一、三大范式
第一范式: 要求表的每一个字段只表达一个意思。
表的每个字段必须是不可分割的独立单元
student : name -- 违反第一范式
张小名|狗娃
sutdent : name old_name --符合第一范式
张小名 狗娃
第二范式: 在第一范式的基础上,要求每张表只表达一个意思。
表的每个字段都和表的主键有依赖。
employee(员工): 员工编号 员工姓名 部门名称 订单名称 --违反第二范式
员工表:员工编号 员工姓名 部门名称
订单表: 订单编号 订单名称 -- 符合第二范式
第三范式: 在第二范式基础,要求表的每一个字段都只能和主键有直接决定依赖关系。
员工表: 员工编号(主键) 员工姓名 部门编号 部门名 --符合第二范式,违反第三范式 (数据冗余高)
员工表:员工编号(主键) 员工姓名 部门编号 --符合第三范式(降低数据冗余)
部门表:部门编号 部门名
1. 原始单据与实体之间的关系(重点掌握)
可以是一对一、一对多、多对多的关系。
在一般情况下,它们是一对一的关系:即一张原始单据对应且只对应一个实体。
在特殊情况下,它们可能是一对多或多对一的关系,即一张原始单据对应多个实
体,或多张原始单据对应一个实体。
这里的实体可以理解为基本表。明确这种对应关系后,对我们设计录入界面大有好处。
〖例1〗:一份员工履历资料,在人力资源信息系统中,就对应三个基本表:员工基本情况表、社会
关系表、工作简历表。这就是“一张原始单据对应多个实体”的典型例子。
2. 主键与外键 (掌握)
一般而言,一个实体不能既无主键又无外键。在E-R 图中, 处于叶子部位的实体, 可以定义主
键,也可以不定义主键(因为它无子孙), 但必须要有外键(因为它有父亲)。
主键与外键的设计,在全局数据库的设计中,占有重要地位。
当全局数据库的设计完成以后,有个美国数据库设计专家说:“键,到处都是键,除了键之外,
什么也没有”,这就是他的数据库设计经验之谈,也反映了他对信息系统核心(数据模型)的高度抽象思想。
主键是实体的高度抽象,主键与外键的配对,表示实体之间的连接。
3. 基本表的性质 (了解)
基本表与中间表、临时表不同,因为它具有如下四个特性:
(1) 原子性。基本表中的字段是不可再分解的。
(2) 原始性。基本表中的记录是原始数据(基础数据)的记录。
(3) 演绎性。由基本表与代码表中的数据,可以派生出所有的输出数据。
(4) 稳定性。基本表的结构是相对稳定的,表中的记录是要长期保存的。
理解基本表的性质后,在设计数据库时,就能将基本表与中间表、临时表区分开来。
4. 范式标准(了解)
基本表及其字段之间的关系, 应尽量满足第三范式。
但是,满足第三范式的数据库设计,往往不是最好的设计。为了提高数据库的运行效率,
常常需要降低范式标准:适当增加冗余,达到以空间 换时间的目的。
例2〗:有一张存放商品的基本表,如表1所示。“金额”这个字段的存在,表明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“金额”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。
在Rose 2002中,规定列有两种类型:数据列和计算列。“金额”这样的列被称为“计算列”,而“单价”和“数量”这样的列被称为“数据列”。
表1 商品表的表结构
商品名称 商品型号 单价 数量 金额
电视机 29吋 2,500 40 100,000
5. 通俗地理解三个范式(了解)
通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式(通俗地理解是够用的理解,并不是最科学最准确的理解):
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了
提高运 行效率,就必须降低范式标准,适当保留冗余数据。
具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
6. 要善于识别与正确处理多对多的关系 (掌握)
若两个实体之间存在多对多的关系,则应消除这种关系。消除的办法是,在两者之间增加第三个
实体。这样,原来一个多对多的关系,现在变为两个一对多的关系。要将原来两个实体的属性合理地
分配到三个实体中去。这里的第三个实体,实质上是一个较复杂的关系,它对应一张基本表。一般来
讲,数据库设计工具不能识别多对多的关系,但能处理多对多的关系。
〖例3〗:在“图书馆信息系统”中,“图书”是一个实体,“读者”也是一个实体。这两个实体之间
的关系,是一个典型的多对多关系:一本图书在不同时间可以被多个读者借阅,一个读者又可以借多
本图书。为此,要在二者之间增加第三个实体,该实体取名为“借还书”,它的属性为:借还时间、借
还标志(0表示借书,1表示还书),另外,它还应该有两个外键(“图书”的主键,“读者”的主键),使它
能与“图书”和“读者”连接。
7. 正确认识数据冗余
主键与外键在多表中的重复出现, 不属于数据冗余,这个概念必须清楚,事实上有许多人还不
清楚。非键字段的重复出现, 才是数据冗余!而且是一种低级冗余,即重复性的冗余。高级冗余不
是字段的重复出现,而是字段的派生出现。
〖例4〗:商品中的“单价、数量、金额”三个字段,“金额”就是由“单价”乘以“数量”派生出来
的,它就是冗余,而且是一种高级冗余。冗余的目的是为了提高处理速度。只有低级冗余才会增加
数据的不一致性,因为同一数据,可能从不同时间、地点、角色上多次录入。因此,我们提倡高级
冗余(派生性冗余),反对低级冗余(重复性冗余)。
8. “三少原则”
(1) 一个数据库中表的个数越少越好。只有表的个数少了,才能说明系统的E-R图少而精,去掉了
重复的多余的实体,形成了对客观世界的高度抽象,进行了系统的数据集成,防止了打补丁式
的设计;
(2) 一个表中组合主键的字段个数越少越好。因为主键的作用,一是建主键索引,二是做为子表的
外键,所以组合主键的字段个数少了,不仅节省了运行时间,而且节省了索引存储空间;
(3) 一个表中的字段个数越少越好。只有字段的个数少了,才能说明在系统中不存在数据重复,且
很少有数据冗余,更重要的是督促读者学会“列变行”,这样就防止了将子表中的字段拉入到主
表中去,在主表中留下许多空余的字段。所谓“列变行”,就是将主表中的一部分内容拉出去,
另外单独建一个子表。这个方法很简单,有的人就是不习惯、不采纳、不执行。
数据库设计的实用原则是:在数据冗余和处理速度之间找到合适的平衡点。“三少”是一个整体
概念,综合观点,不能孤立某一个原则。该原则是相对的,不是绝对的。“三多”原则肯定是错
误的。试想:若覆盖系统同样的功能,一百个实体(共一千个属性) 的E-R图,肯定比二百个实
体(共二千个属性)的E-R图,要好得多。
提倡“三少”原则,是叫读者学会利用数据库设计技术进行系统的数据集成。数据集成的步骤是将
文件系统集成为应用数据库,将应用数据库集成为主题数据库,将主题数据库集成为全局综合数
据库。集成的程度越高,数据共享性就越强,信息孤岛现象就越少,整个企业信息系统的全局E—
R图中实体的个数、主键的个数、属性的个数就会越少。
提倡“三少”原则的目的,是防止读者利用打补丁技术,不断地对数据库进行增删改,使企业数据
库变成了随意设计数据库表的“垃圾堆”,或数据库表的“大杂院”,最后造成数据库中的基本表、
代码表、中间表、临时表杂乱无章,不计其数,导致企事业单位的信息系统无法维护而瘫痪。
例子:由下图设计数据库表结构
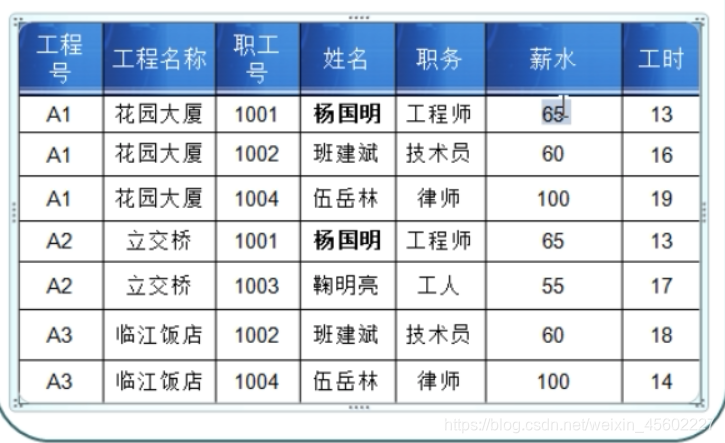
工程职工薪水: 工程号 工程名称 职工号 姓名 职务 薪水 工时
工程表:
工程id 工程号 工程名称
职务表:
职务id 职务名称 薪水
职工表:
职工id 职工号 姓名 职务id
工程职工表(中间表):
id 工程id 职工id 工时
