前言
今天回北京后打开电脑工作的同时也抽出时间更新本期文章,给大家讲讲我们开发的爬虫系统。很多朋友问过我现在爬虫行业前景怎么样?而今互联网行业无论从事哪个方向,知识的碎片化难以在某个领域深耕。
做技术最忌讳杂而不精、技术的深度通常是工作驱动的,技术的广度通常是兴趣驱动的
拿爬虫领域来说根据自身面试经历以及身边很多爬虫领域大佬的讲述,大部分企业要求有爬虫系统、爬虫产品的开发经验。
这是为何呢?有过爬虫系统及产品研发的工程师证明你在爬虫这个领域的技术综合能力是有深度的,从而也将导致你的待遇水涨船高!而今眼目下单一爬虫开发的需求已经不能满足大部分企业的需求,垂直爬虫开发人员的招聘如果站在一个企业的角度它在时间、成本上是不能满足长期刚需的。
不管是对想从事爬虫工作的小伙伴还是爬虫工程师们来说,目前网上关于爬虫领域的文章,大多都停留在表面,聊来聊去还是那些东西,新手一看就会、老手早已知晓。已经很久没有一些实质性的内容了。
一、怎么设计爬虫系统?
面对每天写不完的parse、工作量最大的xpath是每一位爬虫工程师的痛。将整个爬虫领域知识结合起来打造自己的一把利器,不仅能在工作中省时省力、技术上突飞猛进、更重要的是能帮你斩获无数企业的offer
技术那是信仰
不要用996的无用功、代替战略上的失败
该怎么做呢?首先设计整个爬虫系统的架构(合格的工程师设计能力还是有的、更何况属于自己深耕的领域),只要整个架子搭起来了后续的工作那无非就是踩坑、搬砖。
熟悉爬虫的小伙伴都知道爬虫系统肯定势必要跟任务、监控、节点、可视化挂钩。所以一套爬虫系统的基础架构可分四个基本功能模块跟以下多个子功能模块:
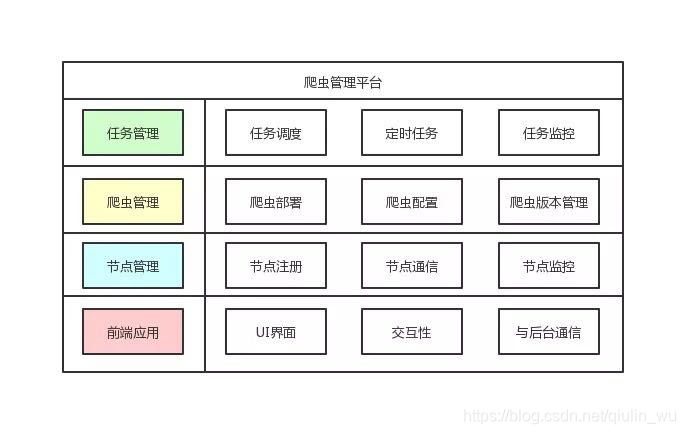
很多小伙伴尤其爬虫工程师们都想了解的重点是这套系统里面的那些模块都会用到了哪些技术栈。关于一套爬虫系统所覆盖的所有技术点并不是我这一篇文章能写完的,在这里呢~我简单描述一下吧:
任务管理:大家看看Scrapyd(网上Scrapyd有深度的文档寥寥无几,后续我会给它开一篇专场)
节点管理:Docker、K8s技术了解一下?
这些后期我都会开一篇专场的--------------------进入今天的主题吧:
那年!一群同道合的爬虫工程师在一起,面对网站页面的改版、面对老生常谈的去重、面对黑盒状态的爬虫、面对冗余的开发量等一系列问题。正式开启了一段新的征程:爬虫系统的研发。
项目部分源码:
这是我们目前系统的主界面:
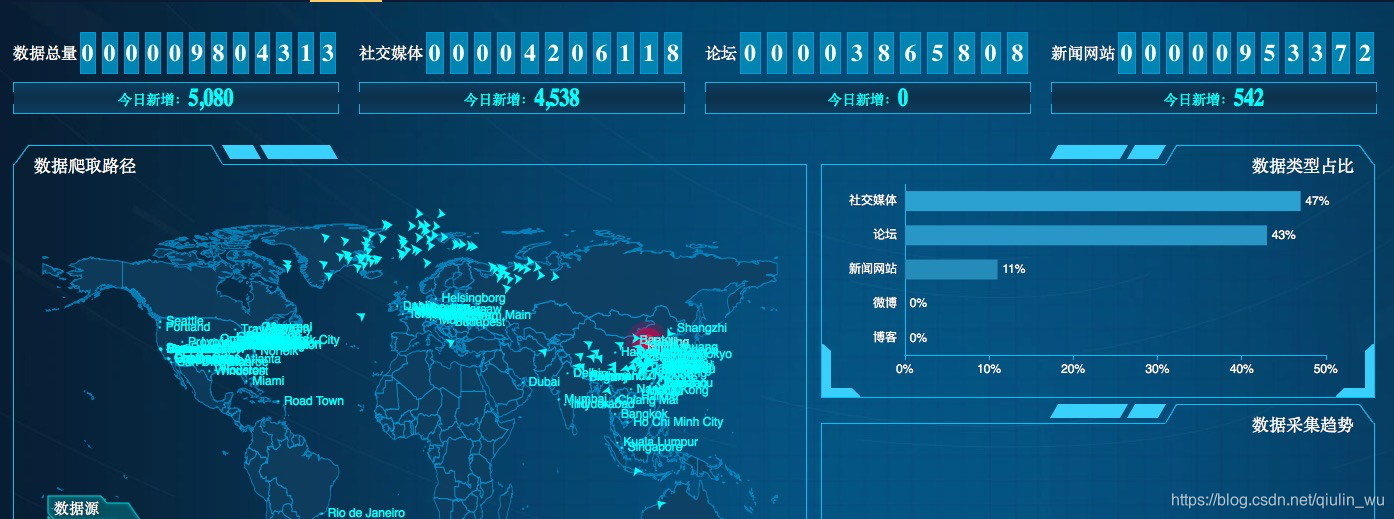
炫酷的页面包含了整个系统内所有爬虫的动向、数据动态等展示
二、爬虫管理
爬虫管理里面包含爬虫工程的管理、爬虫定制及爬虫版本的管理。
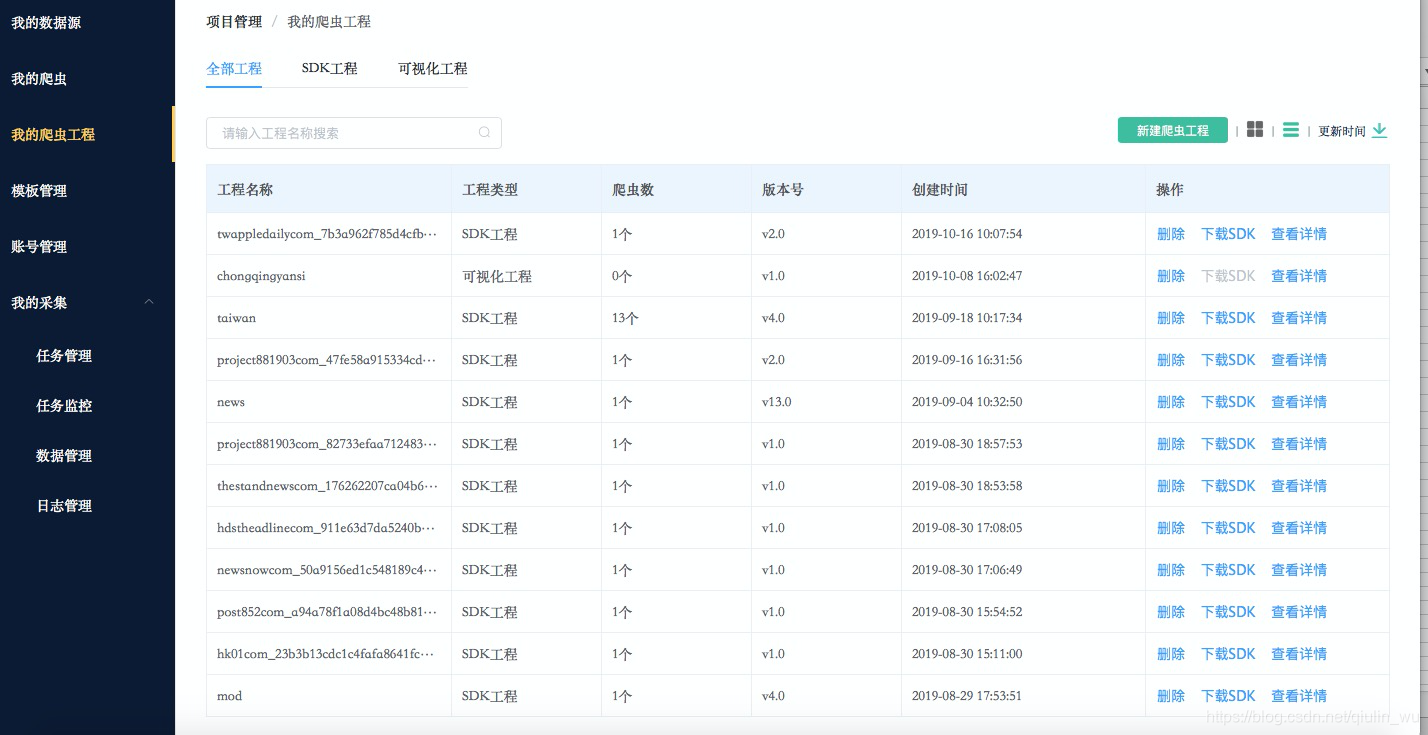
图中SDK工程是为爬虫开发工程师们定制的Scrapy爬虫工程上传功能,整套系统将作为爬虫运行的载体,提供运行节点、爬虫监控及预警。而可视化工程是针对比如不懂爬虫技术的测试人员以及新手工程师们准备的所见即所得的爬虫可视化定制功能,只需要输入网站URL用鼠标选中需要爬取的信息,自定义存储字段系统将自动生成Scrapy工程代码,可以直接部署到系统运行。
另外我们有一个针对新闻网站的模版管理,开发人员只需要输入新闻网站起始URL,然后就是手写一些Xpath生成Scrapy工程
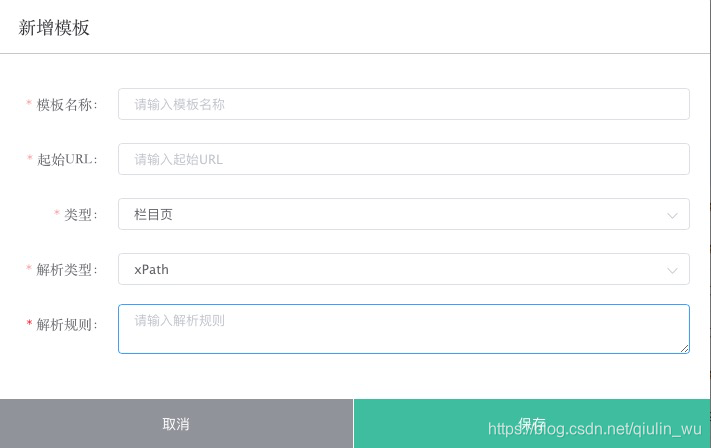
三、任务管理
任务管理模块一般包含:任务调度、任务监控、定时任务等功能。
创建爬虫任务界面
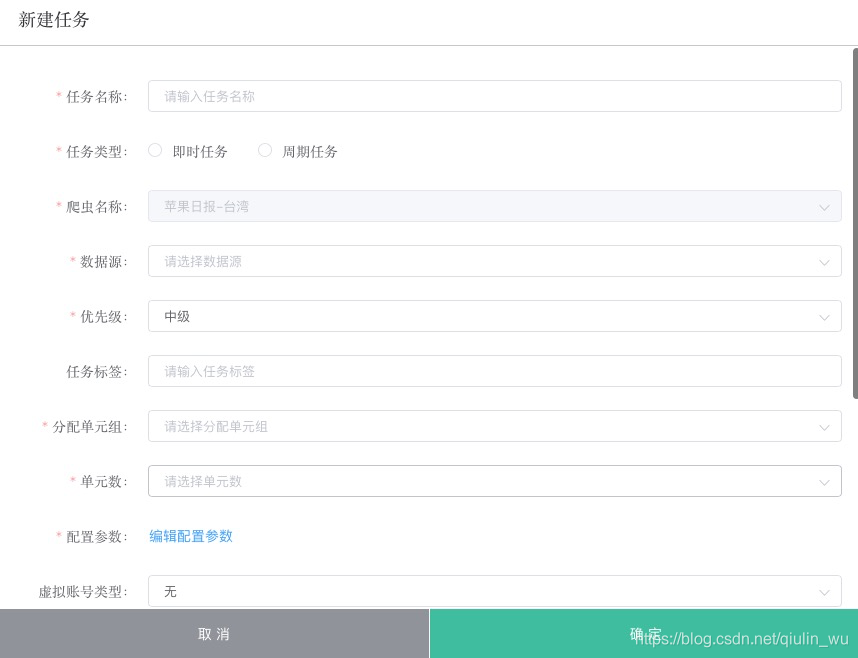
任务管理页面
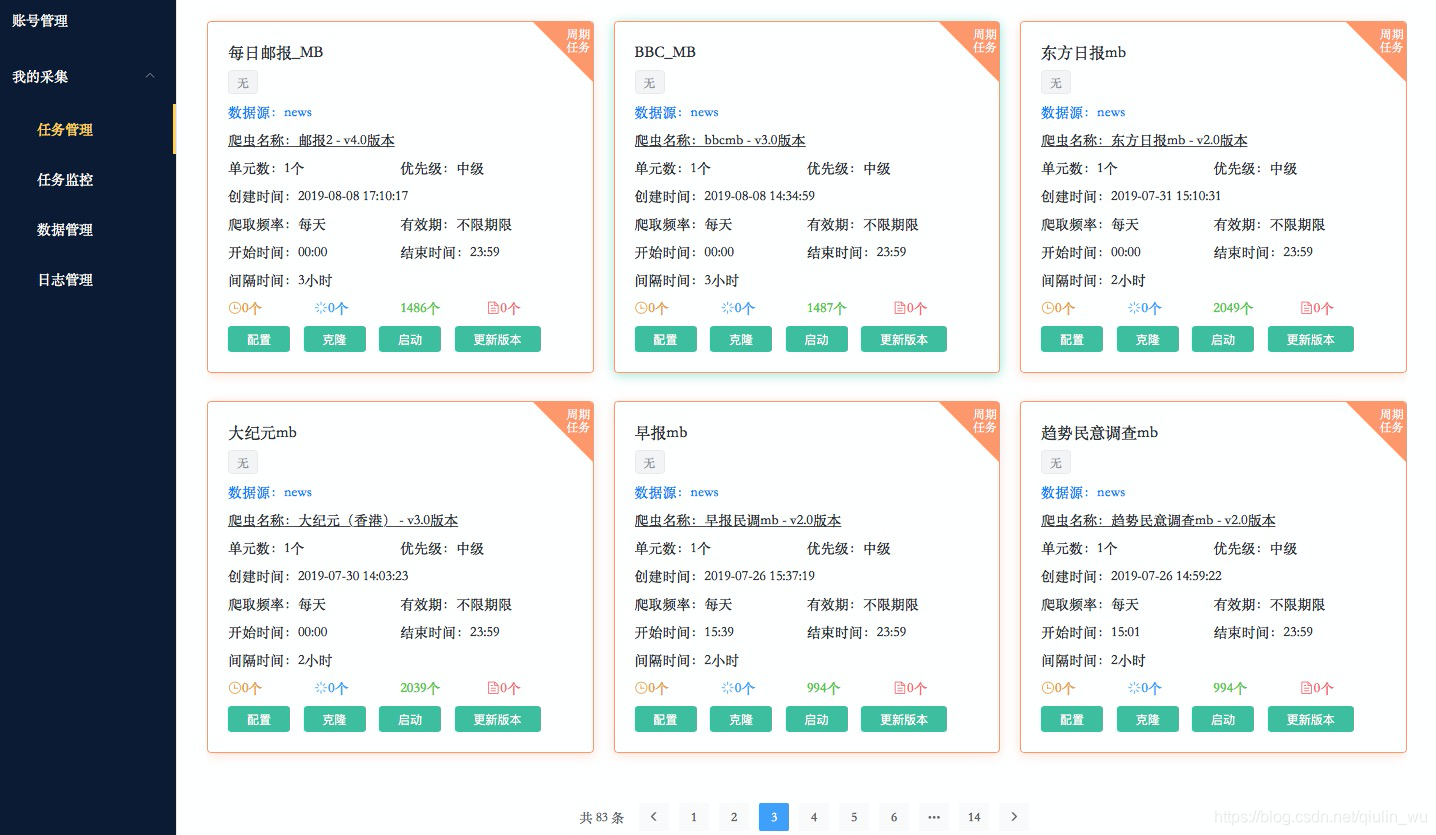
包括当前用户下所有创建的爬虫任务(分为一次性任务跟定时任务)
四、任务监控
任务监控模块包含:排队任务、正在执行任务、已完成任务等功能。
加粗样式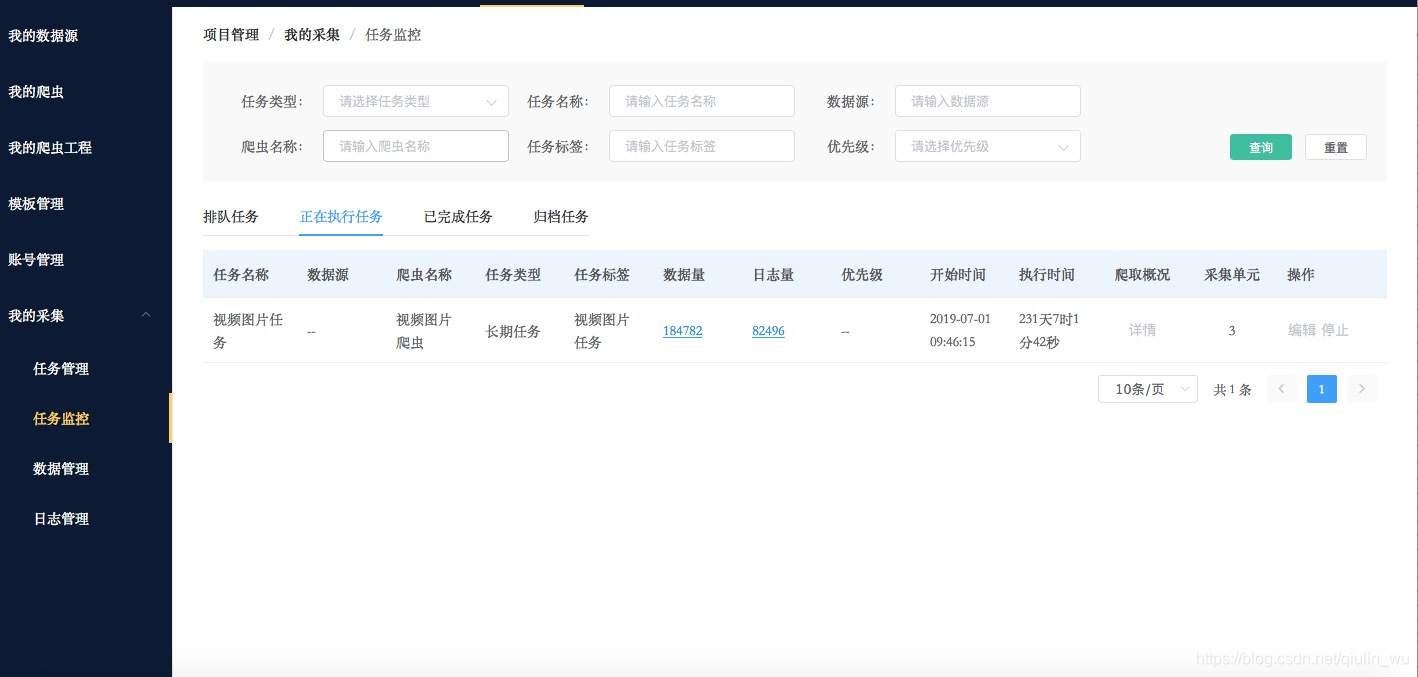
排队任务:采集队列中等待采集的爬虫任务、多节点采集时运行中的爬虫任务完成以后节点自动释放再去任务队列拉取新的任务
正在执行任务:正在运行的爬虫,实时数据展示、日志预警等
那么、你希望它开源吗?
谢谢大家能抽出宝贵的时间阅读,创作不易,如果您喜欢的话,给君君点个关注再走吧~您的支持是我创作的动力,希望今后能带给大家更多优质的文章。
