1. 概念
Beautiful Soup是一个可以从HTML或XML文件中提取数据(解析)的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性。
HTML文档,是由一组尖括号构成的标签组织起来的,每对尖括号形成了一对标签,而标签之间存在上下级关系,形成了一个标签树。
<html>
<body>
<p class="title"...</p>
</body>
</html>
Beautiful Soup库是解析、遍历、维护“标签树‘的功能库。
2. 标签的具体形式
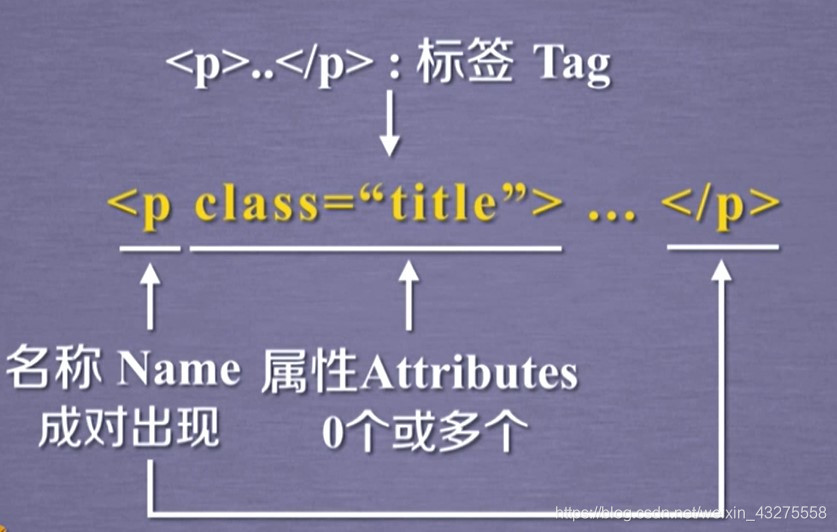
这里的话,建议猿友们去了解下HTML格式,不需要了解多深,大概能看懂组织形式即可。举例:P标签
3. Beautiful Soup 对象初始化
安装bs4库:
pip install beautifulsoup4
导入Beautiful Soup 库
from bs4 import BeautifulSoup
将一段文档(HTML文档)传入 BeautifulSoup 的构造方法(最后一行代码),就能得到一个文档对象soup。如下代码所示,文档通过请求url获取:
import requests
from bs4 import BeautifulSoup #BeautifulSoup是一个类
r=requests.get("http://python123.io/ws/demo.html")
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser") #两个参数,第一个是要解析的文档对象,第二个是“html的解析器”
Beautiful Soup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,'html.parser') | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,'lxml') | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,'xml') | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,'html5lib') | pip install html5lib |
4. Beautiful Soup类的基本元素
| 基本元素 | 说明 |
|---|---|
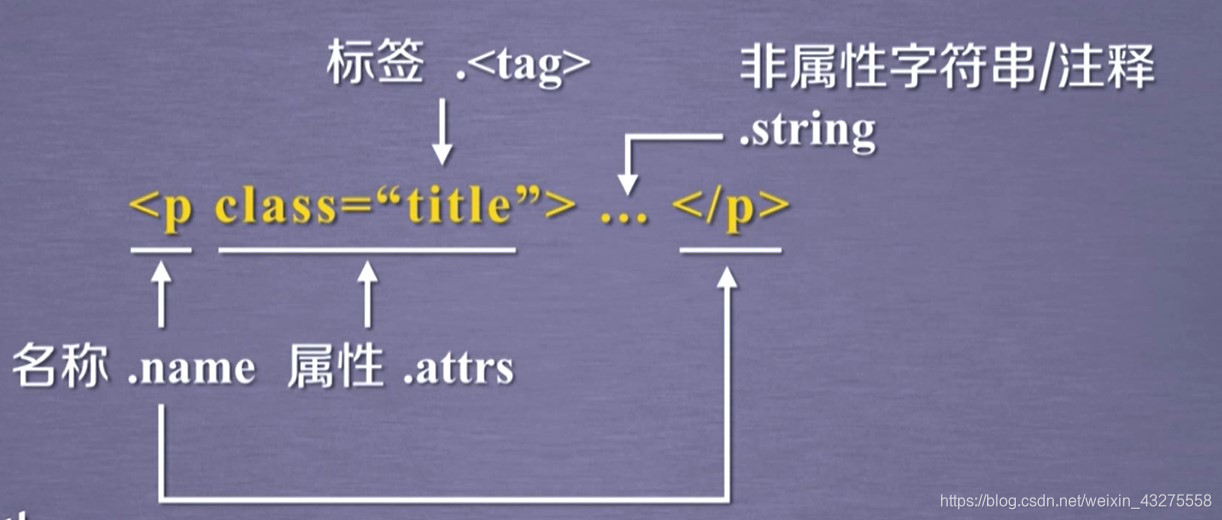
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,< p>…</ p>的名字是‘p’,格式:< tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:< tag>.attrs |
| NaviableString | 标签内非属性字符串,<>…</>中字符串,格式:< tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
这里先给出一个标签树的代码:
import requests
from bs4 import BeautifulSoup
r=requests.get("http://python123.io/ws/demo.html")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.prettify()) #重新排版,增强可读性,运行结果就是HTML文档的标签树形式
运行结果是一个标签树(如下,也可以说是HTML文档的一种清晰的表现形式),下面的所有实例都用这个标签树实现。
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
对于每个基本元素,都用几个典型的实例来讲解,加深印象。(注意和上边的标签树比对着看,这样才有效果~~)多看注释,注释里面讲解了比较重要的点。
- 标签、标签的名字——Tag、Name
>>> import requests
>>> from bs4 import BeautifulSoup
>>> r=requests.get("http://python123.io/ws/demo.html")
>>> r.encoding=r.apparent_encoding
>>> demo=r.text
>>> soup=BeautifulSoup(demo,"html.parser")
>>> soup.title #页面的标题
<title>This is a python demo page</title>
>>> soup.a #实际上我们知道a标签有两个,这样写,默认打印第一个出现的a标签。
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.a.name #a标签的名字
'a'
>>> soup.a.parent.name #a标签父亲标签的名字,也就是包含a标签的上一层标签
'p'
>>> soup.a.parent.parent.name #a标签爷爷标签的名字
'body'
- 标签的属性——Attributes
>>> tag=soup.a
>>> tag.attrs #a标签的属性,返回的是字典类型
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
>>> tag.attrs['class'] #a标签的属性中,class所对应的值,列表类型
['py1']
>>> tag.attrs['href'] #a标签的属性中,href所对应的值
'http://www.icourse163.org/course/BIT-268001'
>>> type(tag.attrs) #a标签属性的类型,是字典
<class 'dict'>
>>> type(tag) #a标签的标签类型
<class 'bs4.element.Tag'>
- 标签内非属性的字符串——NaviableString
>>> soup.a
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.a.string
'Basic Python'
>>> soup.p
<p class="title"><b>The demo python introduces several python courses.</b></p>
>>> soup.p.string #p标签中实际还包含了b标签,但打印的却并不包含b标签。说明NavigableString是可以跨越多个标签层次的
'The demo python introduces several python courses.'
>>> type(soup.p.string)
<class 'bs4.element.NavigableString'> #bs4库定义的类型
- 标签内字符串的注释部分——Comment
在HTML页面表达中, '<! ’ 表示一个注释的开始。
>>> newsoup=BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>","html.parser")
>>> newsoup.b.string #注释和字符串都可以用.string来打印
'This is a comment'
>>> type(newsoup.b.string)
<class 'bs4.element.Comment'>
>>> newsoup.p.string #有的时候我们需要对标签内字符串进行类型判断,因为他可能是注释
'This is not a comment'
>>> type(newsoup.p.string)
<class 'bs4.element.NavigableString'> #bs4库定义的类型

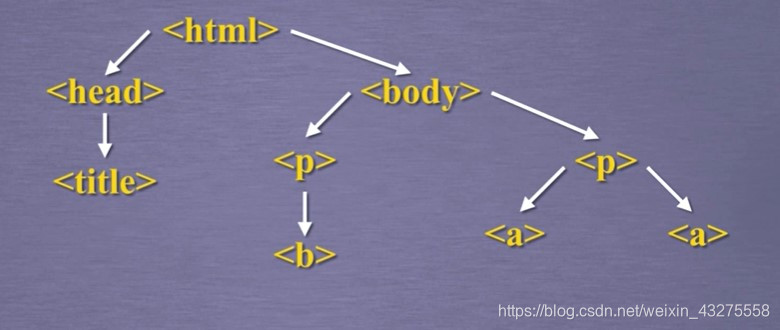
5. Beautiful Soup HTML遍历方法
将上面的HTML标签树进行简化,把他变成更像树的样子。,如下(并不完整,只是一个例子,为了理解而已):
由于Beautiful Soup库是对标签树功能遍历的集合,遍历可以分为上行遍历、下行遍历、平行遍历。下面分别介绍一下。
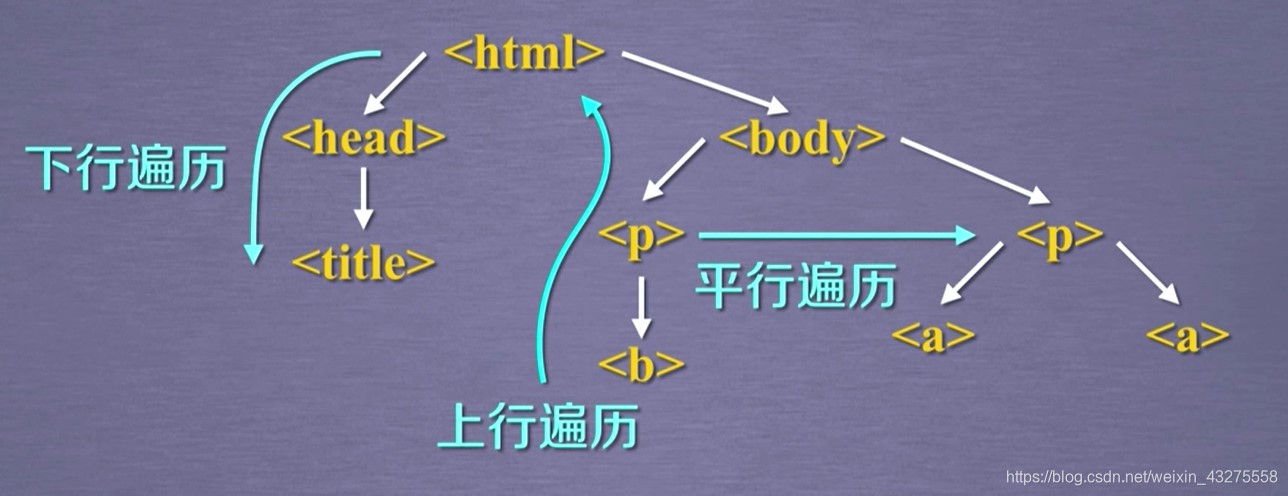
- 标签树的下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将< tag>所有儿子结点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子结点 |
| .descendants | 子孙结点的迭代类型,包含所有子孙结点,用于循环遍历 |
代码实例:
>>> soup.head #head标签
<head><title>This is a python demo page</title></head>
>>> soup.head.contents
[<title>This is a python demo page</title>]
>>> soup.body.contents #对一个标签的儿子节点,并不仅仅包括标签节点,也包括字符串节点。比如像’\n‘
['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
>>> len(soup.body.contents)
5
>>> soup.body.contents[1]
<p class="title"><b>The demo python introduces several python courses.</b></p>
#遍历儿子节点
for child in soup.body.children:
print(child)
#遍历子孙节点
for child in soup.body.descendants:
print(child)
- 标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 子节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
代码实例:
>>> soup.title.parent
<head><title>This is a python demo page</title></head>
>>> soup.html.parent #因为html标签是根节点,所以他的父亲节点是他自己
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
>>> soup.parent #soup的父亲为None
- 标签树的平行遍历
| 属性 | 说明 |
|---|---|
| .next_silbling | 返回按照HTML文本顺序的下一个平行节点 |
| .previous_silbling | 返回按照HTML文本顺序的上一个平行节点 |
| .next_silblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点 |
| .previous_silblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点 |
代码实例:
>>> soup.a.next_sibling #平行遍历发生在同一父节点下的各节点之间。标签之间的NavigableString也构成标签树平行的节点。
' and '
>>> soup.a.next_sibling.next_sibling
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
>>> soup.a.previous_sibling
'Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n'
>>> soup.a.previous_sibling.previous_sibling #为空
>>> soup.a.parent
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
#遍历后续节点
for sibling in soup.a.next_siblings:
print(sibling)
#遍历前续节点
for sibling in soup.a.previous_siblings:
print(sibling)
6. 基于bs4库的HTML格式化
这里主要介绍,bs4库的prettify()方法。你可以认为这个方法是让输出显得更加有条理,更容易被程序识别。你可以试试,使用prettify()方法和不使用prettify()方法的区别,一看便知。最后一句便是方法的实现。
import requests
from bs4 import BeautifulSoup
r=requests.get("http://python123.io/ws/demo.html")
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
print(soup.prettify()) #重新排版,增强可读性,运行结果就是HTML文档的标签树形式
7. 总结
文章总结了Beautiful Soup库的一些基本使用方法。对于做一些简单的HTML解析已经足够用了。是非常好的爬虫入门~
如果说有什么建议的话,就是实践!一点点的敲,一点点的试,当你敲完所有代码的时候,你就会发现,东西已经在你的脑子里了~~
本宝才疏学浅,文章如有不当之处,还请多多指教~~ (●′ω`●)
