第一篇:https://blog.csdn.net/Nicht_sehen/article/details/89741145
第二篇:https://blog.csdn.net/Nicht_sehen/article/details/89765071
数据处理
名字还是一样处理,不过改了映射关系
df_train=pd.read_csv('../input/train.csv')
df_test=pd.read_csv('../input/test.csv')
PassengerId=df_test['PassengerId']
dataset = pd.concat([df_train, df_test], ignore_index = True)
dataset['Title'] = dataset['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
m={'Capt':'Officer', 'Col':'Officer','Don':'Officer','Dona':'Royalty',
'Dr':'Officer','Jonkheer':'Master','Lady':'Royalty','Major':'Officer',
'Master':'Master','Miss':'Miss','Mlle':'Miss','Mme':'Mrs',
'Mr':'Mr','Mrs':'Mrs','Ms':'Mrs','Rev':'Officer','Sir':'Royalty',
'the Countess':'Royalty'}
dataset.Title=dataset.Title.map(m)
sns.lineplot(x="Title",y="Survived",data=dataset)

familysize和之前一样
dataset['FamilySize']=dataset['SibSp']+dataset['Parch']+1
sns.lineplot(x="FamilySize",y="Survived",data=dataset)

根据图片按照1-4,4-7,>7分三类
def Fam_label(s):
if (s >= 1) & (s <= 4):
return 2
elif ((s > 4) & (s <= 7)):
return 1
elif (s > 7):
return 0
dataset['FamilyLabel']=dataset['FamilySize'].apply(Fam_label)
sns.barplot(x="FamilyLabel", y="Survived", data=dataset)

感觉第一类好像有点问题,重新分一下
def Fam_label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 7)) | (s == 1):
return 1
elif (s > 7):
return 0
dataset['FamilyLabel']=dataset['FamilySize'].apply(Fam_label)
sns.barplot(x="FamilyLabel", y="Survived", data=dataset)

看一下cabin的内容,发现应该是首字母分的等级(以前怎么没发现。。。):
dataset['Cabin'] = dataset['Cabin'].fillna('Unknown')
dataset['Deck']=dataset['Cabin'].str.get(0)
sns.barplot(x="Deck", y="Survived", data=dataset)
相应的看看票号:
dataset['Ticket'].value_counts()
将其变成一个字典,并组成新的特征:
Ticket_Count = dict(dataset['Ticket'].value_counts())
dataset['TicketGroup'] = dataset['Ticket'].apply(lambda x:Ticket_Count[x])
sns.lineplot(x='TicketGroup', y='Survived', data=dataset)

这个和familysize的图像趋势有点像,根据图像对其进行分组:
def Ticket_Label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 8)) | (s == 1):
return 1
elif (s > 8):
return 0
dataset['TicketGroup'] = dataset['TicketGroup'].apply(Ticket_Label)
sns.barplot(x='TicketGroup', y='Survived', data=dataset)

看一下目前的数据:

还有Age, Embarked,Fare 数据有缺失值,接下来对数据进行缺失值的处理
Age: 使用RF对age进行预测,并将填充预测值:
from sklearn.ensemble import RandomForestRegressor
age_df = dataset[['Age', 'Pclass','Sex','Title']]
age_df=pd.get_dummies(age_df)
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
y = known_age[:, 0]
X = known_age[:, 1:]
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
predictedAges = rfr.predict(unknown_age[:, 1::])
dataset.loc[ (dataset.Age.isnull()), 'Age' ] = predictedAges

Age 填充完成
dataset.groupby(by=["Pclass","Embarked"]).Fare.median()

Embarked用c填充:
dataset['Embarked']=dataset['Embarked'].fillna('C')
查看缺失的那一个Fare:

Fare直接用均值填充:
dataset['Fare']=dataset['Fare'].fillna(dataset[(dataset['Embarked'] == "S") & (dataset['Pclass'] == 3)].Fare.median())
再把name切出来看看:
dataset['Surname']=dataset['Name'].apply(lambda x:x.split(',')[0].strip())
dataset['Surname'].value_counts()
将name和damilygroup放在一起看看:
Surname_Count = dict(dataset['Surname'].value_counts())
dataset['FamilyGroup'] = dataset['Surname'].apply(lambda x:Surname_Count[x])
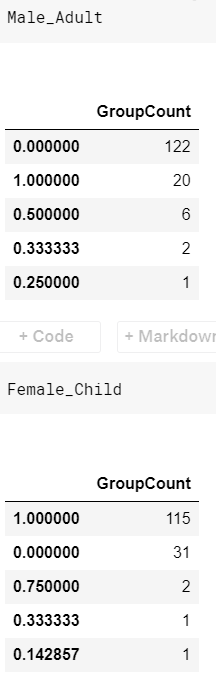
将小女孩和成年男性分出来看看
Female_Child_Group=dataset.loc[(dataset['FamilyGroup']>=2) & ((dataset['Age']<=12) | (dataset['Sex']=='female'))]
Male_Adult_Group=dataset.loc[(dataset['FamilyGroup']>=2) & (dataset['Age']>12) & (dataset['Sex']=='male')]
Female_Child=pd.DataFrame(Female_Child_Group.groupby('Surname')['Survived'].mean().value_counts())
Female_Child.columns=['GroupCount']
sns.lineplot(x=Female_Child.index, y=Female_Child["GroupCount"]).set_xlabel('AverageSurvived')

训练模型
选择特征:
dataset=pd.concat([df_train, df_test])
dataset=dataset[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','FamilyLabel','Deck','TicketGroup']]
dataset=pd.get_dummies(dataset)
df_train=dataset[dataset['Survived'].notnull()]
df_test=dataset[dataset['Survived'].isnull()].drop('Survived',axis=1)
X = df_train.as_matrix()[:,1:]
y = df_train.as_matrix()[:,0]
模型:
找最适合的参数:
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.feature_selection import SelectKBest
pipe=Pipeline([('select',SelectKBest(k=20)),
('classify', RandomForestClassifier(random_state = 10, max_features = 'sqrt'))])
param_test = {'classify__n_estimators':list(range(20,50,2)),
'classify__max_depth':list(range(3,60,3))}
gsearch = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='roc_auc', cv=10)
gsearch.fit(X,y)
print(gsearch.best_params_, gsearch.best_score_)

from sklearn.pipeline import make_pipeline
from sklearn import metrics
from sklearn.model_selection import cross_val_score
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
cv_score = cross_val_score(pipeline, X, y, cv= 10)
print(cv_score.mean())
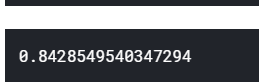
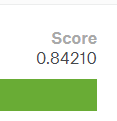
提交结果:

总结
1,特征的填充:除了要看缺失值的多少来填充外,还要看和其他特征的联系,一般都是填充均值或者众数,,而在这里给出了一些不一般的填充方法
2,特征的分组:画图看会更清楚该怎么分组
