转自:https://blog.csdn.net/wendox/article/details/52505971
光流法的目标是完成图像点的跟踪, 因此这里假设存在一个输入图像I, 以及要跟踪的点x, 存在另外一个图像块T, 我们的目标是完成图像块T到输入图像I的匹配.
文章针对Lucas-Canade光流法做了一个总结,
文章对lucas-canade (Forward Additive, FA)算法做了简介, 引入了Compositional算法以及Inverse方法. 因此对应组合形成4种方法分别是Forward Additive(FA), Forward Compositional(FC)以及新提出的Inverse Compositional(IC)算法, Inverse Additive(IA)算法. 对这4种方法文章分别从算法的目标, 算法的推导, 算法对wrap矩阵的要求, 算法计算复杂度以及算法与其他方法的等效情况.
除了四种方法的原理, 文章还介绍了几种优化方法如何实现上述光流的计算. 从高斯牛顿开始介绍, 文章介绍了牛顿法的原理以及对牛顿法的改进. 高斯牛顿法是对牛顿法的一种近似. 当牛顿法中的Hessian矩阵使用雅克比近似时, 牛顿法变为高斯牛顿. 当Hessian矩阵使用c*I(对角为c, 其他元素为0)的矩阵, 牛顿法变为梯度下降法.
Lucas-Kanade 光流法简介

| 增量方式\更新方式 | forward | inverse |
|---|---|---|
| additive | FAIA | IAIA |
| compositional | FCIA | ICIA |
前向与后向的对比
前向方法对于输入图像进行参数化(包括仿射变换及放射增量). 后向方法则同时参数输入图像和模板图像, 其中输入图像参数化仿射变换, 模板图像参数参数化仿射增量. 因此后向方法的计算量显著降低. 由于图像灰度值和运动参数非线性, 整个优化过程为非线性的.
参数化过程主要要计算: 图像的梯度, 位置对运动参数导数, 运动参数增量. 前向方法中Hessian是运动参数的函数. 提高效率的主要思想是交换模板图像和输入图像的角色.
后向方法在迭代中Hessian是固定的.
前向方法和后向方法在目标函数上不太一样,一个是把运动向量pp都是跟着I(被匹配图像),但是前向方法中的迭代的微小量ΔpΔp使用I计算的,后巷方法中的ΔpΔp使用T计算的。因此计算雅克比矩阵的时候,一个的微分在ΔpΔp处,而另外一个在0处。所以如果使用雅克比矩阵计算Hessian矩阵,后者计算的结果是固定的。
举例:
FAIA的目标函数(前向方法)
ICIA的目标函数(后向方法)
如果使用一阶泰勒展开FAIA(前向方法)的目标函数变为
ICIA(后向方法)的泰勒展开为
而雅克比矩阵为
只和xy有关,图像I的梯度是要在 W(x;p)W(x;p) 处计算的,后向方法中图像T的梯度在 W(x;0)W(x;0) 处计算,因此Hessian矩阵不依赖与处计算,因此Hessian矩阵不依赖与 pp 。 后向方法中对模板图像参数化, Hessian矩阵只需要计算一次. 因为模板是在迭代过程中(优化 pp )的每一步固定的。因此会减小计算量。而对输入图像参数化, 由于输入图像的位置是运动的函数, 因此运动参数变化后, 梯度需要重新求解.
Compositional 与 Additive对比
通过增量的表示方式来区分方法. 迭代更新运动参数的时候,如果迭代的结果是在原始的值(6个运动参数)上增加一个微小量,那么称之为Additive,如果在仿射矩阵上乘以一个矩阵(增量运动参数形成的增量仿射矩阵),这方法称之为Compositional。两者理论上是等效的,而且计算量也差不多。
算法的目标
FAIA:
FCIA:
ICIA以及,IAIA:
对于warp的要求
FAIA: W(x,p)W(x,p)对于pp可微.
FCIA: warp集合包含identitywarp, warp集合包含在Composition操作上是闭的(semi-group), 其中包括Homograph, 3D rotation等.
ICIA: semi-group, 另外要求增量warp可逆, 其中包括Homograph, 3D rotation等, 但不包括piece wise affine.
IAIA: 适用于2D平移, 2D相似, 2D仿射等.
算法简介
FAIA
目标函数为
更新的方式为
步进的计算方法为
算法每个步骤中的时间复杂度

伪代码

FCIA
目标函数为
更新方式为
步进的计算
ICIA
为了避免花费很多时间来计算hessian矩阵,如果该矩阵是恒定的,那么只需要计算一次.然后事实上Hessian矩阵是关于pp的函数,很多研究给出了该矩阵的近似计算方法,然而很难估计近似的效果,有的时候近似不是很完善.提出该方法的出发点是交换图像和模板,
文章给出了前向和反向的方法是等效的,并给出了证明. 
对比IAIA发现ICIA的迭代中不需要对图像梯度进行wrap, 另外计算Hessian中同样如此.
IAIA
仍然是交换I和T. 这样可以避免每个迭代中计算梯度图像.
update
实际上这种方法能够使用的运动很少, 对于warp的要求很高, 因此不常用. 文中之后给出了the Inverse Additive 和 Compositional Algorithms 方法在 Affine Warps中的等效性.
总结
- 两个前向方法的计算复杂度相似,后向方法几乎相等.后向方法的速度远比前向方法要快.
- 前向additive可以用于任何变形(warp),
- 反向compositional只能用于warps that form groups.
- 反向additive 可以用于simple 2D linear warps such as translations and affine warps.
如果不进考虑效率的话可以使用两种前向方法.前向compositional的方法中Jacobian是常量,因此有一定的优势.
如果效率很重要的话,那么后向compositional方法是首选,推导很简单,很容易确定.
雅克比矩阵和残差计算的方式有关, 由于 compositional 计算误差的方式会使得雅克比矩阵为常数,通常采用compositional的形式
梯度下降方法的近似
文章介绍了4种方法分别是高斯牛顿, LM, 梯度下降和Hessian矩阵对角近似. 对这些方法文章分别进行了分step性能, iteration性能等的测试.
牛顿法中通过对Hessian使用雅克比矩阵近似可以得到高斯牛顿.
| Algorithm | order of the Taylor approximations | Hessian | work better at |
|---|---|---|---|
| The Gauss-Newton Algorithm | first order | approximations to the Hessian | |
| The Newton Algorithm | sendond order | ||
| Steepest Descent | - | indentity matrix | furhter away from lcoal local minima |
| The Levenberg-Marquardt Algorithm | combine diagonal and full Hessian | error gets worse |
结论
- Gauss-Newton 和 Levenberg-Marquardt的收敛性能类似, 但跟另外2种方法稍好.
- Levenberg-Marquardt实现的效率和Gauss-Newton接近, 并且不好好于高斯牛顿.
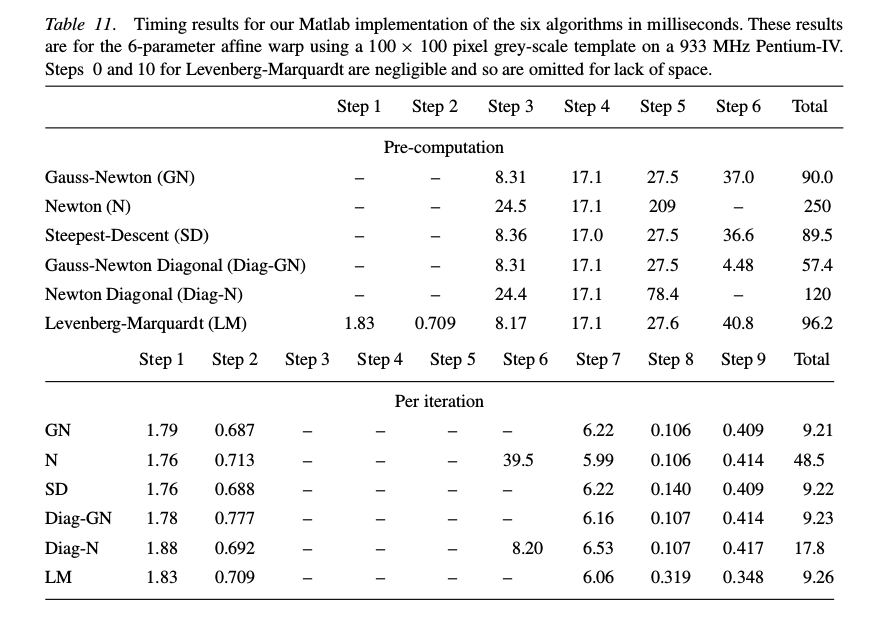
算法的选择
- 噪声,如果图像的噪声比较大,那么最好使用反向算法,反之使用前向方法.
- 关于效率的已经讨论过了.