top命令
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。下面详细介绍它的使用方法。top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
1.命令格式:
top [参数]
2.命令功能:
显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等
3.命令参数:
-b 批处理
-c 显示完整的治命令
-I 忽略失效过程
-s 保密模式
-S 累积模式
-i<时间> 设置间隔时间
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
4.使用实例:
实例1:显示进程信息
命令:
top
输出:
[root@TG1704 log]# top
top - 14:06:23 up 70 days, 16:44, 2 users, load average: 1.25, 1.32, 1.35
Tasks: 206 total, 1 running, 205 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.9%us, 3.4%sy, 0.0%ni, 90.4%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 32949016k total, 14411180k used, 18537836k free, 169884k buffers
Swap: 32764556k total, 0k used, 32764556k free, 3612636k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28894 root 22 0 1501m 405m 10m S 52.2 1.3 2534:16 java
18249 root 18 0 3201m 1.9g 11m S 35.9 6.0 569:39.41 java
2808 root 25 0 3333m 1.0g 11m S 24.3 3.1 526:51.85 java
25668 root 23 0 3180m 704m 11m S 14.0 2.2 360:44.53 java
574 root 25 0 3168m 611m 10m S 12.6 1.9 556:59.63 java
1599 root 20 0 3237m 1.9g 11m S 12.3 6.2 262:01.14 java
1008 root 21 0 3147m 842m 10m S 0.3 2.6 4:31.08 java
13823 root 23 0 3031m 2.1g 10m S 0.3 6.8 176:57.34 java
28218 root 15 0 12760 1168 808 R 0.3 0.0 0:01.43 top
29062 root 20 0 1241m 227m 10m S 0.3 0.7 2:07.32 java
1 root 15 0 10368 684 572 S 0.0 0.0 1:30.85 init
2 root RT -5 0 0 0 S 0.0 0.0 0:01.01 migration/0
3 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
4 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
5 root RT -5 0 0 0 S 0.0 0.0 0:00.80 migration/1
6 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/1
7 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/1
8 root RT -5 0 0 0 S 0.0 0.0 0:20.59 migration/2
9 root 34 19 0 0 0 S 0.0 0.0 0:00.09 ksoftirqd/2
10 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/2
11 root RT -5 0 0 0 S 0.0 0.0 0:23.66 migration/3
12 root 34 19 0 0 0 S 0.0 0.0 0:00.03 ksoftirqd/3
13 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/3
14 root RT -5 0 0 0 S 0.0 0.0 0:20.29 migration/4
15 root 34 19 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/4
16 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/4
17 root RT -5 0 0 0 S 0.0 0.0 0:23.07 migration/5
18 root 34 19 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/5
19 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/5
20 root RT -5 0 0 0 S 0.0 0.0 0:17.16 migration/6
21 root 34 19 0 0 0 S 0.0 0.0 0:00.05 ksoftirqd/6
22 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/6
23 root RT -5 0 0 0 S 0.0 0.0 0:58.28 migration/7
说明:
统计信息区:
前五行是当前系统情况整体的统计信息区。下面我们看每一行信息的具体意义。
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
第四行,内存状态,具体信息如下:
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
备注:
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:18537836k +169884k +3612636k = 22GB左右。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
其他使用技巧:
1.多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。再按数字键1,就会返回到top基本视图界面。
2.高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
我们发现进程id为2570的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
3.进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的,在下图中进程ID为28894的java进程排在第一(cpu占用142%),进程ID为574的java进程排在第二(cpu占用16%)。
敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
可以看到,top默认的排序列是“%CPU”。
4. 通过”shift + >”或”shift + <”可以向右或左改变排序列
下图是按一次”shift + >”的效果图,视图现在已经按照%MEM来排序。
实例2:显示 完整命令
命令:
top -c
输出:
说明:
实例3:以批处理模式显示程序信息
命令:
top -b
输出:
说明:
实例4:以累积模式显示程序信息
命令:
top -S
输出:
说明:
实例5:设置信息更新次数
命令:
top -n 2
输出:
说明:
表示更新两次后终止更新显示
实例6:设置信息更新时间
命令:
top -d 3
输出:
说明:
表示更新周期为3秒
实例7:显示指定的进程信息
命令:
top -p 574
输出:
说明:
5.top交互命令
在top 命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了s 选项, 其中一些命令可能会被屏蔽。
h 显示帮助画面,给出一些简短的命令总结说明
k 终止一个进程。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序
r 重新安排一个进程的优先级别
S 切换到累计模式
s 改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s
f或者F 从当前显示中添加或者删除项目
o或者O 改变显示项目的顺序
l 切换显示平均负载和启动时间信息
m 切换显示内存信息
t 切换显示进程和CPU状态信息
c 切换显示命令名称和完整命令行
M 根据驻留内存大小进行排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中
vmstat命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。
物理内存和虚拟内存区别
我们知道,直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成,而内存是有限的,这样就引出了物理内存与虚拟内存的概念。
物理内存就是系统硬件提供的内存大小,是真正的内存,相对于物理内存,在linux下还有一个虚拟内存的概念,虚拟内存就是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。
作为物理内存的扩展,linux会在物理内存不足时,使用交换分区的虚拟内存,更详细的说,就是内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
linux的内存管理采取的是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。
要深入了解linux内存运行机制,需要知道下面提到的几个方面:
首先,Linux系统会不时的进行页面交换操作,以保持尽可能多的空闲物理内存,即使并没有什么事情需要内存,Linux也会交换出暂时不用的内存页面。这可以避免等待交换所需的时间。
其次,linux进行页面交换是有条件的,不是所有页面在不用时都交换到虚拟内存,linux内核根据”最近最经常使用“算法,仅仅将一些不经常使用的页面文件交换到虚拟内存,有时我们会看到这么一个现象:linux物理内存还有很多,但是交换空间也使用了很多。其实,这并不奇怪,例如,一个占用很大内存的进程运行时,需要耗费很多内存资源,此时就会有一些不常用页面文件被交换到虚拟内存中,但后来这个占用很多内存资源的进程结束并释放了很多内存时,刚才被交换出去的页面文件并不会自动的交换进物理内存,除非有这个必要,那么此刻系统物理内存就会空闲很多,同时交换空间也在被使用,就出现了刚才所说的现象了。关于这点,不用担心什么,只要知道是怎么一回事就可以了。
最后,交换空间的页面在使用时会首先被交换到物理内存,如果此时没有足够的物理内存来容纳这些页面,它们又会被马上交换出去,如此以来,虚拟内存中可能没有足够空间来存储这些交换页面,最终会导致linux出现假死机、服务异常等问题,linux虽然可以在一段时间内自行恢复,但是恢复后的系统已经基本不可用了。
因此,合理规划和设计linux内存的使用,是非常重要的。
虚拟内存原理
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。尽管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
常见命令展示
|
1
|
vmstat 5 5 【在5秒时间内进行5次采样】
|

字段说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。【interrupt】
cs: 每秒上下文切换数。 【count/second】
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
备注:
如果r经常大于4,id经常少于40,表示cpu的负荷很重。
如果bi,bo长期不等于0,表示内存不足。
如果disk经常不等于0,且在b中的队列大于3,表示io性能不好。
Linux在具有高稳定性、可靠性的同时,具有很好的可伸缩性和扩展性,能够针对不同的应用和硬件环境调整,优化出满足当前应用需要的最佳性能。因此企业在维护Linux系统、进行系统调优时,了解系统性能分析工具是至关重要的。
显示活跃和非活跃内存
vmstat -a 2 5 【-a 显示活跃和非活跃内存,所显示的内容除增加inact和active】
显示从系统启动至今的fork数量
vmstat -f 【 linux下创建进程的系统调用是fork】
说明: 信息是从/proc/stat中的processes字段里取得的
查看内存使用的详细信息
vmstat -s 【显示内存相关统计信息及多种系统活动数量】
说明:这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat
查看磁盘的读/写
vmstat -d 【查看磁盘的读写】
说明:这些信息主要来自于/proc/diskstats.
查看/dev/sda1磁盘的读/写
vmstat -p /dev/sda1 【显示指定磁盘分区统计信息】
说明:这些信息主要来自于/proc/diskstats.
reads:来自于这个分区的读的次数。
read sectors:来自于这个分区的读扇区的次数。
writes:来自于这个分区的写的次数。
requested writes:来自于这个分区的写请求次数。
查看系统的slab信息
vmstat -m
说明:这些信息主要来自于/proc/slabinfo
slab:由于内核会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry,这些对象如果每次构建的时候就向内存要一个页(4kb),这样就会非常浪费,为了解决这个问题,就引入了一种新的机制来处理在同一个页框中如何分配小存储区,而slab可以对小对象进行分配,这样就不用为每一个对象分配页框,从而节省了空间,内核对一些小对象创建析构很频繁,slab对这些小对象进行缓冲,可以重复利用,减少内存分配次数。
查看进程路径
[root@localhost ~]# netstat -an | grep 2158
[root@localhost ~]# ll /proc/2158
cwd符号链接的是进程运行目录;
exe符号连接就是执行程序的绝对路径;
cmdline就是程序运行时输入的命令行命令;
environ记录了进程运行时的环境变量;
fd目录下是进程打开或使用的文件的符号连接。
lsof -p 2158





pidstat命令
引言
在查看系统资源使用情况时,很多工具为我们提供了从设备角度查看的方法。例如使用iostat查看磁盘io统计信息:
linux:~ # iostat -d 3 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn sda 1.67 0.00 40.00 0 120
以上显示的是从sda的角度统计的结果。当我们需要从进程的角度,查看每个进程使用系统资源的情况,有什么方法吗?
使用pidstat工具可以获取每个进程使用cpu、内存和磁盘等系统资源的统计信息,pidstat由sysstat rpm包提供,可在suse11使用。下面我们来看pidstat的具体用法。
默认输出
执行pidstat,将输出系统启动后所有活动进程的cpu统计信息:
linux:~ # pidstat Linux 2.6.32.12-0.7-default (linux) 06/18/12 _x86_64_ 11:37:19 PID %usr %system %guest %CPU CPU Command …… 11:37:19 11452 0.00 0.00 0.00 0.00 2 bash 11:37:19 11509 0.00 0.00 0.00 0.00 3 dd
以上输出,除最开头一行显示内核版本、主机名、日期和cpu架构外,主要列含义如下:
- 11:37:19: pidstat获取信息时间点
- PID: 进程pid
- %usr: 进程在用户态运行所占cpu时间比率
- %system: 进程在内核态运行所占cpu时间比率
- %CPU: 进程运行所占cpu时间比率
- CPU: 指示进程在哪个核运行
- Command: 拉起进程对应的命令
执行pidstat默认输出信息为系统启动后到执行时间点的统计信息,因而即使当前某进程的cpu占用率很高,输出中的值有可能仍为0。
指定采样周期和采样次数
像sar、iostat等命令一样,也可以给pidstat命令指定采样周期和采样次数,命令形式为”pidstat [option] interval [count]”,以下pidstat输出以2秒为采样周期,输出2次cpu使用统计信息:
linux:~ # pidstat 2 2 Linux 2.6.32.12-0.7-default (linux) 06/18/12 _x86_64_ 14:40:39 PID %usr %system %guest %CPU CPU Command 14:40:41 9567 0.50 1.49 0.00 1.98 2 atop 14:40:41 12405 0.00 0.50 0.00 0.50 6 pidstat 14:40:41 PID %usr %system %guest %CPU CPU Command 14:40:43 7830 0.50 0.50 0.00 1.00 7 runHpiAlarm 14:40:43 12405 0.00 1.00 0.00 1.00 6 pidstat
若不指定统计次数count,则pidstat将一直输出统计信息。
cpu使用情况统计(-u)
使用-u选项,pidstat将显示各活动进程的cpu使用统计,执行”pidstat -u”与单独执行”pidstat”的效果一样。
内存使用情况统计(-r)
使用-r选项,pidstat将显示各活动进程的内存使用统计:
linux:~ # pidstat -r -p 13084 1 Linux 2.6.32.12-0.7-default (linux) 06/18/12 _x86_64_ 15:08:18 PID minflt/s majflt/s VSZ RSS %MEM Command 15:08:19 13084 133835.00 0.00 15720284 15716896 96.26 mmmm 15:08:20 13084 35807.00 0.00 15863504 15849756 97.07 mmmm 15:08:21 13084 19273.87 0.00 15949040 15792944 96.72 mmmm
以上各列输出的含义如下:
- minflt/s: 每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地址映射成物理内存地址产生的page fault次数
- majflt/s: 每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生
- VSZ: 该进程使用的虚拟内存(以kB为单位)
- RSS: 该进程使用的物理内存(以kB为单位)
- %MEM: 该进程使用内存的百分比
- Command: 拉起进程对应的命令
IO情况统计(-d)
使用-d选项,我们可以查看进程IO的统计信息:
linux:~ # pidstat -d 1 2 Linux 2.6.32.12-0.7-default (linux) 06/18/12 _x86_64_ 17:11:36 PID kB_rd/s kB_wr/s kB_ccwr/s Command 17:11:37 14579 124988.24 0.00 0.00 dd 17:11:37 PID kB_rd/s kB_wr/s kB_ccwr/s Command 17:11:38 14579 105441.58 0.00 0.00 dd
以上主要输出的含义如下:
- kB_rd/s: 每秒进程从磁盘读取的数据量(以kB为单位)
- kB_wr/s: 每秒进程向磁盘写的数据量(以kB为单位)
- Command: 拉起进程对应的命令
针对特定进程统计(-p)
使用-p选项,我们可以查看特定进程的系统资源使用情况:
linux:~ # pidstat -r -p 1 1 Linux 2.6.32.12-0.7-default (linux) 06/18/12 _x86_64_ 18:26:17 PID minflt/s majflt/s VSZ RSS %MEM Command 18:26:18 1 0.00 0.00 10380 640 0.00 init 18:26:19 1 0.00 0.00 10380 640 0.00 init ……
以上pidstat命令以1秒为采样时间间隔,查看init进程的内存使用情况。
pidstat常用命令
使用pidstat进行问题定位时,以下命令常被用到:
pidstat -u 1
pidstat -r 1
pidstat -d 1
以上命令以1秒为信息采集周期,分别获取cpu、内存和磁盘IO的统计信息。
free命令
free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。
如果加上 -h 选项,输出的结果会友好很多:
有时我们需要持续的观察内存的状况,此时可以使用 -s 选项并指定间隔的秒数:
$ free -h -s 3
上面的命令每隔 3 秒输出一次内存的使用情况,直到你按下 ctrl + c。
由于 free 命令本身比较简单,所以本文的重点会放在如何通过 free 命令了解系统当前的内存使用状况。
输出简介
下面先解释一下输出的内容:
Mem 行(第二行)是内存的使用情况。
Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
我想只有在理解了一些基本概念之后,上面的输出才能帮助我们了解系统的内存状况。
buff/cache
先来提一个问题: buffer 和 cache 应该是两种类型的内存,但是 free 命令为什么会把它们放在一起呢?要回答这个问题需要我们做些准备工作。让我们先来搞清楚 buffer 与 cache 的含义。
buffer 在操作系统中指 buffer cache, 中文一般翻译为 "缓冲区"。要理解缓冲区,必须明确另外两个概念:"扇区" 和 "块"。扇区是设备的最小寻址单元,也叫 "硬扇区" 或 "设备块"。块是操作系统中文件系统的最小寻址单元,也叫 "文件块" 或 "I/O 块"。每个块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。当一个块被调入内存时,它要存储在一个缓冲区中。每个缓冲区与一个块对应,它相当于是磁盘块在内存中的表示(下图来自互联网):
注意,buffer cache 只有块的概念而没有文件的概念,它只是把磁盘上的块直接搬到内存中而不关心块中究竟存放的是什么格式的文件。
cache 在操作系统中指 page cache,中文一般翻译为 "页高速缓存"。页高速缓存是内核实现的磁盘缓存。它主要用来减少对磁盘的 I/O 操作。具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。页高速缓存缓存的是内存页面。缓存中的页来自对普通文件、块设备文件(这个指的就是 buffer cache 呀)和内存映射文件的读写。
页高速缓存对普通文件的缓存我们可以这样理解:当内核要读一个文件(比如 /etc/hosts)时,它会先检查这个文件的数据是不是已经在页高速缓存中了。如果在,就放弃访问磁盘,直接从内存中读取。这个行为称为缓存命中。如果数据不在缓存中,就是未命中缓存,此时内核就要调度块 I/O 操作从磁盘去读取数据。然后内核将读来的数据放入页高速缓存中。这种缓存的目标是文件系统可以识别的文件(比如 /etc/hosts)。
页高速缓存对块设备文件的缓存就是我们在前面介绍的 buffer cahce。因为独立的磁盘块通过缓冲区也被存入了页高速缓存(缓冲区最终是由页高速缓存来承载的)。
到这里我们应该搞清楚了:无论是缓冲区还是页高速缓存,它们的实现方式都是一样的。缓冲区只不过是一种概念上比较特殊的页高速缓存罢了。
那么为什么 free 命令不直接称为 cache 而非要写成 buff/cache? 这是因为缓冲区和页高速缓存的实现并非天生就是统一的。在 linux 内核 2.4 中才将它们统一。更早的内核中有两个独立的磁盘缓存:页高速缓存和缓冲区高速缓存。前者缓存页面,后者缓存缓冲区。当你知道了这些故事之后,输出中列的名称可能已经不再重要了。
free 与 available
在 free 命令的输出中,有一个 free 列,同时还有一个 available 列。这二者到底有何区别?
free 是真正尚未被使用的物理内存数量。至于 available 就比较有意思了,它是从应用程序的角度看到的可用内存数量。Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是我们介绍的 buffer 和 cache。所以对于内核来说,buffer 和 cache 都属于已经被使用的内存。当应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说,available = free + buffer + cache。请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
交换空间(swap space)
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。在 ubuntu 系统中,swappiness 的默认值是 60。如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness:
vm.swappiness=10
如果系统的内存不足,则需要根据物理内存的大小来设置交换空间的大小。具体的策略网上有很丰富的资料,这里笔者不再赘述。
/proc/meminfo 文件
其实 free 命令中的信息都来自于 /proc/meminfo 文件。/proc/meminfo 文件包含了更多更原始的信息,只是看起来不太直观:
$ cat /proc/meminfo
有兴趣的同学可以直接查看这个文件。
总结
free 命令是一个既简单又复杂的命令。简单是因为这个命令的参数少,输出结果清晰。说它复杂则是因为它背后是比较晦涩的操作系统中的概念,如果不清楚这些概念,即便看了 free 命令的输出也 get 不到多少有价值的信息。
df命令
linux中df命令的功能是用来检查linux服务器的文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
1.命令格式:
df [选项] [文件]
2.命令功能:
显示指定磁盘文件的可用空间。如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB 为单位进行显示,除非环境变量 POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示
3.命令参数:
必要参数:
-a 全部文件系统列表
-h 方便阅读方式显示
-H 等于“-h”,但是计算式,1K=1000,而不是1K=1024
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地文件系统
-m 区块为1048576字节
--no-sync 忽略 sync 命令
-P 输出格式为POSIX
--sync 在取得磁盘信息前,先执行sync命令
-T 文件系统类型
选择参数:
--block-size=<区块大小> 指定区块大小
-t<文件系统类型> 只显示选定文件系统的磁盘信息
-x<文件系统类型> 不显示选定文件系统的磁盘信息
--help 显示帮助信息
--version 显示版本信息
4.使用实例:
实例1:显示磁盘使用情况
命令:
df
输出:
[root@CT1190 log]# df
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda7 19840892 890896 17925856 5% /
/dev/sda9 203727156 112797500 80413912 59% /opt
/dev/sda8 4956284 570080 4130372 13% /var
/dev/sda6 19840892 1977568 16839184 11% /usr
/dev/sda3 988116 23880 913232 3% /boot
tmpfs 16473212 0 16473212 0% /dev/shm
说明:
linux中df命令的输出清单的第1列是代表文件系统对应的设备文件的路径名(一般是硬盘上的分区);第2列给出分区包含的数据块(1024字节)的数目;第3,4列分别表示已用的和可用的数据块数目。用户也许会感到奇怪的是,第3,4列块数之和不等于第2列中的块数。这是因为缺省的每个分区都留了少量空间供系统管理员使用。即使遇到普通用户空间已满的情况,管理员仍能登录和留有解决问题所需的工作空间。清单中Use% 列表示普通用户空间使用的百分比,即使这一数字达到100%,分区仍然留有系统管理员使用的空间。最后,Mounted on列表示文件系统的挂载点。
实例2:以inode模式来显示磁盘使用情况
命令:
df -i
输出:
[root@CT1190 log]# df -i
文件系统 Inode (I)已用 (I)可用 (I)已用% 挂载点
/dev/sda7 5124480 5560 5118920 1% /
/dev/sda9 52592640 50519 52542121 1% /opt
/dev/sda8 1280000 8799 1271201 1% /var
/dev/sda6 5124480 80163 5044317 2% /usr
/dev/sda3 255232 34 255198 1% /boot
tmpfs 4118303 1 4118302 1% /dev/shm
说明:
实例3:显示指定类型磁盘
命令:
df -t ext3
输出:
[root@CT1190 log]# df -t ext3
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda7 19840892 890896 17925856 5% /
/dev/sda9 203727156 93089700 100121712 49% /opt
/dev/sda8 4956284 570104 4130348 13% /var
/dev/sda6 19840892 1977568 16839184 11% /usr
/dev/sda3 988116 23880 913232 3% /boot
说明:
实例4:列出各文件系统的i节点使用情况
命令:
df -ia
输出:
[root@CT1190 log]# df -ia
文件系统 Inode (I)已用 (I)可用 (I)已用% 挂载点
/dev/sda7 5124480 5560 5118920 1%
/proc 0 0 0 - /proc
sysfs 0 0 0 - /sys
devpts 0 0 0 - /dev/pts
/dev/sda9 52592640 50519 52542121 1% /opt
/dev/sda8 1280000 8799 1271201 1% /var
/dev/sda6 5124480 80163 5044317 2% /usr
/dev/sda3 255232 34 255198 1% /boot
tmpfs 4118303 1 4118302 1% /dev/shm
none 0 0 0 - /proc/sys/fs/binfmt_misc
说明:
实例5:列出文件系统的类型
命令:
df -T
输出:
root@CT1190 log]# df -T
文件系统 类型 1K-块 已用 可用 已用% 挂载点
/dev/sda7 ext3 19840892 890896 17925856 5% /
/dev/sda9 ext3 203727156 93175692 100035720 49% /opt
/dev/sda8 ext3 4956284 570104 4130348 13% /var
/dev/sda6 ext3 19840892 1977568 16839184 11% /usr
/dev/sda3 ext3 988116 23880 913232 3% /boot
tmpfs tmpfs 16473212 0 16473212 0% /dev/shm
说明:
实例6:以更易读的方式显示目前磁盘空间和使用情况
命令:
输出:
[root@CT1190 log]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda7 19G 871M 18G 5% /
/dev/sda9 195G 89G 96G 49% /opt
/dev/sda8 4.8G 557M 4.0G 13% /var
/dev/sda6 19G 1.9G 17G 11% /usr
/dev/sda3 965M 24M 892M 3% /boot
tmpfs 16G 0 16G 0% /dev/shm
[root@CT1190 log]# df -H
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda7 21G 913M 19G 5% /
/dev/sda9 209G 96G 103G 49% /opt
/dev/sda8 5.1G 584M 4.3G 13% /var
/dev/sda6 21G 2.1G 18G 11% /usr
/dev/sda3 1.1G 25M 936M 3% /boot
tmpfs 17G 0 17G 0% /dev/shm
[root@CT1190 log]# df -lh
文件系统 容量 已用 可用 已用% 挂载点
/dev/sda7 19G 871M 18G 5% /
/dev/sda9 195G 89G 96G 49% /opt
/dev/sda8 4.8G 557M 4.0G 13% /var
/dev/sda6 19G 1.9G 17G 11% /usr
/dev/sda3 965M 24M 892M 3% /boot
tmpfs 16G 0 16G 0% /dev/shm
[root@CT1190 log]# df -k
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda7 19840892 890896 17925856 5% /
/dev/sda9 203727156 93292572 99918840 49% /opt
/dev/sda8 4956284 570188 4130264 13% /var
/dev/sda6 19840892 1977568 16839184 11% /usr
/dev/sda3 988116 23880 913232 3% /boot
tmpfs 16473212 0 16473212 0% /dev/shm
说明:
-h更具目前磁盘空间和使用情况 以更易读的方式显示
-H根上面的-h参数相同,不过在根式化的时候,采用1000而不是1024进行容量转换
-k以单位显示磁盘的使用情况
-l显示本地的分区的磁盘空间使用率,如果服务器nfs了远程服务器的磁盘,那么在df上加上-l后系统显示的是过滤nsf驱动器后的结果
-i显示inode的使用情况。linux采用了类似指针的方式管理磁盘空间影射.这也是一个比较关键应用
iostat命令
iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析
常见命令展示
iostat 安装
|
1
|
# iostat属于sysstat软件包。可以直接安装。
|
|
1
|
yum install sysstat
|
显示所有设备负载情况
|
1
|
iostat
|
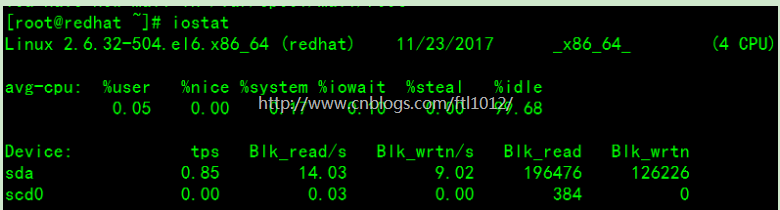
说明:
cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
备注:
如果%iowait的值过高,表示硬盘存在I/O瓶颈
如果%idle值高,表示CPU较空闲
如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。
cpu属性值说明:
tps:该设备每秒的传输次数
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read: 读取的总数据量;
kB_wrtn:写入的总数量数据量;
定时显示所有信息
|
1
2
|
# 【每隔2秒刷新显示,且显示3次】
iostat 2 3
|
显示指定磁盘信息
|
1
|
iostat -d /dev/sda
|
显示tty和Cpu信息
|
1
|
iostat -t
|
以M为单位显示所有信息
|
1
|
iostat -m
|
查看设备使用率(%util)、响应时间(await)
|
1
2
3
|
# 【-d 显示磁盘使用情况,-x 显示详细信息】
# d: detail
iostat -d -x -k 1 1
|

说明:
rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
%util: 一秒中有百分之多少的时间用于 I/O
如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷
idle小于70% IO压力就较大了,一般读取速度有较多的wait。
查看cpu状态
|
1
|
iostat -c 1 1
|

dm含义
iostat语法
用法:iostat [ 选项 ] [ <时间间隔> [ <次数> ]]
常用选项说明:
-c:只显示系统CPU统计信息,即单独输出avg-cpu结果,不包括device结果 -d:单独输出Device结果,不包括cpu结果 -k/-m:输出结果以kB/mB为单位,而不是以扇区数为单位 -x:输出更详细的io设备统计信息 interval/count:每次输出间隔时间,count表示输出次数,不带count表示循环输出
说明:更多选项使用使用man iostat查看
常用实例
1、iostat,结果为从系统开机到当前执行时刻的统计信息
输出含义:
avg-cpu: 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值。重点关注iowait值,表示CPU用于等待io请求的完成时间。
Device: 各磁盘设备的IO统计信息。各列含义如下:
Device: 以sdX形式显示的设备名称 tps: 每秒进程下发的IO读、写请求数量 KB_read/s: 每秒从驱动器读入的数据量,单位为K。 KB_wrtn/s: 每秒从驱动器写入的数据量,单位为K。 KB_read: 读入数据总量,单位为K。 KB_wrtn: 写入数据总量,单位为K。
2、iostat -x -k -d 1 2。每隔1S输出磁盘IO的详细详细,总共采样2次。
以上各列的含义如下:
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并 wrqm/s: 每秒对该设备的写请求被合并次数 r/s: 每秒完成的读次数 w/s: 每秒完成的写次数 rkB/s: 每秒读数据量(kB为单位) wkB/s: 每秒写数据量(kB为单位) avgrq-sz:平均每次IO操作的数据量(扇区数为单位) avgqu-sz: 平均等待处理的IO请求队列长度 await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位) svctm: 平均每次IO请求的处理时间(毫秒为单位) %util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率
重点关注参数
1、iowait% 表示CPU等待IO时间占整个CPU周期的百分比,如果iowait值超过50%,或者明显大于%system、%user以及%idle,表示IO可能存在问题。
2、avgqu-sz 表示磁盘IO队列长度,即IO等待个数。
3、await 表示每次IO请求等待时间,包括等待时间和处理时间
4、svctm 表示每次IO请求处理的时间
5、%util 表示磁盘忙碌情况,一般该值超过80%表示该磁盘可能处于繁忙状态。
疑惑:dm-0/1/2是什么?怎么来的?
查看磁盘信息:
发现根本没有dm字样,那到底怎么来的?
我们根据可以得知:
dm-0、dm-1、dm-2的主设备号是253(是linux内核留给本地使用的设备号),次设备号分别是0、1、2,这类设备在/dev/mapper中
看到dm-0、dm-1、dm-2的详细设备名后,知道这三个设备是属于centos逻辑卷组的lvm设备。
这下找到dm的真正含义了~
ifstat命令
ifstat命令 就像iostat/vmstat描述其它的系统状况一样,是一个统计网络接口活动状态的工具。ifstat工具系统中并不默认安装,需要自己下载源码包,重新编译安装,使用过程相对比较简单。
下载
http://gael.roualland.free.fr/ifstat/ (官网) wget http://gael.roualland.free.fr/ifstat/ifstat-1.1.tar.gz
编译安装
tar -zxvf ifstat-1.1.tar.gz cd ifstat-1.1 ./configure make make install # 默认会安装到/usr/local/bin/目录中
注释:执行which ifstat输出/usr/local/bin/ifstat
选项
-l 监测环路网络接口(lo)。缺省情况下,ifstat监测活动的所有非环路网络接口。经使用发现,加上-l参数能监测所有的网络接口的信息,而不是只监测 lo的接口信息,也就是说,加上-l参数比不加-l参数会多一个lo接口的状态信息。 -a 监测能检测到的所有网络接口的状态信息。使用发现,比加上-l参数还多一个plip0的接口信息,搜索一下发现这是并口(网络设备中有一 个叫PLIP (Parallel Line Internet Protocol). 它提供了并口...) -z 隐藏流量是无的接口,例如那些接口虽然启动了但是未用的 -i 指定要监测的接口,后面跟网络接口名 -s 等于加-d snmp:[comm@][#]host[/nn]] 参数,通过SNMP查询一个远程主机 -h 显示简短的帮助信息 -n 关闭显示周期性出现的头部信息(也就是说,不加-n参数运行ifstat时最顶部会出现网络接口的名称,当一屏显示不下时,会再一次出现接口的名称,提示我们显示的流量信息具体是哪个网络接口的。加上-n参数把周期性的显示接口名称关闭,只显示一次) -t 在每一行的开头加一个时间 戳(能告诉我们具体的时间) -T 报告所有监测接口的全部带宽(最后一列有个total,显示所有的接口的in流量和所有接口的out流量,简单的把所有接口的in流量相加,out流量相 加) -w 用指定的列宽,而不是为了适应接口名称的长度而去自动放大列宽 -W 如果内容比终端窗口的宽度还要宽就自动换行 -S 在同一行保持状态更新(不滚动不换行)注:如果不喜欢屏幕滚动则此项非常方便,与bmon的显示方式类似 -b 用kbits/s显示带宽而不是kbytes/s -q 安静模式,警告信息不出现 -v 显示版本信息 -d 指定一个驱动来收集状态信息
实例
默认使用
[root@localhost ifstat-1.1] #ifstat
eth0 eth1
KB/s in KB/s out KB/s in KB/s out
0.07 0.20 0.00 0.00
0.07 0.15 0.58 0.00
默认ifstat不监控回环接口,显示的流量单位是KB。
[root@localhost ifstat-1.1]# ifstat -tT time eth0 eth1 eth2 eth3 Total HH:MM:ss KB/s in KB/s out KB/s in KB/s out KB/s in KB/s out KB/s in KB/s out KB/s in KB/s out 16:53:04 0.84 0.62 1256.27 1173.05 0.12 0.18 0.00 0.00 1257.22 1173.86 16:53:05 0.57 0.40 0.57 0.76 0.00 0.00 0.00 0.00 1.14 1.17 16:53:06 1.58 0.71 0.42 0.78 0.00 0.00 0.00 0.00 2.01 1.48 16:53:07 0.57 0.40 1.91 2.61 0.00 0.00 0.00 0.00 2.48 3.01 16:53:08 0.73 0.40 924.02 1248.91 0.00 0.00 0.00 0.00 924.76 1249.31
监控所有网络接口
[root@localhost ifstat-1.1] # ifstat -a
lo eth0 eth1
KB/s in KB/s out KB/s in KB/s out KB/s in KB/s out
0.00 0.00 0.28 0.58 0.06 0.06
0.00 0.00 1.41 1.13 0.00 0.00
0.61 0.61 0.26 0.23 0.00 0.00
参考:https://www.cnblogs.com/peida/archive/2012/12/24/2831353.html、https://www.cnblogs.com/ftl1012/p/vmstat.html、
https://www.cnblogs.com/bangerlee/articles/2555307.html、https://www.cnblogs.com/ultranms/p/9254160.html、
https://www.cnblogs.com/peida/archive/2012/12/07/2806483.html、https://www.cnblogs.com/ultranms/p/9327784.html、
https://www.cnblogs.com/ftl1012/p/iostat.html、http://www.bluestep.cc/linux-ifstat命令-统计网络接口流量状态
