网易云音乐评论生成Wordcloud(词云)
1 前言
1.1 目的
本篇主要介绍网易云音乐爬取歌曲知足的评论生成词云,可以结合新浪微博生成词云学习。
1.2 工具
- Wordcloud 词云(
pip install wordcloud安装即可) - jieba 分词(
pip install jieba安装即可) - 第三方网易云API(需配合node.js食用):https://github.com/Binaryify/NeteaseCloudMusicApi
2 过程
2.1 思路分析
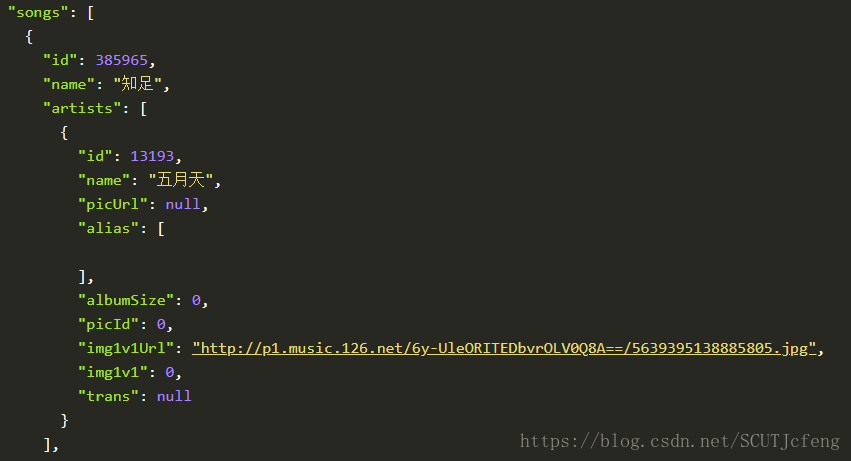
- 爬取评论内容,查看API接口为
/comment/music?id=385965,id为要爬取评论的歌曲id,通过API/search?keywords=知足可以得到添加offset和limit(默认为20),然后offset可以通过offset = (page - 1) * 20得到。
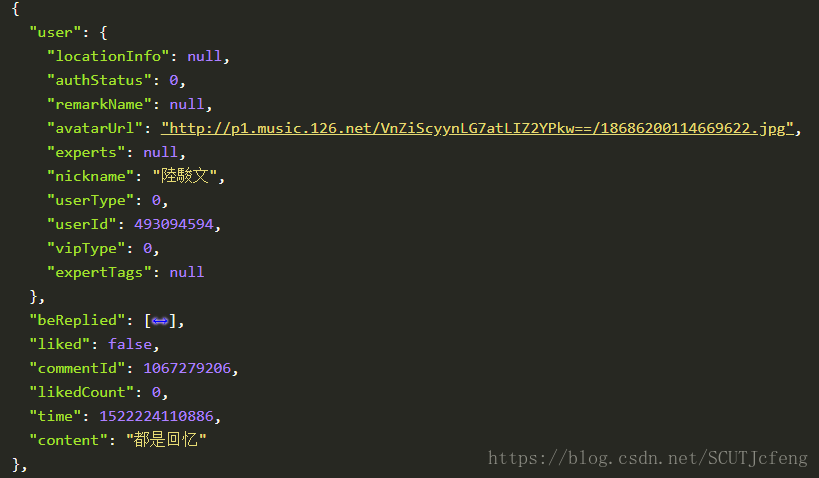
- 解析Json数据,抓取评论
- 引入Wordcloud模块,生成词云。
2.2 步骤
- 本人用Scrapy实现数据抓取,Spider下parse改写如下:
def parse(self, response):
body = json.loads(response.text)
comments = body['comments']
for comment in comments:
item = NeteasecommentsItem()
item['content'] = comment['content']
yield item
self.page += 1
if self.page >= 51:
raise IOError
next_url = 'http://localhost:3000/comment/music?id=%d&offset=%d' % (self.id, (self.page - 1) * 20)
yield scrapy.Request(next_url)其中:
if self.page >= 51:
raise IOError设定抓50页退出。
- pipeline中处理text内容,将内容输出到文本中。
class NeteasecommentsPipeline(object):
def process_item(self, item, spider):
with open('result.txt', 'a+', encoding='utf-8') as f:
f.write(item['content'] + '\n')
return item- 生成词云
from wordcloud import WordCloud
import jieba
import matplotlib.pyplot as plt
with open('result.txt', 'r', encoding='utf-8') as f:
f_text = f.read()
res = jieba.cut(f_text)
res_text = ' '.join(res)
background_img = plt.imread('bg.jpg')
wc = WordCloud(font_path='SourceHanSans-Normal.ttf', mask=background_img).generate(res_text)
plt.imshow(wc)
plt.axis('off')
plt.show()其中,mask参数用来修改背景图片,否则是一个矩形,font_path用于引入自定义字体,默认字体不显示中文,matplotlib.pyplot用于显示生成的图片。
放个最终效果图吧。

3 总结
最后说明一下:
* 自定义字体必须支持中文显示,不然还是会显示一个个口字;
* 背景图片最好选用分辨率高一点的,不然显示效果很差;
* 其它细节请看新浪微博生成词云;
* Node.js版网易云音乐API:https://binaryify.github.io/NeteaseCloudMusicApi/#/?id=neteasecloudmusicapi
最最后再放个我用的背景图片吧:

以上。
