前言
跟着这一系列文章,好好了解一下TiDB。
(一)序
学习一种系统最好的方法是阅读一些经典著作并研究一个开源项目,数据库也不例外。
三篇前置文章:
这一系列文章会按照数据库的组件以及 SQL 处理的常见流程,讲解 Protocol 层,以及Parser、Preprocess、Optimizer、Executor、Storage Engine 等重要模块。从整体上分为两大部分,上半部分包括如下四篇文章:
第一篇文章介绍整体的架构,知道 TiDB 有哪些模块,分别是做什么的,从哪里入手比较好,哪些可以忽略,哪些需要仔细阅读。
第二篇文章从 SQL 处理流程出发,介绍哪里是入口,需要做哪些操作,知道一个 SQL 是从哪里进来的,在哪里处理,并从哪里返回。
第三篇文章从代码本身出发,介绍如何看懂某个模块的代码。
第四篇文章会引入一个例子,介绍如何让 TiDB 支持一个新的语法。
(二)初识 TiDB 源码
- 项目主页:TiDB
- main: tidb-server/main.go,编译策略在makefile中
sql 层架构:
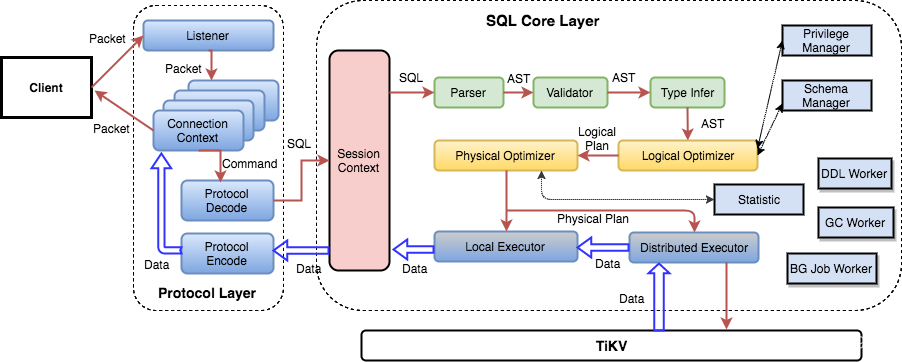
协议层
相关代码在 server 包中,支持 MySQL 协议,管理客户端 connection,解析 MySQL 命令并返回结果。
连接建立:server/server.go Run()
317: conn, err := s.listener.Accept()
364: go s.onConn(clientConn)
SQL 层
一条语句需要经过 语法解析、合法性验证、制定查询计划、优化查询计划、根据计划生成查询器、执行并返回结果 等一系列流程,对应 TiDB 的下列包:
| Package | 作用 |
|---|---|
| tidb | 协议层和sql层之间的接口 |
| parser | 语法解析 |
| plan | 合法性验证 + 制定查询计划 + 优化查询计划 |
| executor | 执行器生成以及执行 |
| distsql | 通过 TiKV Client 向 TiKV 发送以及汇总返回结果 |
| store/tikv | TiKV Client |
KV API 层
TiDB 是无状态的 sql 层,具体执行时需要依赖 kv 层的数据。TiKV 提供实现了接口的 Go 语言驱动,TiDB 利用这些接口操作底层数据。
服务器端调试启动的 TiDB,只使用了实现接口的 mocktikv,而不是真正的 tikv 。
(三)SQL 的一生
一条 sql 语句需要经过三个核心部分:
- 协议解析和转换,获得语句内容。这部分的所有逻辑在 server 包中,主要分为两块:
- 连接建立和管理。(本文暂不涉及)
- 单个连接上的处理逻辑。
- 经过 sql 核心层逻辑处理,生成查询计划。这部分有如下核心概念和接口:
- Session
- RecordSet
- Plan
- LogicalPlan
- PhysicalPlan
- Executor
- 在存储引擎中获取数据,进行计算。分为两块:
- KV 接口层,将请求路由到正确的 KV Server,接受返回消息传给 SQL 层;
- KV Server 的具体实现,这里用 Mock-TiKV 来代替 TiKV。
协议层
建议同时阅读文字与代码内容。
- 当与客户端建立连接后,会创建一个 goroutine 监听端口,不断循环等待从客户端发来的包,并对发来的包做处理,可以认为是 TiDB 的入口。
- 读取到包之后,会调用 dispatch 方法处理收到的请求。
- 进入 dispatch 方法,要处理的包是原始 byte 数组,按照 MySQL 协议,第一个 byte 表示命令的类型。然后根据命令类型,调用对应的处理函数,最常用的命令类型是
COM_QUERY(本文只介绍这个),它的处理函数是 handleQuery 。 - 在 handleQuery 中调用执行逻辑 Execute,在 Execute 中会调用另一个 Execute,它的实现在session/session.go 中,自此进入 SQL 核心层,具体内容在后面的章节中描述。
- 经过一系列处理,拿到 SQL 语句的结果后会调用 writeResultset 方法。这个方法按照 MySQL 协议的要求将结果格式化写回客户端,是协议层的出口。
server/server.go,建立连接:
func (s *Server) Run() error {
317: conn, err := s.listener.Accept()
364: go s.onConn(clientConn)
func (s *Server) onConn(conn *clientConn) {
463: conn.Run(ctx)
server/conn.go,监听端口,等待客户端发包,分发处理,返回结果:
func (cc *clientConn) Run(ctx context.Context) {
642: for {
652: data, err := cc.readPacket()
678: if err = cc.dispatch(ctx, data); err != nil {
func (cc *clientConn) dispatch(ctx context.Context, data []byte) error {
816: cmd := data[0]
869: return cc.handleQuery(ctx, dataStr)
func (cc *clientConn) handleQuery(ctx context.Context, sql string) (err error) {
1205: rss, err := cc.ctx.Execute(ctx, sql)
1219: err = cc.writeResultset(ctx, rss[0], false, 0, 0)
server/driver_tidb.go,具体执行
func (tc *TiDBContext) Execute(ctx context.Context, sql string) (rs []ResultSet, err error) {
248: rsList, err := tc.session.Execute(ctx, sql)
SQL 层 - 总览
注:这部分文章内容和代码内容在实现上有较大差异,但核心思想仍然相同。
session/session.go
func (s *session) Execute(ctx context.Context, sql string) (recordSets []sqlexec.RecordSet, err error) {
1066: if recordSets, err = s.execute(ctx, sql); err != nil {
func (s *session) execute(ctx context.Context, sql string) (recordSets []sqlexec.RecordSet, err error) {
1084: stmtNodes, warns, err := s.ParseSQL(ctx, sql, charsetInfo, collation)
1112: stmt, err := compiler.Compile(ctx, stmtNode)
1130: if recordSets, err = s.executeStatement(ctx, connID, stmtNode, stmt, recordSets, multiQuery); err != nil {
- ParseSQL 将查询字符串翻译为抽象语法树 AST;
- Compile 把 AST 转换为物理计划(存储在 executor.ExecStmt 中);
- executeStatement 获得结果集(不一定真正执行查询)。
SQL layer - Parse
session/session.go
func (s *session) ParseSQL(ctx context.Context, sql, charset, collation string) ([]ast.StmtNode, []error, error) {
984: return s.parser.Parse(sql, charset, collation)
parser/yy_parser.go (注:此处的 parser 并非项目 pingcap/tidb 下的包,而是单独位于项目 pingcap/parser 中。)
func (parser *Parser) Parse(sql, charset, collation string) (stmt []ast.StmtNode, warns []error, err error) {
141: yyParse(l, parser)
parser/parser.go
9161: func yyParse(yylex yyLexer, parser *Parser) int {
// 自动生成的代码
Parser 模块由 Lexer 和 Yacc 两个组件共同构成,可以将文本解析成结构化数据,即抽象语法树(AST)。
解析过程中,先用 lexer 不断将文本转换为 token,交付给 parser, parser 是根据 yacc 语法生成,根据语法不断决定 lexer 中发来的 token 序列可以匹配哪条语法规则,最终输出结构化的节点。
所有的语句的结构都能被抽象为一个 ast.StmtNode。大部分 parser/ast 包中的数据结构,都实现了 ast.Node 接口,这个接口有一个 Accept 方法,后续对 AST的处理,主要依赖这个 Accept 方法,以 Visitor 模式遍历所有节点以及对 AST 做结构转换。
看的晕吗?我也是,第五篇会再说这个话题。
总之,parser 最终会返回一个 []ast.StmtNode,代表抽象语法树。
(这里可能一个 StmtNode 表示一个 AST,即一个查询,而数组代表多重查询)
SQL layer - 制定查询计划及优化
executor/compiler.go
func (c *Compiler) Compile(ctx context.Context, stmtNode ast.StmtNode) (*ExecStmt, error) {
57: if err := plannercore.Preprocess(c.Ctx, stmtNode, infoSchema); err != nil {
61: finalPlan, names, err := planner.Optimize(ctx, c.Ctx, stmtNode, infoSchema)
71: return &ExecStmt{
InfoSchema: infoSchema,
Plan: finalPlan,
LowerPriority: lowerPriority,
Cacheable: plannercore.Cacheable(stmtNode),
Text: stmtNode.Text(),
StmtNode: stmtNode,
Ctx: c.Ctx,
OutputNames: names,
}, nil
上面列出的三行分别代表三个重要步骤:
- Preprocess 做合法性检查及名字绑定
- Optimize 制定查询计划并优化,是最核心的步骤之一(也是我早就该看的内容)
- 返回构造的 ExecStmt 结构,其持有查询计划,是后续执行的基础,非常重要。ExecStmt 有一个 Exec 方法,更加重要!(为什么?)
SQL layer - 生成执行器
session/session.go
func (s *session) executeStatement(...) ([]sqlexec.RecordSet, error) {
1027 recordSet, err := runStmt(ctx, s, stmt)
session/tidb.go
func runStmt(...) (rs sqlexec.RecordSet, err error) {
275: rs, err = s.Exec(ctx)
executer/adapter.go
283: // 根据 plan 构造执行器。
284: // 如果执行器无需返回结果(如 insert, update),就在此函数中执行
285: // 如果需要返回结果,会在函数返回的 sqlexec.RecordSet 的 Next 方法中执行
func (a *ExecStmt) Exec(ctx context.Context) (_ sqlexec.RecordSet, err error) {
377: return &recordSet{
executor: e,
stmt: a,
txnStartTS: txnStartTS,
}, nil
在这个过程中,会将 plan 转换成 executor,执行引擎就可以用其执行之前定下的查询计划。
生成的执行器会被封装在一个 recordSet 中,代表了查询结果集的抽象:
executer/adapter.go
type recordSet struct {
fields []*ast.ResultField
executor Executor
stmt *ExecStmt
lastErr error
txnStartTS uint64
70: func (a *recordSet) Fields() []*ast.ResultField {
// Next 使用 recordSet 的执行器得到下一个可用块,以便之后使用。
// 如果块不包含任何行,则我们将会话变量中的最后一个查询找到的行更新为当前找到的行。
// 我们需要更新的原因是0行的块代表已经完成了当前查询,需要为下一个查询做准备。
// 如果 stmt 非空且块中有一些行,我们只需按块中的行数更新上一次查询找到的行。
116: func (a *recordSet) Next(ctx context.Context, req *chunk.Chunk) (err error) {
126: err = Next(ctx, a.executor, req) // 见下文执行器部分
145: func (a *recordSet) NewChunk() *chunk.Chunk {
149: func (a *recordSet) Close() error {
简单地说,可以调用 Fields 方法获得结果集每一列的类型,调用 Next 方法可以获得一块数据, 调用 Close 会关闭结果集。
SQL layer - 运行执行器
对于 Insert 这种不需要返回数据的语句,只需要把语句执行完成,也通过 Next 驱动执行,驱动点在构造 recordSet 之前:
executer/adapter.go
func (a *ExecStmt) Exec(ctx context.Context) (_ sqlexec.RecordSet, err error) {
365: if handled, result, err := a.handleNoDelay(ctx, e, isPessimistic); handled {
return result, err
}
func (a *ExecStmt) handleNoDelay(...) (bool, sqlexec.RecordSet, error) {
397: r, err := a.handleNoDelayExecutor(ctx, e)
func (a *ExecStmt) handleNoDelayExecutor(...) (sqlexec.RecordSet, error) {
518: err = Next(ctx, e, newFirstChunk(e))
executer/executer.go
// Next 是一个 e.Next() 的包装函数,处理一些公共逻辑。
func Next(ctx context.Context, e Executor, req *chunk.Chunk) error {
212: return e.Next(ctx, req) // 按执行器类型分发给具体执行器(多态)
func (e *CancelDDLJobsExec) Next(ctx context.Context, req *chunk.Chunk) error {
func (e *ShowNextRowIDExec) Next(ctx context.Context, req *chunk.Chunk) error {
func (e *ShowDDLExec) Next(ctx context.Context, req *chunk.Chunk) error {
...
而对于需要返回数据的语句如 select, 会将 recordset 一路返回,直到
server/conn.go
func (cc *clientConn) handleQuery(ctx context.Context, sql string) (err error) {
1219: err = cc.writeResultset(ctx, rss[0], false, 0, 0)
// 数组仍用于多重查询返回的多个结果。
// 将数据写入结果集中,并使用 rs.Next 取回行数据
func (cc *clientConn) writeResultset(..., rs ResultSet, ...) (runErr error) {
1311: err = cc.writeChunks(ctx, rs, binary, serverStatus)
// 有另一个带有 fetchSize 的 writeChunks,即设置了单次读取的缓存空间。
func (cc *clientConn) writeChunks(...) error {
1343: for {
1345: err := rs.Next(ctx, req)
TiDB 的执行引擎以 Volcano 模型运行,所有的物理 Executor 构成一个树状结构,每一层通过调用下一层的 Next 方法获取结果。
假设语句是 SELECT c1 FROM t WHERE c2 > 1;,且查询计划是全表扫描+过滤,那么执行器树会是下面这样:
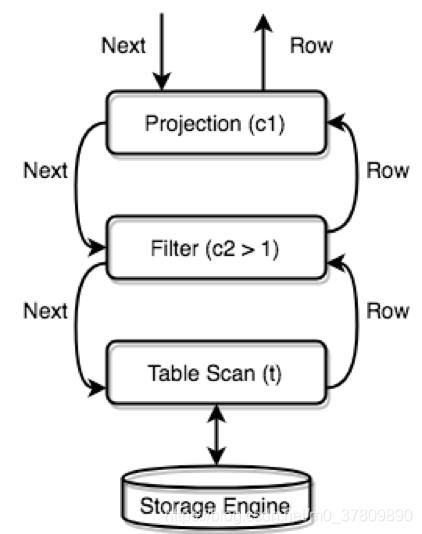
总结
第三篇描述了整个 SQL 层的执行框架,用一幅图来总结整个过程:
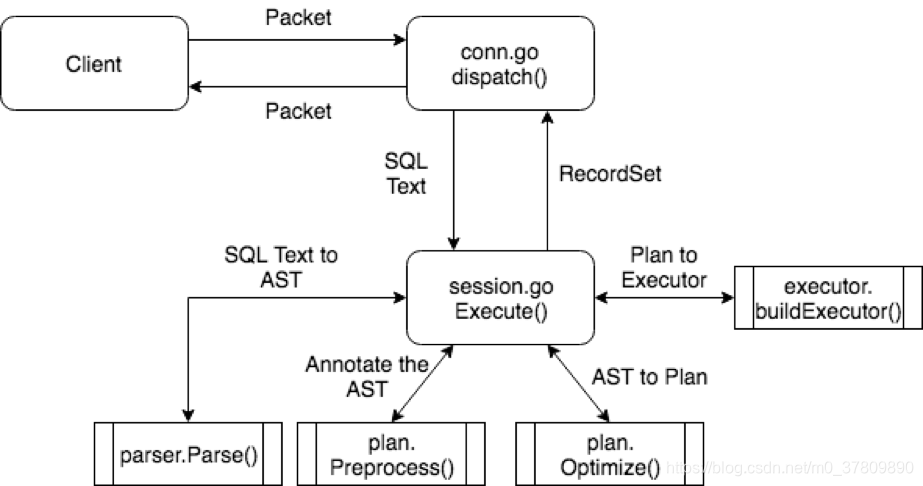
太硬核了。
之后的文章会用具体语句为例,辅助理解本篇文章。
数据库操作记录
- 连接 tidb 的命令是
mysql -h 127.0.0.1 -P 4000 -u root - 建表
CREATE TABLE t ( id VARCHAR(31), name VARCHAR(50), age int, key id_idx (id) ); - 插入
INSERT INTO t VALUES ("pingcap001", "pingcap", 3); - 查询
SELECT * FROM t WHERE age > 1;
