质检
【车道任务】
别人已经做好的数据,需要对其进行审核。
导入json文件,进行审核。
可能会有漏标情况,补线并保存,但 #Labels 数量不会进行更新。
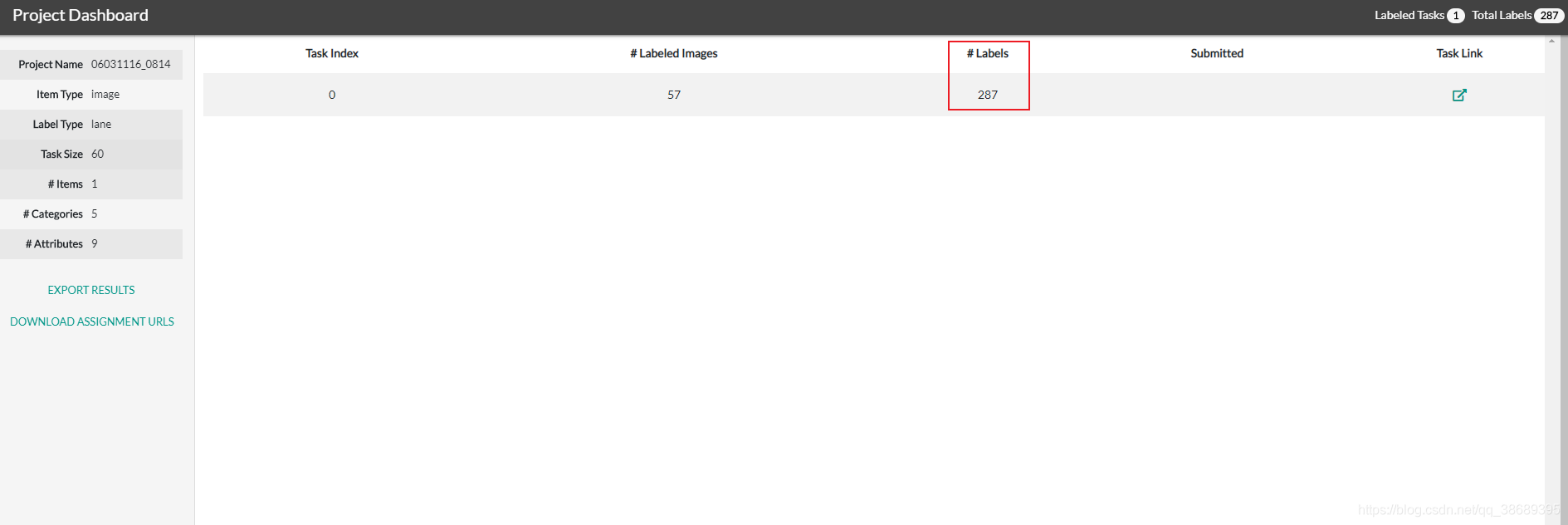
【进行确认】
这里我新增了2条车道线
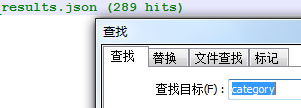
导出 json文件,查找 *Categories(类别)中的唯一类别属性 *category(每新增一个线值就会加一),确定更改后的 #Labels数量为 289(图片上#Labels数量为287)
【结论】
Scalabel只会统计 导入的json文件 #Label数量。
【解决方法】
- 用notepad查询
*category数量 - 重新导入更改后的json文件,查看
#Labels数量 - 写个小程序 一劳永逸提取
*category数量
# _*_coding:utf-8
import re
import os
from openpyxl import Workbook
from openpyxl.styles import Font
def list_text(name):
os.chdir(path)
count = 0
files = os.listdir(path)
for file in files:
#统计josn文件中'category'的数量
json = open(file,'r',encoding='utf-8').read()
for ch in '|"!@#$%^&*()_=+-/,:;"<>?\\`[]{|}.~':
json = json.replace(ch," ")
# json = json.lower()
words = json.split()
counts = {}
for word in words:
#.get(word,0) 如果键不在字典,加到字典赋值为0 并+1;如果键在字典中,返回次数 并+1
counts[word] = counts.get(word,0)+1
try:
num_label = counts['category']
#按格式筛选出一级和二级文件夹名称
pattren1 = re.compile('(.*?)%')
soltlist1 = pattren1.findall(file)
pattren2 = re.compile('%(.*?)#')
soltlist2 = pattren2.findall(file)
for solt1 in soltlist1:
for solt2 in soltlist2:
seq = solt1,solt2,str(num_label)
name.write('\t'.join(seq) + '\n')
count += 1
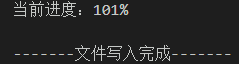
print('\r当前进度:{:.0f}%'.format(count * 100 / len(files)),end="")
#没有category的情况
except KeyError:
pattren1 = re.compile('(.*?)%')
soltlist1 = pattren1.findall(file)
pattren2 = re.compile('%(.*?)#')
soltlist2 = pattren2.findall(file)
for solt1 in soltlist1:
for solt2 in soltlist2:
seq = solt1,solt2,'0'
name.write('\t'.join(seq) + '\n')
count += 1
print('\r当前进度:{:.0f}%'.format(count * 100 / len(files)),end="")
def to_text():
#txt输出的目录
outfile = './labels_num.txt'
name = open(outfile, 'w',encoding='utf-8')
print('开始写入文件'.center(20,'-'))
seq = '一级文件夹','二级文件夹','统计框数'
name.write('\t'.join(seq) + '\n')
list_text(name)
print('\n\n' + '文件写入完成'.center(20,'-'))
name.close()
xls(outfile)
def xls(outfile):
#生成Excel文件
os.chdir(path1)
wb = Workbook()
ws = wb.active
ws.title = 'json'
#设置表头字体
ws.row_dimensions[1].font = Font(bold=True,size=20)
ws.column_dimensions['A'].width = 50.0
ws.column_dimensions['B'].width = 50.0
ws.column_dimensions['C'].width = 9.0
first_row = []
datas = []
with open(outfile,encoding='utf-8') as f:
is_first_row = True
for line in f:
line = line[:-1]
#存储第一行
if is_first_row:
is_first_row = False
first_row = line.split('\t')
continue
#存储第二行至max_row
datas.append(line.split('\t'))
ws.append(first_row)
for data in datas:
ws.append(data)
wb.save('./labels_num.xlsx')
if __name__ == '__main__':
path1 = os.getcwd()
path = path1 + '/json'
to_text()
如果出现当前进度:101% 说明命名有误,用 Excel 筛选查一下重复即可
这里我打包成一个了程序:

json文件夹和labels_num.exe文件在同一级目录下

可以直接下载使用:
https://pan.baidu.com/s/1K52S05b_pOMjSZomWAaCQw
