送速率。这与标准TCP中利用丢包来判断是否发生拥塞的方法相对。
- 在拥塞避免阶段,vegas算法测量每个RTT中所传输的数据量,并将这个数除以网络中 观察到的最小延迟时间。算法维护了两个阈值α和
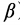 (α小于
(α小于 )。当吞吐量(窗口大小除以观察到的最小RTT)与预期不同时,若得到的吞吐量小于α,则将拥塞窗口增大;若吞吐量大于,则将拥塞窗口减小。吞吐量在两阈值之间时,拥塞窗口保持不变。拥塞窗口所有的改变都是线性的,这意味着这种方法是一种和式增加/和式减少( Additive Increase/Additive Decrease,AIAD)的拥塞控制策略。
)。当吞吐量(窗口大小除以观察到的最小RTT)与预期不同时,若得到的吞吐量小于α,则将拥塞窗口增大;若吞吐量大于,则将拥塞窗口减小。吞吐量在两阈值之间时,拥塞窗口保持不变。拥塞窗口所有的改变都是线性的,这意味着这种方法是一种和式增加/和式减少( Additive Increase/Additive Decrease,AIAD)的拥塞控制策略。
- 作者通过链路瓶颈处的缓冲区利用率来描述α和在α和月的最小值分别设置为1和30 设置该值的原因是:在网络中至少有一个数据包缓冲区会被占用(也就是说,路由器上的队 列表示网络链路上的最小带宽)才能保持网络资源被充分利用。如果Ⅵgas只维护一个缓冲 区,那么当有其他可用带宽时,就要等待额外的RTT时间。因此为了传输更多的数据,需 圃 要多使用两个缓冲区(达到3, α的值)。此外,保持一个区间(‘-α)可以保留一部分空间, 使得吞吐量可以有小幅改变而不至引发窗口大小的改变。这种缓冲机制可以减少网络的震荡
- 稍加修改后,这种方法也适用于慢启动阶段。这里,每隔一个RTT, CWnd值才随着一 个好的ACK响应而加10对于cwnd没有增长的RTT,需要测量吞吐量是否在增长。如果没 有,发送端将转为Ⅵgas拥塞避免方式。
- 在特定情况下, Ⅵgas算法会盲目地相信前向的延迟会高于它实际的值。这种情况发生 在它相反的方向产生了拥塞(回忆一下, TCP连接的两个方向的链路可能会不同,并产生不 同程度的拥塞状态)。在这种情况下,虽然不是发送端导致了(反向的)拥塞,但是返回发 送端的数据包(ACK.)会产生延迟。这就使得在这种不是真正需要调整拥塞窗口的情况下, 减小了窗日大小。这是大多数基于测量RTT来进行拥塞控制判断的方法所共有的潜在缺陷。 甚至,在反方向上严重的拥塞问题会导致ACK.时钟(图16-1 )的严重紊乱[M92]o
- vegas与其他的vegas TCP连接平等共用一条链路,因为每一次向网络中传输的数据量 都很小。然而, vegaS与标准TCP流共用链路时则是不平等的。标准TCP的发送端想要占满网络中的等待队列,反之Vegas则是想使它们保持空闲。因此,当标准TCP发送端发送数 据包时, Ⅵgas发送端会发现延迟在增长,那么它就会降低发送速率。最终,这导致了只对 标准TCP有利的状态o Linux系统支持Vegas,但不是默认开启的。对于2.6.13之前的内核 版本来说,布尔型sysctl变量net.ipv4.tcp_VegaS_COng_aVOid决定了是否使用Vegas (默认为 0 )。变量net.ipv4.tcp_VegaS_alpha (默认为2 )和变量net.ipv4.tcp_VegaS_beta (默认为6 )决 定了上面提到的α和〃值,但是它们的单位是半个数据包(也就是说, 6对应着3个数据包)。 变量net.ipv4.tcp_VegaS_gamma (默认为2 )用于配置在经过多少个半数据包后Vegas结柬慢 启动阶段。对于2.6.13之后的内核版本, Ⅵgas需要作为分离的内核模块被载人,通过设置 net.ipv4.tcp_COngeStion_COntrol来启动vegas
二、FAST算法
- FAST TCP算法是为处理大带宽延迟的高速网络环境下的拥塞问题而提出的[WJLHO6]。 原理上与vegas算法相同,它依据预期的吞吐量和实际的吞吐量的不同来调整窗日。与 Ⅵgas算法不同的是,它不仅依据窗日大小,而且还依据当前性能与预期值的不同来调整窗 困 日o FAST算法会使用速率起搏(rate-PaCing)技术每隔一个RTT都会更新发送率。如果测量 延迟远小于阑值时,窗日会进行较快增长,一段时间后会逐渐平缓增长。当延迟增大时则相 反o FAST算法与我们之前所说的方法不同,因为在其中包含了一些专利,并且它正被独立 地商业化o FAST算法被一些研究机构质疑缺乏安全性,但是一个评估报告[SO9]显示它具 有良好的稳定性和公平性0
三、TCP Westwood算法和Westwood+算法
- TCPWestwood算法(TCPW)和TCPWestwood+算法(TCPW+)的设计目的在于,通 过修改传统的TCP NewReno发送端来实现对大带宽延迟积链路的处理o TCPW +算法是对 TCPW算法的修正,所以这里只对TCPW算法进行说明。在TCPW算法中,发送端的合格 速率估计(ERE)是一种对连接中可用带宽的估计。类似Vegas算法(基于预期速率与实际 速率的差别),该估计值被不断计算。但是不同的是,对于这个速率的测量会有一个测量间 隔,该间隔基于ACK.的到达动态可变。当拥塞现象不明显时,测量间隔会比较小,反之亦 然。当检测到一个数据包丢失的时候, TCPW不会将cwnd值减半,而是计算一个估计的 BDP值(ERE乘以观察到的最小RTT),并将这个值作为新的ssthresh值。另一方面,在连 接处于慢启动阶段时,使用一种灵活的探测机制(Agile Probing) [WYSGO5]适应性地反复 设置ssthresh值。因此当ssthresh值增长时(由于初始的慢启动),CWnd值会以指数形式增长。 在Linux 2●6●13之后的内核版本中,可以通过加载一个TCPW模块,并设置net.ipv4.tcp_ congestion_COntrol为Westwood来启动Westwoodo
四、复合TCP
- 类似于Linux系统中的可装卸的拥塞避免模块,从Windows Vista系统开始,用户也可 以自主选择使用何种TCP拥塞控制算法。该选项(除了Windows Server 2008外,默认不开 启)称为复合TCP (Compound TCP, CTCP) [TSZSO6]o CTCP不仅依据丢包来进行窗日的 调整,还依据延迟的大小。可以认为它是一种标准TCP和vegas算法的结合,而且还包含了 HSTCP可扩展的特点。
- vegas算法和FAST算法的研究结果显示,基于延迟的拥塞控制方法可以得到更好的利 用率、更少的自诱导的丢包率、更快的收敛性(对于正确的操作来说),并且使RTT更具公 平性和稳定性。然而,就像前面提到过的,基于延迟的方法在与基于丢包的拥塞控制方法竟争时会失去优势o cTCP就是希望通过将基于延迟的方法和基于丢包的方法相结合来解决该 问题。为了达到这一目的, CTCP定义了一个新的窗口控制变量dwnd ( “延迟窗口”)。可用 窗口大小w则变成了

- 对cwnd值的处理与标准TCP类似,但是如果延迟允许,新加人的dwnd值会允许额外 的数据包发送。在拥塞避免阶段当ACK报文到达时, CWnd值根据下面的公式进行更新:
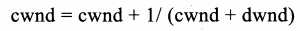
- dwnd值的控制是基于vegas算法的,并且只在拥塞避免阶段才是非零值( CTCP使用传 统的慢启动方式)。当连接建立时,使用一个变量baseRTT来表示测量到的最小RTT值。然 后预期数据与实际数据的差值d肿将使用如下公式进行计算‥ diff= W* (1一(baseRTT/RTT) )。 其中RTT是估算的(平滑的) RTT估计o d肿的值估算了网络队列中的数据包数量(或字节 数)。与大多数基于延迟的方法类似, CTCP算法试图将diff值保持在一个阑值内,以此保证 网络的充分利用而不至于出现拥塞,这个阑值定义为yo为了达到这一目的,对于dwnd值 的控制可依据以下公式:
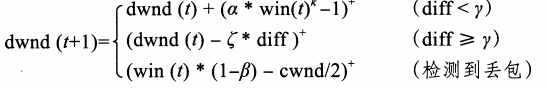
- 其中(X)+表示max (X, 0)。注意这里dwnd值非负。而当CTCP像标准TCP那样工作的时候, dwnd值应为00
- 在第一种情况下,网络没有被充分利用, CTCP根据多项式α*win(Dk增大dwnd 值。这是一种多项式级的增长,而当缓冲区的占用率小于y时,会更快速地增长(类似于 HSTCP)。在第二种情况下,缓冲区的占用率已经超过了阑值y,固定值‘表示延迟窗日的递 减速率(dwnd经常为cwnd的加数)。这就使得CTCP的RTT更具公平性。当检测到丢包时, dwnd值会有自已的积式递减系数仇
- 可以看到, CTCP需要使用参数亿、 α、生y和‘。居的值表示速度的等级。与HSTCP类 似,可以将居值设置为0.8,但是由于实现方面的原因,居值被设置为0.750 α和犀值表示了 平滑度和响应性,分别被默认设置为0.125和0.50对于y值,这里凭借经验将其设置为30个数据包。如果这个值太小,将不会有足够的数据包,以致不能得到较容易测量的延迟。相 反,如果这个值太大则会导致长时间的拥塞
- CTCP算法相对比较新,通过更深人的实验和改进,会使其与标准TCP相比拥有更好的 性能,并且能够很好地适应不同的带宽。在一个仿真实验中, [wO8]注意到在网络缓冲区较 小时(小于y值), CTCP算法的性能会很差。他们还提出CTCP也存在着一些Vegas算法中 的问题,包括重新路由问题(适应具有不同延迟的新链路)和持续的拥塞问题。他们发现, 如果有很多的CTCP流,其中每一个都要维护y个数据包,并且共用一条相同瓶颈的链路 时, CTCP的性能会非常差。
- 像前面所提到的, CTCP在大多数版本的Windows系统中不是默认开启的。然而,下面 的命令可以用来选择CTCP作为拥塞控制方法。

- 它可以通过另选一个不同的(或不设置)控制算洼来关闭o cTCP也作为一个可装卸式 的拥塞避免模块而移植到Linux系统中,当然它也不是默认启用的
发布了1463 篇原创文章 ·
获赞 996 ·
访问量 35万+
转载自blog.csdn.net/qq_41453285/article/details/104260951
