grep和正则表达式
什么是正则表达式: 正则表达式用于描述字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分隔、匹配、查找及替换操作
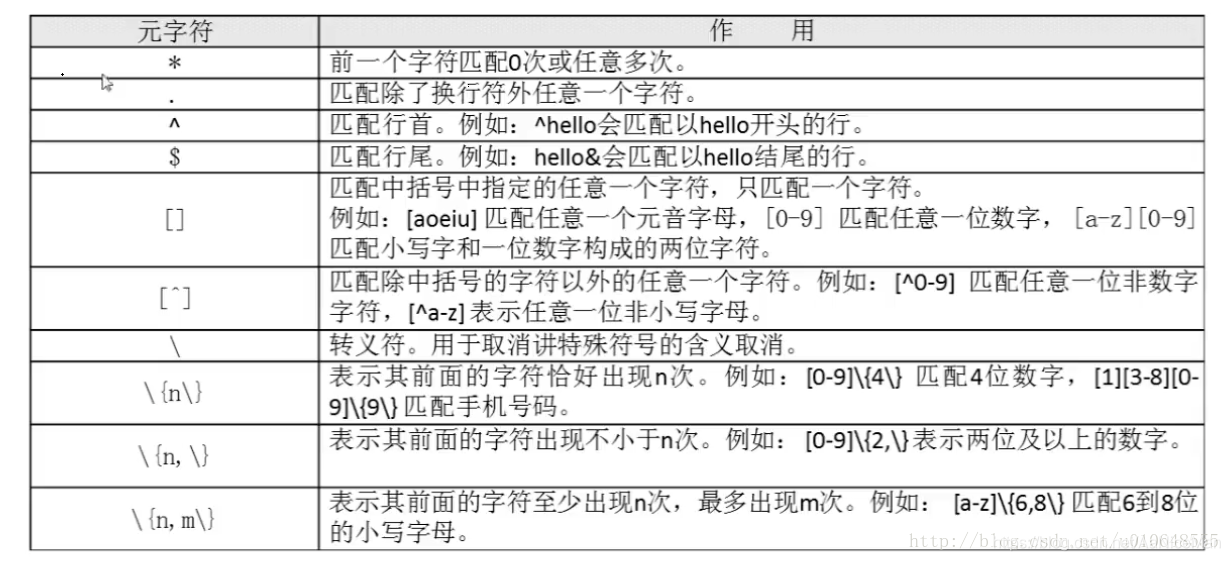
元字符
| * | 重复匹配前一个字符0到多次 |
|---|---|
| . | 匹配除了换行符外任意一个字符,类似通配符? |
| ^ | 匹配行首或后面字符的非 |
| $ | 匹配行尾 |
| [ ] | 匹配中括号中的指定任意一个字符,只匹配一个字符 |
| [^] | 匹配除了中括号的字符以外的任意一个字符,(取反) |
| \ | 转义符,让特殊的字符丧失意义 |
| {n} | 表示其前面的字符恰好出现n次 |
| {n,} | 表示其前面字符出现不少于n次。 |
| {n,m} | 表示其前面的字符至少出现n次,最多出现m次 |
grep命令:
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)
作用:grep命令是一种强大的文本搜索工具,根据用户指定的模式对目标文本进行匹配检查,打印匹配到的行。
模式:由正则表达式或者字符及基本文本字符所编写的过滤条件
常用参数:
-c 只输出匹配行的数量
-i 不区分大小写(只适用于单字符)
-h 查询多文件时不显示文件名
-l 查询多文件时只输出包含匹配字符的文件名
-n 显示匹配行及行号
-s 不显示不存在或无匹配文本的错误信息
-v 显示不包含匹配文本的所有行。
sed




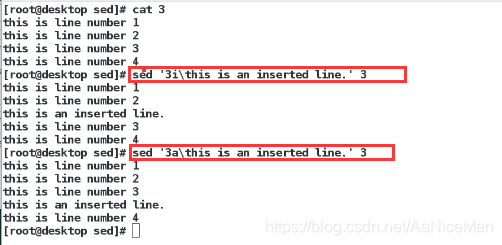

替换标志:
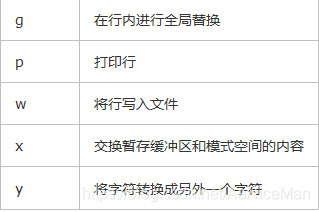
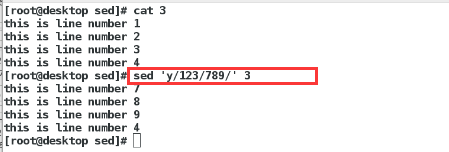
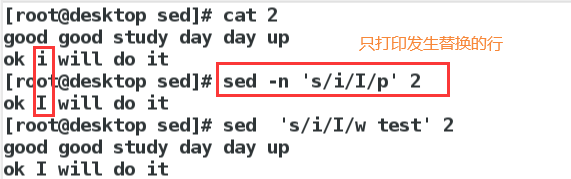
打印:p命令

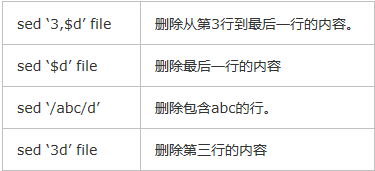
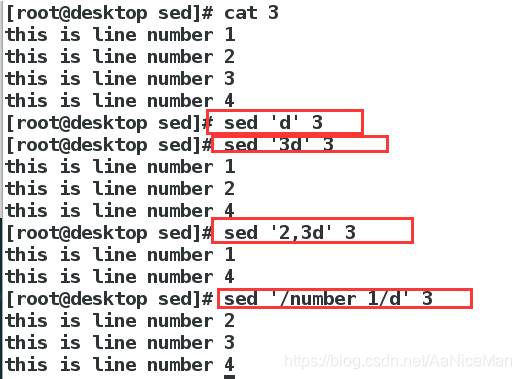
删除:d命令
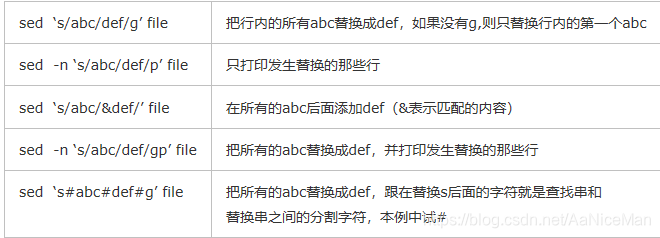
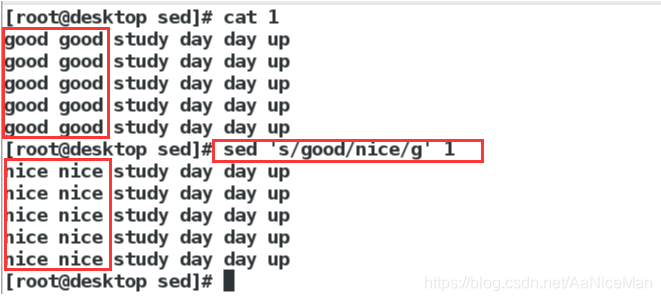
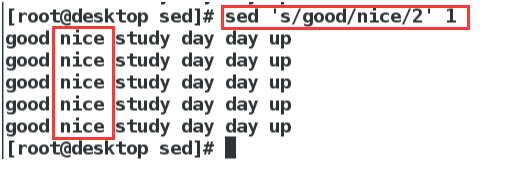
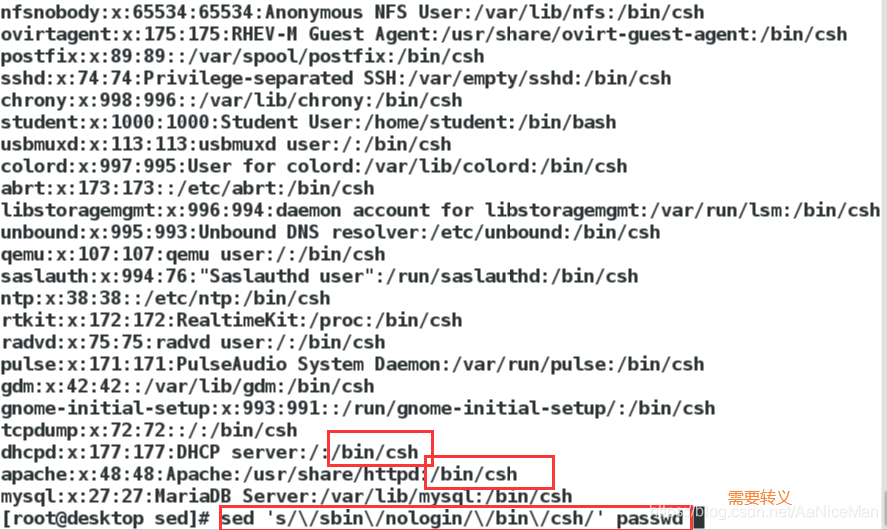
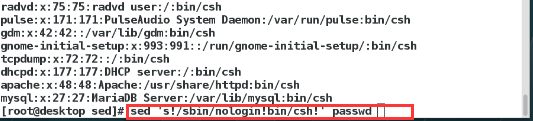
替换:s命令

指定行的范围:逗号

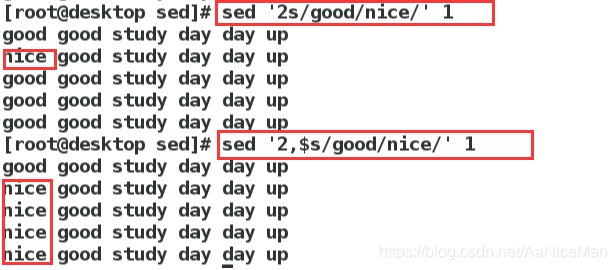
多重编辑-e



awk
简介:awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
使用方法:awk ‘{pattern + action}’ {filenames}
awk -F(指定分隔符) : '{print $1}' passwd 打印passwd文件的以:为分隔符的第一列字符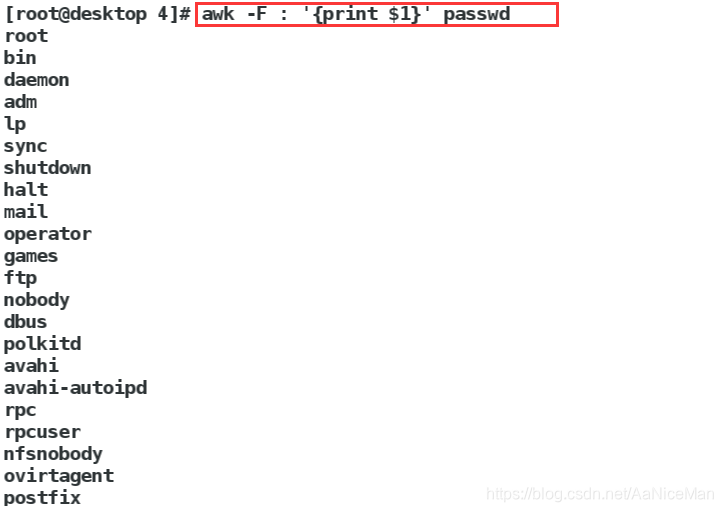
awk -F : '{print $1$2}' passwd 打印第一列和第二列,不出现:分隔符
awk -F : '{print $2}' passwd 打印第二列
awk -F : 'BEGIN{print "linux"}{print $2}' passwd 打印第二列,并且在最前面加上linux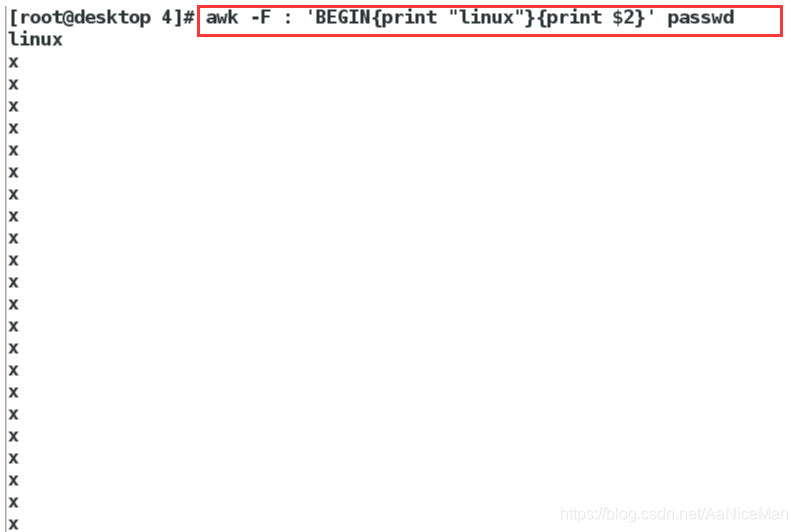
awk -F : 'BEGIN{n=1}{print $2,n}' passwd 在第二列后面 均写上1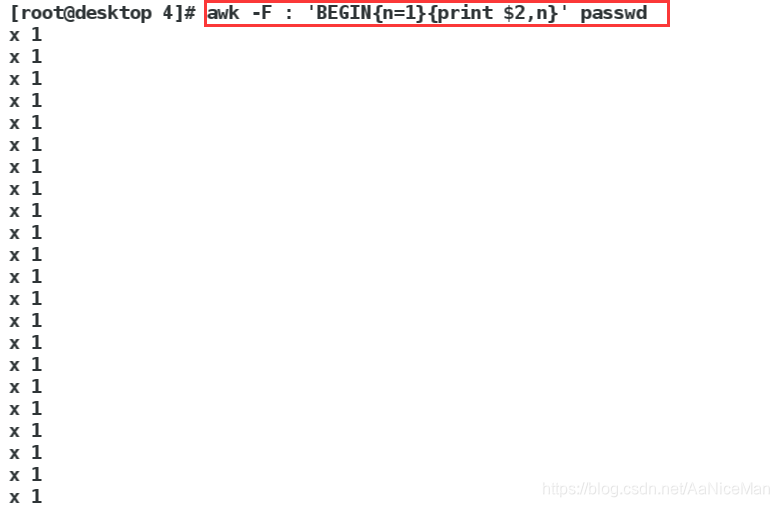
awk -F : 'BEGIN{n=1}{print $2,n++}' passwd打印第二列,并且编号
awk -F : 'BEGIN{n=1}{print n++,$1}' passwd编号在前
awk -F : 'BEGIN{n=1}{print n++,$1}END{print “over”}' passwd在后面写上over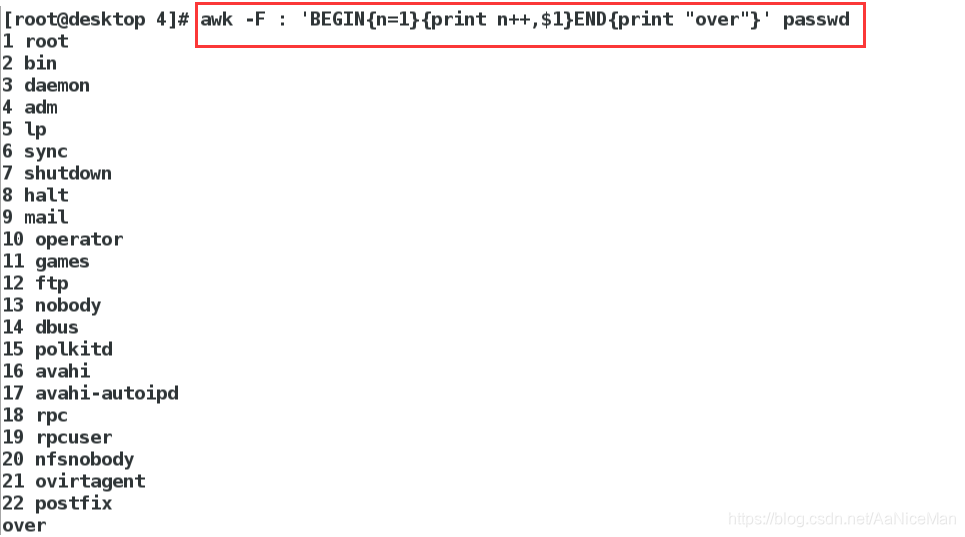
awk -F : 'BEGIN{n=1}{print n++,$1}END{print NR}' passwd在结尾输出行数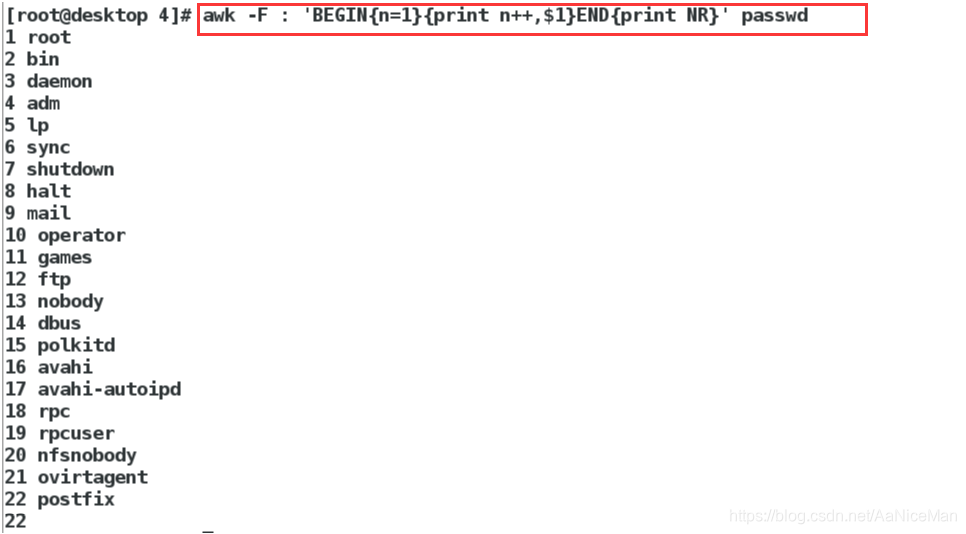
awk -F : 'BEGIN{n=1}{print n++,$1}END{print NF}' passwd在结尾输出列数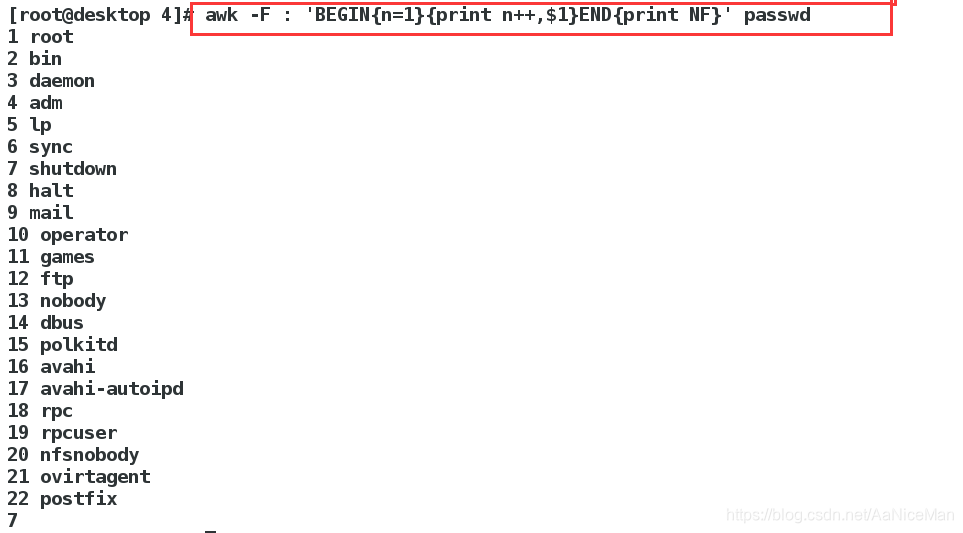
awk '/bash/{print}' passwd 输出包含bash的行的第一个字符
awk -F : 'NR=3{print $1}' passwd第三行的第一个
awk '{print $0}' passwd输出行
