1. 目标定位
图像分类定位:一般图像中只有一个对象
对象检测:一般有多个对象
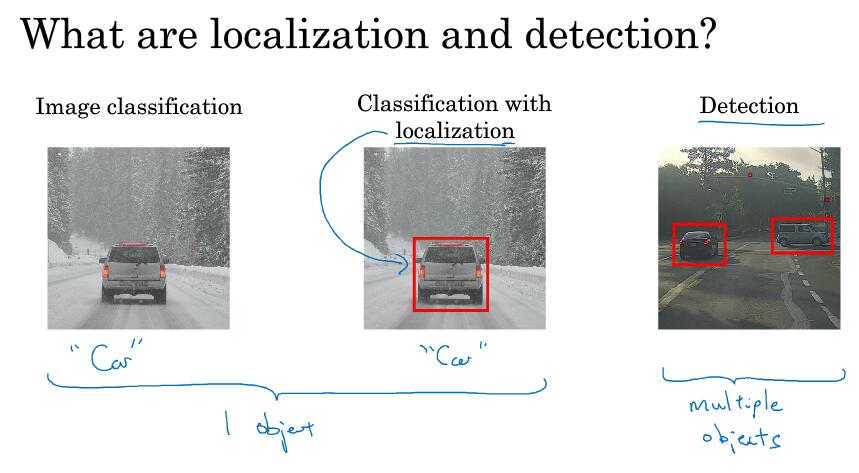
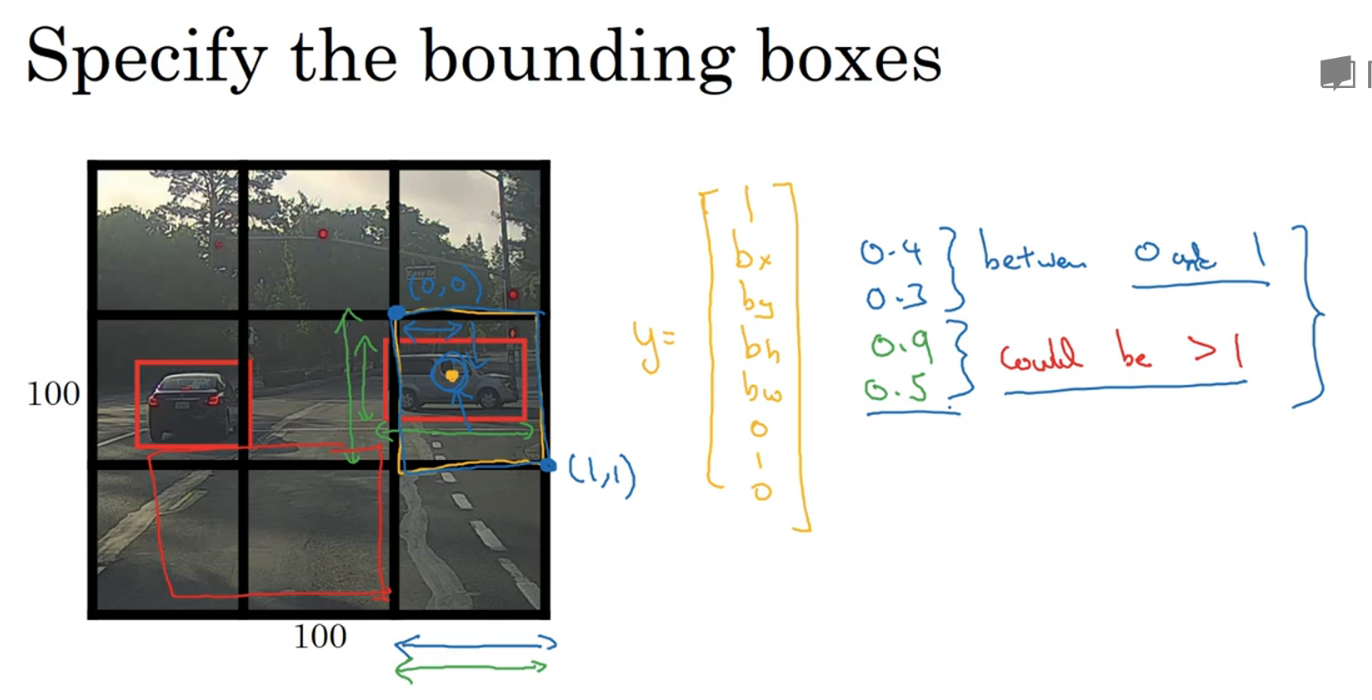
分类定位问题:识别出图像中的对象属于哪一类,且给出一个边界框来表示它在图像中的位置。所以,最后输出的地方再加上四个参数来表示位置
注:bx, by是图中对象所在位置的中心点
对象有三种,如果是background,表示没有任何对象
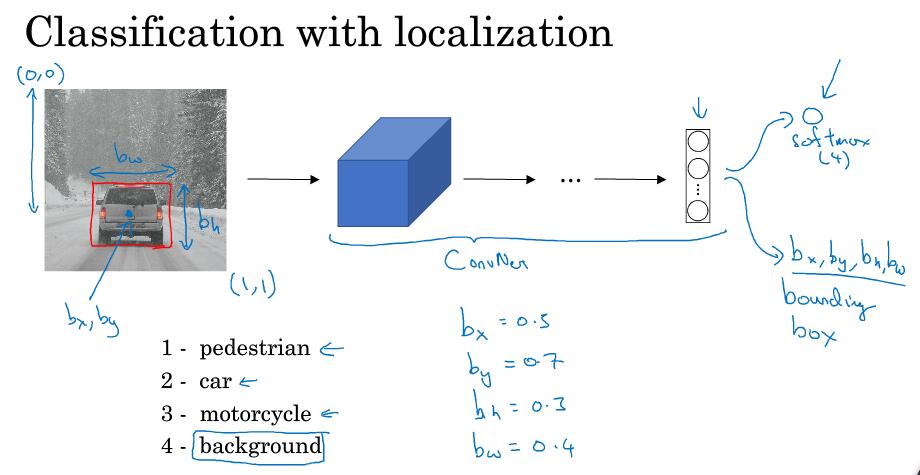
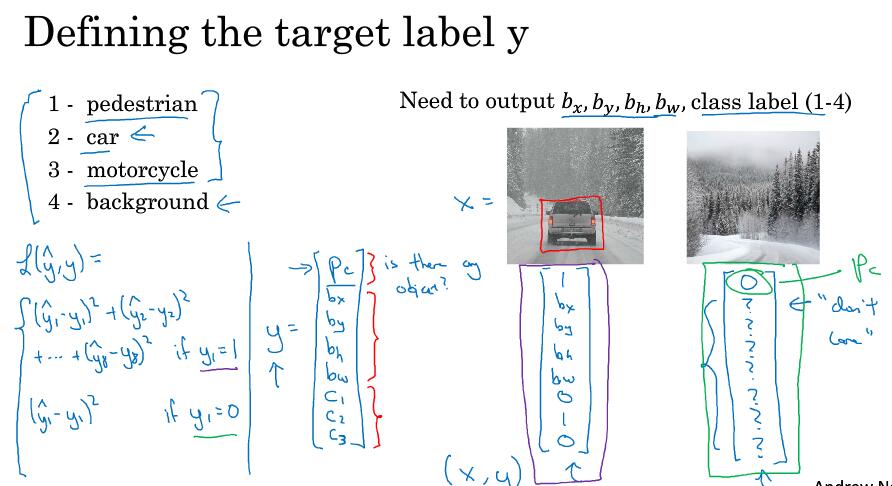
定义输出的label y
y中包含了8个值,第一个pc表示是否有对象,如果有则为1,没有为0(也就是只有背景)
如果只有背景,则其它结果就不重要了,"don't care"
定义loss函数,是对8个结果分别求差平方和(也可以每个参数用不同函数来进行误差估计)。当pc=0时(也就是没有对象时),只关注pc的结果是否正确,loss也就只计算pc的结果
2. 特征点检测landmarkh
识别一个对象,可以通过让神经网络输出一些关键点(landmark)位置来表示。下面是一些例子
注:关键点label的表示在每张图上要一致,比如总是用l1来表示左侧的眼角

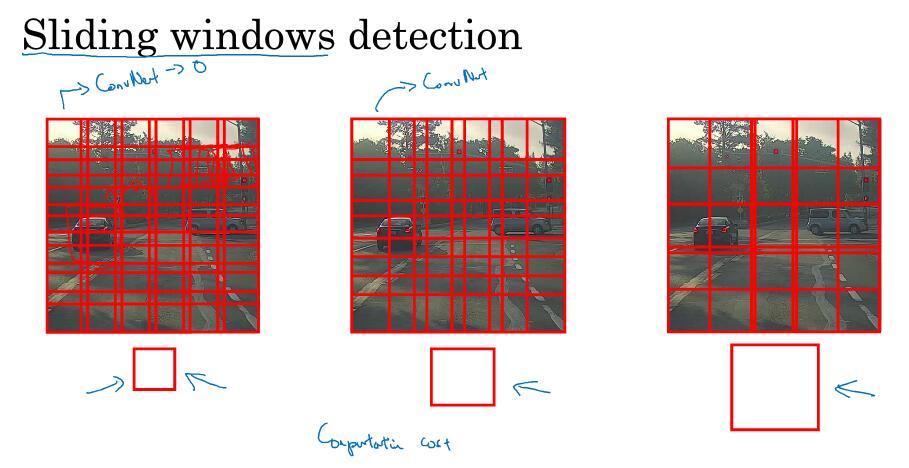
3. 基于滑动窗口的对象检测
训练集:对图像进行适当裁剪,把剪后的部分输入,判断是否包含车

用一个框(窗口),移动遍历图像的各区域,把框内的图像作为ConV网络的输入进行计算
问题:计算的代价太大。以前会采用简单一点的分类方法,但是现在用网络计算的话,计算量变大
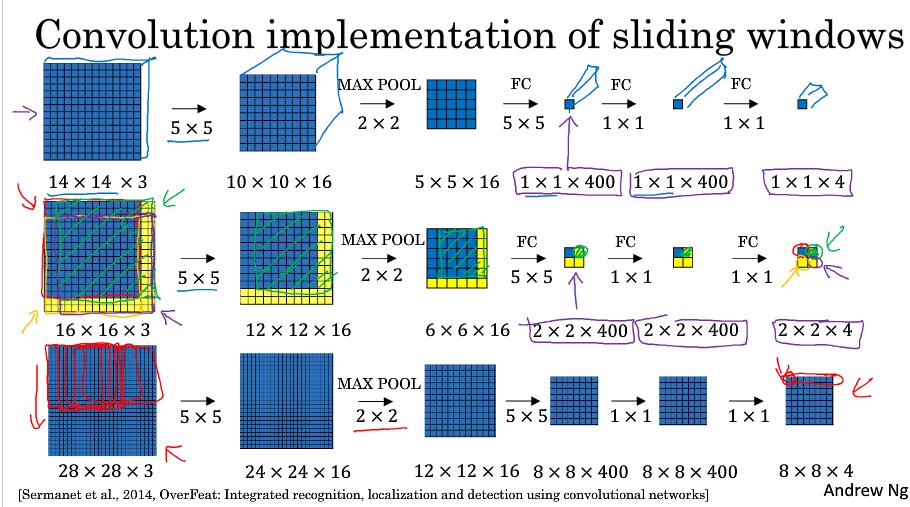
4. 滑动窗口的实现——解决计算量大的问题
如何把FC转成卷积层
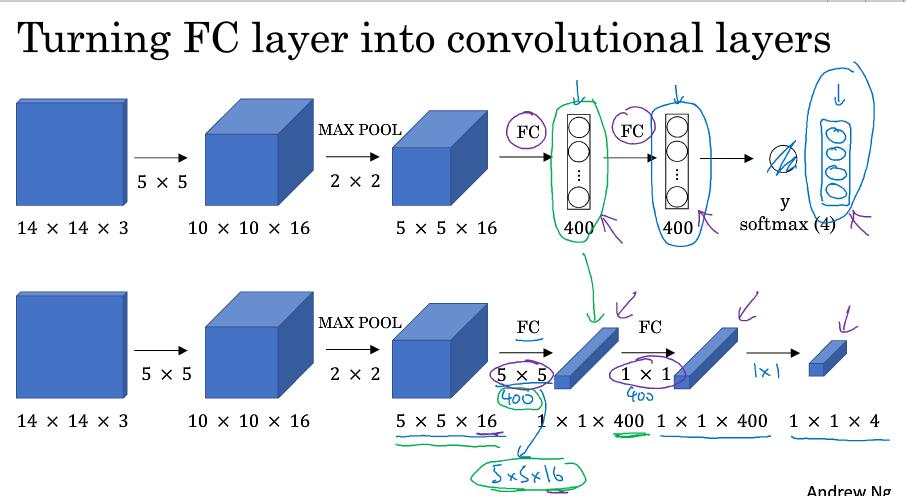
第一行是窗口的大小,也就是以14x14x3的大小作为滑动窗口卷积网络的输入
第二行是训练数据为16x16x3的输入的例子,第三行是28x28x3的输入
这里它不再需要遍历输入图像的各区域作为输入进行计算,因为有很多数据计算是共享的
结果的位置是对应的,和上面slide有什么关系????
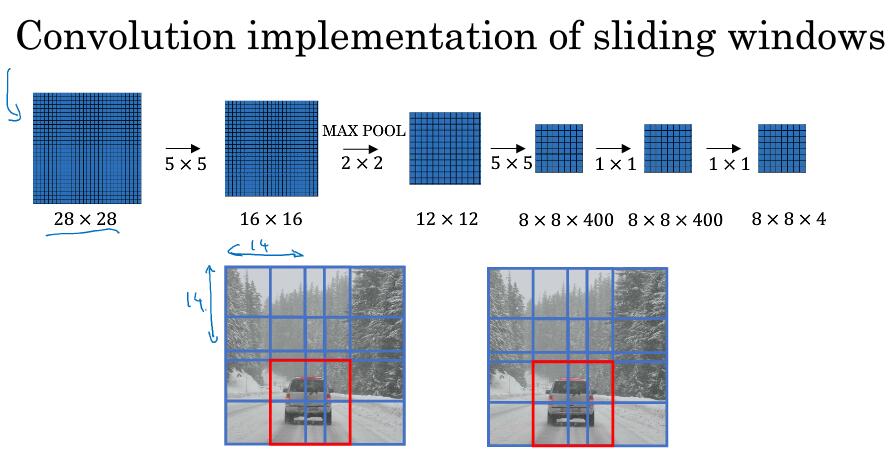
一个实际例子,但仍有一个缺点:窗口的大小位置并不一定那么准确
5. bounding box预测
上面的缺点无法获得精确的边界
YOLO算法:you look only once
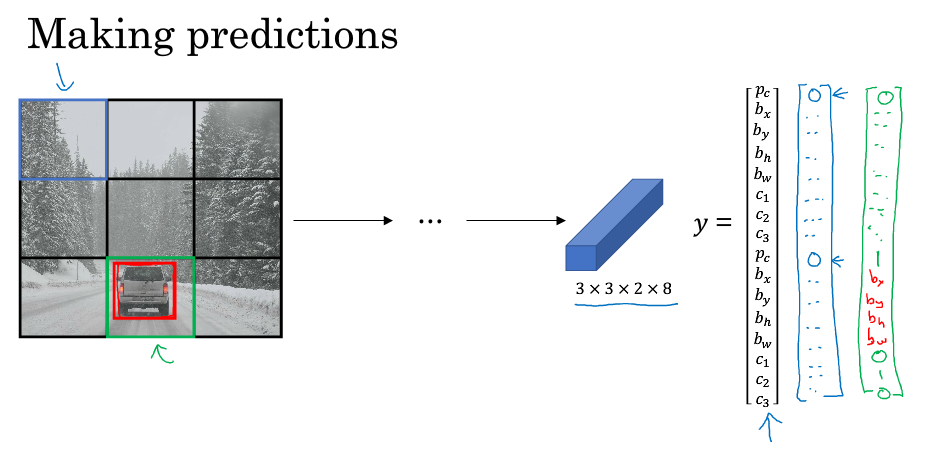
基本思想:把图片分成3x3(或许更多),然后对每个格子执行图像分类和定位方法,每个格子有一个输出label(8个值)
label中标记一个物体属于一个格子是以物体的中心点为准,中心点在哪个格子,它就属于哪个格子。如果一个格子中不包含物体的中心点,即使有很多部分落在其中,也认为该格子不包含物体
一个格子包含多个物体?:也就是格子中有多个物体的中心点。实际上,会使用19x19,划分得更精细,这种情况就会更少一些
每个格子都要执行一次?:利用卷积,只要单次卷积即可完成。YOLO的执行速度很快,甚至可以达到实时检测
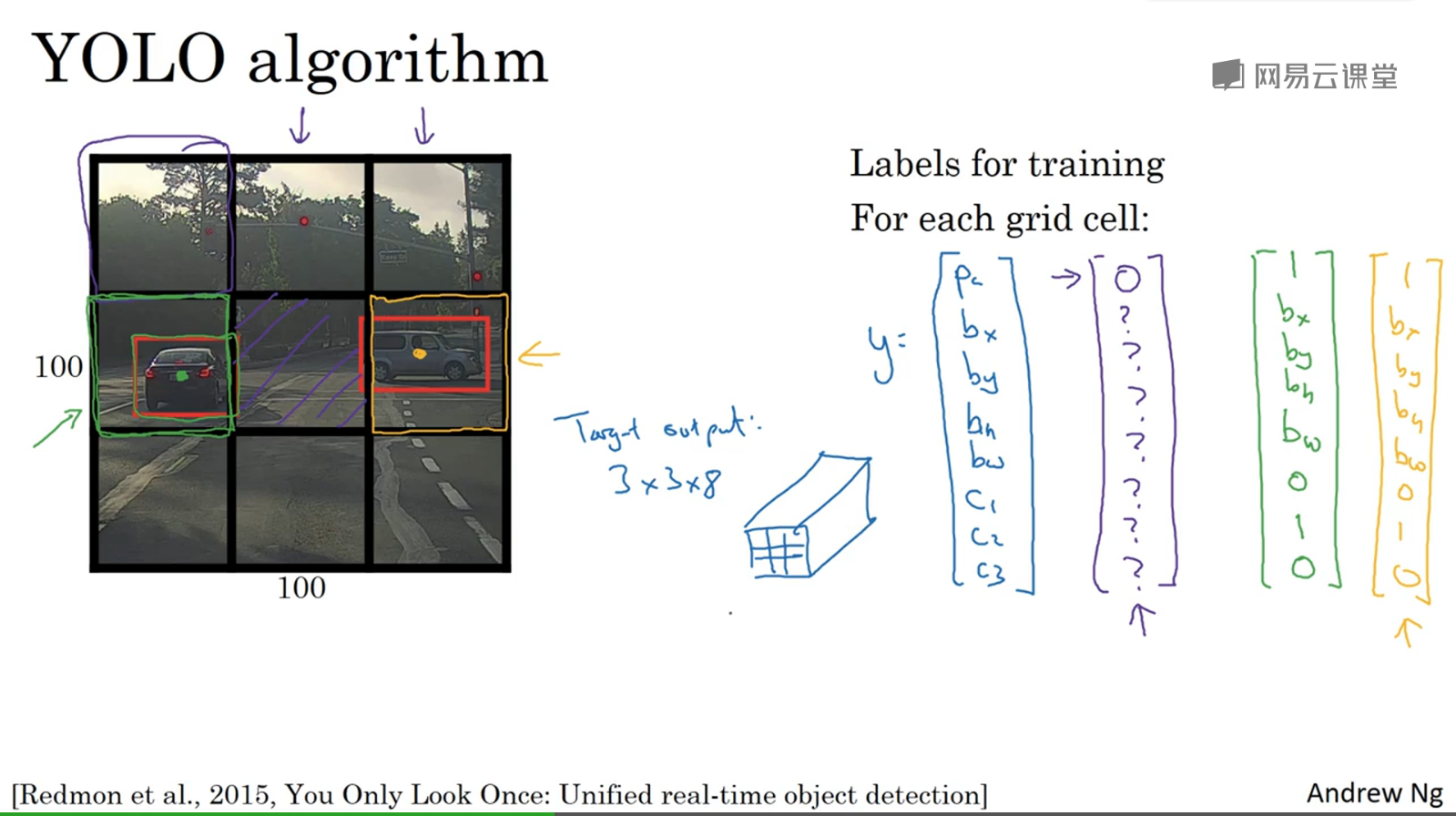
如何定义物体位置:物体的位置是相对于它所在的单元格来说,而不是整个图像
7. 如何评价物体检测算法是否正确
交并比:intersection over union,就是两个区域交集与并集的比,一般规定0.5以上就说明结果是正确的,也可以定得更高

8. 一个物体被多次检测的问题
问题:如果对一个图像划分19x19格,每个格子都有可能说自己包含了一个对象(如车子),也就是一个车子被多个格子检测
non-max suppersion:非最大抑制算法
只检测一个物体的情况(如果有多种物体则每种执行一次non-max)
先对19x19个格子执行算法得到结果,然后找出Pc(包含一个物体的概率)先是把没有达到限值的删除,然后在找出最大的,把与该格子交叉很多的框删除,重复上述操作

9. anchor box
解决一个格子中检测到多个物体的问题(一个格子包含了多个物体的中心点)
基本思想:定义多种anchor box形状,在输出标签中就包括了这些anchor box,检测到一个物体的话,既要看它的中心点位置,还要看它和哪个anchor box的IOU最高来决定
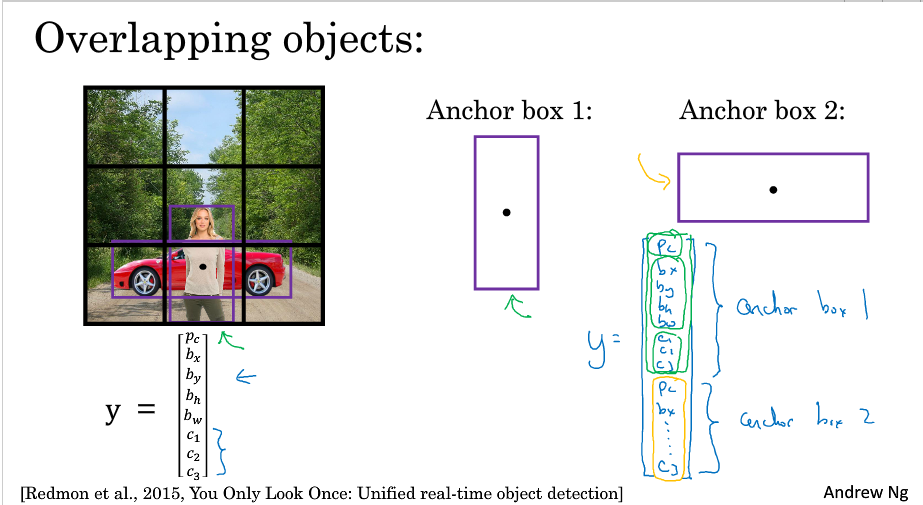

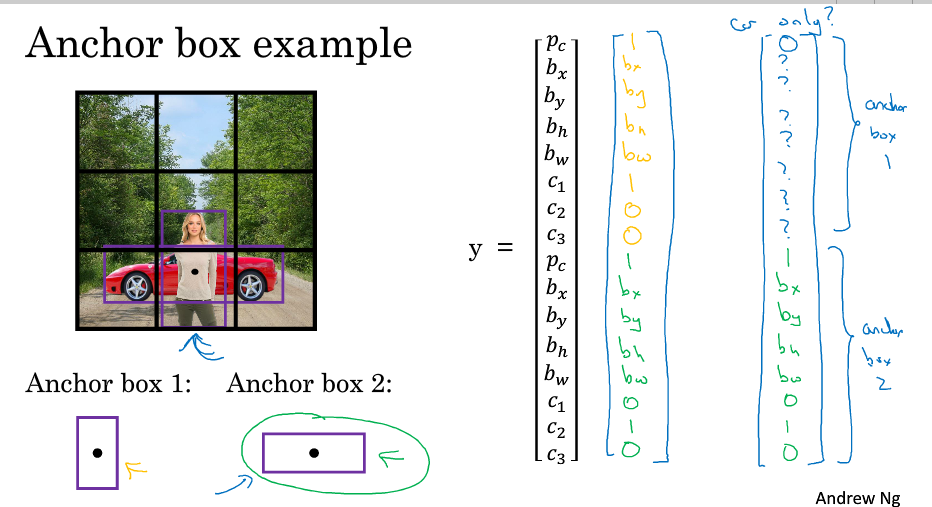
问题:如何选择anchor box的类型; 如果给了两个anchor box,但是有三种形状的话,算法效果不好;事实上,如果格子多一下,一个格子有多个物体的问题就会少一些
10. YOLO算法全部
定义输出标签:用两个anchor box
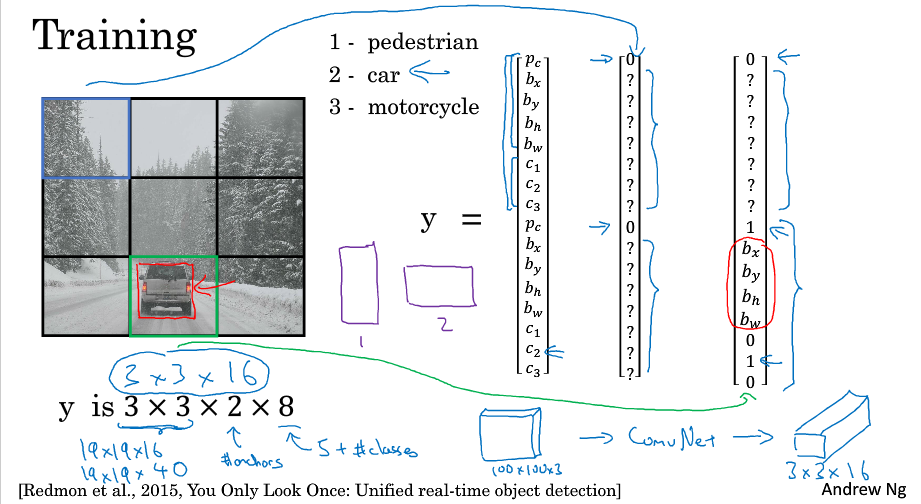
训练
用non-max移除多余的框

11 R-CNN:region with CNN
在计算机视觉领域用的比较多
思想:先对图像进行分割,然后从中选取部分区域执行算法,而不是对整个图像所有区域计算

缺点:速度太慢了
