Xpdf是用来处理和转换 PDF 的利器。项目中需要将 PDF 转换为图片,但是发现有的 PDF 文档转换缺失字体,必须要使用ttf格式的字体才行,直接安装到系统不管用,于是到官方文档才发现还需要配置字库,根据说明配置好后问题迎刃而解。
- 官网地址:http://www.xpdfreader.com/
一、报错提示
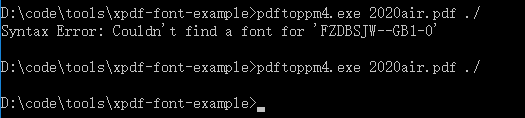
以 pdftoppm 为例,再将 PDF 转换 为 ppm 格式图片的时候会提示缺少两个字体:Symbol、ZapfDingbats

报错信息如下:
Syntax Error: Couldn't find a font for 'FZDBSJW--GB1-0'
其他格式的转换工具也存在同样的问题

搜索得知该字体为:方正大标宋简体,下载安装到系统依然不生效
二、官网解决方案
1. 官网配置说明
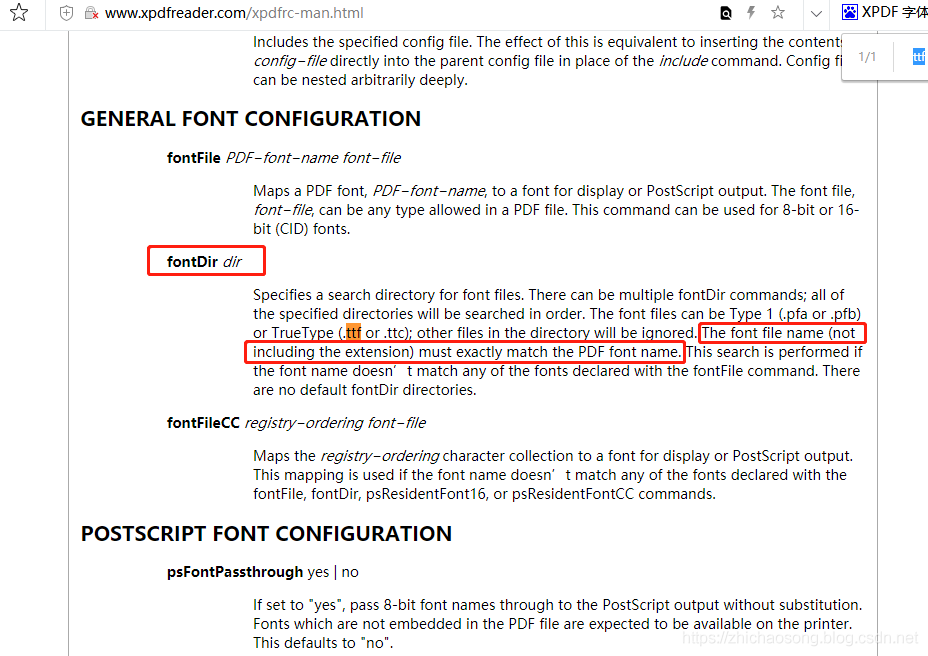
① 在官网寻找 ttf格式字体的配置方式,发现里面 有个 xpdfrc配置文件,里面有配置字体的方式,意思是建一个文件夹存放 ttf字体,然后名字必须和报错的信息一致
http://www.xpdfreader.com/xpdfrc-man.html
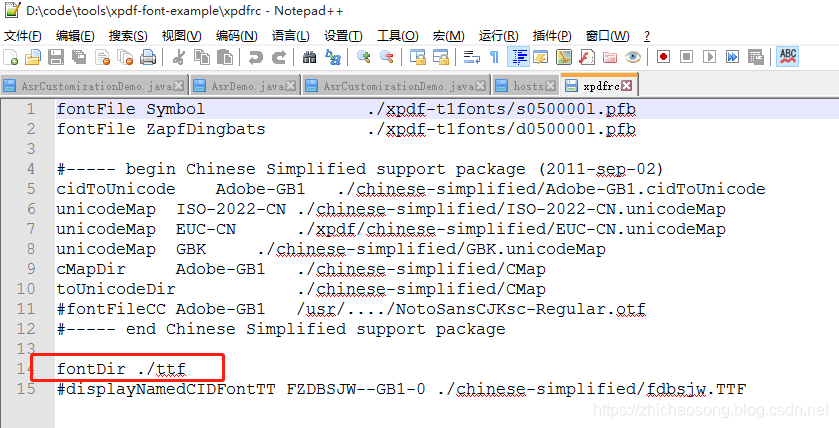
② 于是我也新建了个名为 xpdfrc的文件,注意不要有后缀,然后把字体路径配置好
③ 重新运行发现不报错了
三、xpdfrc 完整配置
大家在运行目录下建个 xpdfrc 文件,然后复制这段配置,再改好路径即可,后面我给出下载地址
fontFile Symbol ./xpdf-t1fonts/s050000l.pfb
fontFile ZapfDingbats ./xpdf-t1fonts/d050000l.pfb
#----- begin Chinese Simplified support package (2011-sep-02)
cidToUnicode Adobe-GB1 ./chinese-simplified/Adobe-GB1.cidToUnicode
unicodeMap ISO-2022-CN ./chinese-simplified/ISO-2022-CN.unicodeMap
unicodeMap EUC-CN ./xpdf/chinese-simplified/EUC-CN.unicodeMap
unicodeMap GBK ./chinese-simplified/GBK.unicodeMap
cMapDir Adobe-GB1 ./chinese-simplified/CMap
toUnicodeDir ./chinese-simplified/CMap
#fontFileCC Adobe-GB1 /usr/..../NotoSansCJKsc-Regular.otf
#----- end Chinese Simplified support package
fontDir ./ttf
#displayNamedCIDFontTT FZDBSJW--GB1-0 ./chinese-simplified/fdbsjw.TTF
五、配置示例下载
① 压缩包附带语言包、语言包配置文件、官网下载的原文件,解压后可直接运行
② 下载地址
https://download.csdn.net/download/zhichaosong/11527883
相关链接:
- 解决Windows下xpdf转换中文pdf时报错字库缺失问题 - 图文教程
https://blog.csdn.net/zhichaosong/article/details/99305338
