
Spark Streaming:Spark提供的,对于大数据进行实时计算的一种框架;它的底层,也是基于Spark Core的;
其基本的计算模型,还是基于内存的大数据实时计算模型RDD,只不过,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStream(类似Spark SQL中的DataFrame);所以RDD是整个Spark技术生态的核心。
Spark Streaming是Spark Core Api的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理;支持从很多种数据源中读取数据,比如Kafka、Flume、Twitter、ZeroMQ、Kinesis或者TCP Socket,并且能够使用类似高阶函数的复杂算法来进行数据处理,比如map、reduce、join、window;处理后的数据可以被保存到文件系统、数据库、Dashboard等存储中
DStream

所谓DStream,用中文来说就是离散数据流。上面是源码中DStream类的一段注释。它说是SparkStreaming里面一系列RDD的基本抽象。DStream是一个时间上连续接收数据但是接受到的数据按照指定的时间(batchInterval)间隔切片,每个batchInterval都会构造一个RDD,因此,Spark Streaming实质上是根据batchInterval切分出来的RDD串,想象成糖葫芦,每个山楂就是一个batchInterval形成的RDD。我来理解就是同一空间内不同时间内的数据流。
看这个官网来的图片,它所显示的应该是在time1来了一个RDD,而在time2来了一个RDD.......在time4又来了一个RDD
所谓同一空间就是指专门接收RDD的这个东东,比如一个DStream对象对吧,而不同时间很明显了,就是time1,time2.....
它有很多的数据来源,可以有实时数据,比如TCP Socket,flume,kafka等等。上面还解释了,在SparkStreaming运行时,DStream要么从实时数据中来,要么从父DStream通过算子操作而来
A DStream internally is characterized by a few basic properties:
- A list of other DStreams that the DStream depends on
- A time interval at which the DStream generates an RDD
- A function that is used to generate an RDD after each time interval看清楚这个。DStream有下面几个特性。
- DStream依赖于其他的一些DStream
- 在一个时间间隔内,产生一个DStream
- 时间间隔之后,可以有函数作用在上面。
上面一些官网的东西。
其实要做到实时,个人感觉sparkStreaming并不是真正的实时,它知识将数据按时间片切分,分批接收处理,而我们平时使用sparkCore计算,无非就是一次性读入大批数据计算。sparkStreaming做的实时应该是微批处理。
至于storm和Flink暂时还没学,以后学了做个比较吧。

一个小例子
class quick {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf,Milliseconds(5000));
val lines = ssc.socketTextStream("114.55.37.70", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}先用scala写个很简单的wordcount例子。这里涉及到了几个对象。
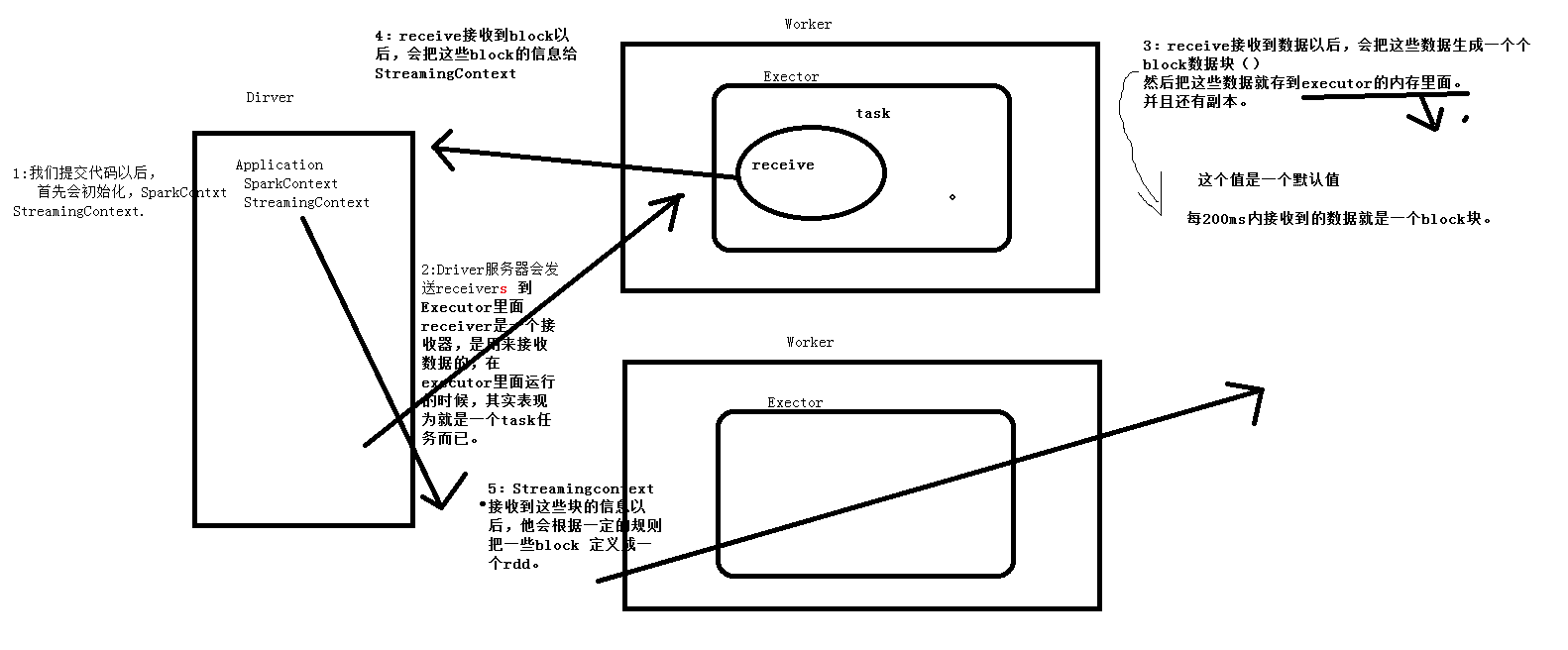
这个图是工作的模型
conf是SparkConf的实例,是SparkCore的基本对象,对吧,这个不用怀疑
ssc是StreamingConttext的实例,那这个StreamingContext是啥呢。
执行的源码图
StreamingContext
要初始化Spark Streaming程序,必须创建StreamingContext对象,该对象是所有Spark Streaming功能的主要入口点。
定义StreamingContext后,您必须执行以下操作。
- 通过创建输入DStream定义输入源。
- 通过将转换和输出操作应用于DStream来定义流计算。
- 开始接收数据并使用进行处理
streamingContext.start()。 - 等待使用停止处理(手动或由于任何错误)
streamingContext.awaitTermination()。 - 可以使用手动停止处理
streamingContext.stop()。
要记住的要点:
- 一旦启动StreamingContext,就无法设置新的流计算或将其添加到该流计算中。
- StreamingContext一旦停止,就无法重新启动。
- JVM中只能同时激活一个StreamingContext。
- StreamingContext上的stop()也会停止SparkContext。要仅停止的StreamingContext,设置可选的参数
stop()叫做stopSparkContext假。 - 只要在创建下一个StreamingContext之前停止了上一个StreamingContext(不停止SparkContext),就可以将SparkContext重用于创建多个StreamingContext。
InputDStream和接收器
InputDStream是表示从流源接收的输入数据流的DStream
比如从kafka读就有kafkaInputDStream。
每个输入DStream(文件流除外,本节稍后将讨论)都与一个Receiver对象关联,该对象从源接收数据并将其存储在Spark的内存中以进行处理。
Spark Streaming提供了两类内置的流媒体源。
- 基本来源:可直接在StreamingContext API中获得的来源。示例:文件系统和套接字连接。
- 高级资源:可以通过其他实用程序类获得诸如Kafka,Flume,Kinesis等资源。如链接部分所述,它们需要针对额外的依赖项进行 链接。
请注意,如果要在流应用程序中并行接收多个数据流,则可以创建多个输入DStream(在“ 性能调整”部分中进一步讨论)。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark工作程序/执行程序是一项长期运行的任务,因此它占用了分配给Spark Streaming应用程序的核心之一。因此,重要的是要记住,必须为Spark Streaming应用程序分配足够的内核(或线程,如果在本地运行),以处理接收到的数据以及运行接收器。
-
在本地运行Spark Streaming程序时,请勿使用“ local”或“ local [1]”作为主URL。这两种方式均意味着仅一个线程将用于本地运行任务。如果您使用基于接收方的输入DStream(例如套接字,Kafka,Flume等),则将使用单个线程来运行接收方,而不会留下任何线程来处理接收到的数据。因此,在本地运行时,请始终使用“ local [ n ]”作为主URL,其中n >要运行的接收器数(有关如何设置主服务器的信息,请参见Spark属性)。
-
为了将逻辑扩展到在集群上运行,分配给Spark Streaming应用程序的内核数必须大于接收器数。否则,系统将接收数据,但无法处理它。
搭配kafka写一个wordcount
之前学了一些kafka,所以现在来一起来使用一些。这里没有搭建spark,spark采用本地吧。
object DirectWord {
def main(args: Array[String]): Unit = {
//创建SparkConf
val conf = new SparkConf().setAppName("wordCount2").setMaster("local[5]")
val streamingContext = new StreamingContext(conf,Seconds(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "114.116.199.154:5008,114.116.219.197:5008,114.116.220.98:5008",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("hi")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(_.value())
.flatMap(_.split(" "))
.map(x => (x,1))
.reduceByKey(_ + _)
.transform(data =>{
val sortdata = data.sortBy(_._2, false)
sortdata
})
.print()
// stream.foreachRDD { rdd =>
// val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// rdd.foreach(record => {
// println(record.key() + ":::" + record.value())
// val lines = record.value();
// val words = lines.split(" ")
// val wordnum = words.map(s => (s,1))
// wordnum.foreach(
// rs =>
// println(rs)
// )
//// wordnum.reduce((x,y) => x+y).var
// }
// )
// rdd.foreachPartition { iter =>
//
// val o: OffsetRange = offsetRanges(TaskContext.get.partitionId)
// println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
// }
// }
streamingContext.start()
streamingContext.awaitTermination()
}
}
