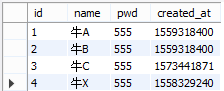
先定义一张表,在之后的讲解中的所有例子,都是基于这张表做的演示,那么就定义一张最常见的用户表吧。
CREATE TABLE `user` (
`id` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) COLLATE UTF8MB4_UNICODE_CI NOT NULL,
`pwd` VARCHAR(255) COLLATE UTF8MB4_UNICODE_CI NOT NULL,
`created_at` INT(8) UNSIGNED NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_name` (`name`),
KEY `idx_created_at` (`created_at`)
) ENGINE=INNODB DEFAULT CHARSET=UTF8MB4 COLLATE = UTF8MB4_UNICODE_CI;
插入几条数据,方便之后快乐的玩耍
INSERT INTO `user` (`id`, `name`, `pwd`, `created_at`) VALUES ('1', '牛A', '555', '1559318400');
INSERT INTO `user` (`id`, `name`, `pwd`, `created_at`) VALUES ('2', '牛B', '555', '1559318400');
INSERT INTO `user` (`id`, `name`, `pwd`, `created_at`) VALUES ('3', '牛C', '555', '1573441871');
INSERT INTO `user` (`id`, `name`, `pwd`, `created_at`) VALUES ('4', '牛X', '555', '1558329240');

插入更新 ON DUPLICATE KEY UPDATE
有这么一个需求,已知某个表设置了主键或者唯一索引,我们想向数据库插入一条记录:若数据表中已经存在相同主键的记录,我们就更新该条记录,否则就插入一条新的记录。
比如:我们要求如果数据库不存在name='牛C'这条记录的话,就插入一条name='牛C'的新记录,如果存在的话,就将牛C的pwd更新为666。
看到这里,很容易就会想到一种办法完成这个需求:
先去查询数据库有没有这条记录,然后再根据情况去执行插入或更新操作。
select * from `user` where 'name' = '牛C';
INSERT INTO `user` (`name`, `pwd`, `created_at`) VALUES ('牛C', '666', '1573441871');
或
update `user` set `pwd` = 666 where 'name' = '牛C';
但是这样做会有两个坏处
一:
这是两条sql语句,进行一个操作却要执行两条语句,很麻烦,效率十分低。
二:
这两条sql语句是分开的,也就是说它们不具备原子性,如果在过程中突然中断,那么第二条语句可能就执行不到,这样就会出现问题了。
所以,mysql官方提供了即满足原子性又不用执行两条语句的```ON DUPLICATE KEY UPDATE```,这关键字就是```不重复写入```,就是由于主键或唯一索引限制时,当插入的记录和数据库中已有的记录冲突时就会更新旧的记录。
比如刚刚的例子,我们并不能确定数据库中是否存在一条name='牛C'的记录,所以想通过插入新数据的方式来判断,可是由于唯一索引的约束会抛出错误,说明存在name='牛C'的记录,但是用这种报错的方式来判断是否存在是非常不好的,因为在我们编程中,连接数据库通过代码来插入数据的时候,报错已经是一个比较严重的情况了。
INSERT INTO `user` (`name`, `pwd`, `created_at`) VALUES ('牛C', '666', '1573441871')
不过如果改成用ON DUPLICATE KEY UPDATE的话,那么就不会产生报错了,有则更新,无则插入,十分方便安全。
INSERT INTO `user` (`name`, `pwd`, `created_at`) VALUES ('牛C', '666', '1573441871') ON DUPLICATE KEY UPDATE `pwd` = 666;

那么就有疑问了,怎么判断是插入还是更新呢?
官方文档上写明,使用ON DUPLICATE KEY UPDATE时,如果将行作为新行插入,则每行的受影响行值为1;如果更新现有行,则每行受影响的行值为2;如果现有行设置为其当前值,则每行受影响的行值为0。如果在连接到mysqld时为mysql_real_connect()C API函数指定CLIENT_FOUND_ROWS标志,则如果将现有行设置为其当前值,则affected-rows值为1(不为0)。
所以根据受影响的行数(就是图中红框的地方)就可以判断是插入还是更新或者是没变化。

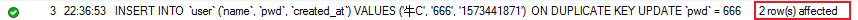

- 注意
使用ON DUPLICATE KEY UPDATE时,默认情况下,每次更新都会更新该表的自增主键ID,那就会造成主键不连续自增。关于解决方法,网上有许多,可以根据需要去找。
幂等性
在开发中,在统计数据的时候,我们是认为在某个时间段内,旧的数据是不会发生改变的,而且数据统计任务不可能是单机执行的,如果在数据统计做持久化的时候单纯的insert语句的话,肯定会因为主键冲突而抛出错误。所以数据统计的时候,在ON DUPLICATE KEY UPDATE的基础上还要做到幂等性。比如,今天要统计昨日的数据,那么昨日的数据肯定是不可能改变的,所以这就要求做到幂等性。
幂等性:任意多次执行所产生的影响均与一次执行的影响相同,意思就是不管调用多少次,得到的结果都是一样的。
很多时候我们在开发过程中经常遇到数据重复插入、重复更新等问题,因为应用系统的复杂逻辑以及网络交互存在的不确定性,导致这一中重复的现象,但很多时候我们是不希望出现重复处理的问题,因为这会出现严重的错误,比如说数据由于主键的唯一限制,可是又因为网络的问题,出现了多次插入的情况,会报错说主键的被重复插入了,这种报错虽然不是非常致命,但会带来日志的冗余膨胀。
这里找了一些文章,将幂等性的重要性讲得很通俗易懂。
高并发系统数据幂等性
高并发下接口幂等性解决方案
探讨一下实现幂等性的几种方式
分布式系统中的幂等性
幂等性的作用及实现
接口幂等性适用场景及设计方法
幂等性理解和解决方案
深入理解幂等性
编程中的幂等性 — HTTP幂等性
参考
https://segmentfault.com/q/1010000017203726/a-1020000017286830
https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html
