程序猿学社的GitHub,欢迎Star
https://github.com/ITfqyd/cxyxs
本文已记录到github,形成对应专题。
文章目录
前言
通过前几章的学习,我们已经知道如何实现一个多线程。但是我们可以发现每次都是new Thread类实现一个线程。我们大家也知道创建和销毁对象是很费时间的。特别是频繁的创建和消费。在java中,因为资源释放,都是自动释放的,这也是java能快速兴起的原因一直。实际上jvm中会跟踪这个对象,确保这个对象,是不是没有引用,确保没有人使用后,才会进行销毁。这也是连接池产生的原因。
1.什么是线程池?
线程池是指在进程开始时创建一定数量(有上限)的线程,并放入池中,需要使用时,就从池中取出来一个可用线程,用完后,不是销毁,而是返回池中。如果线程用完了,就需要等待有空闲的线程后,才能使用。
- java在JDK1.5后就引入了线程池。所以不需要我们自己实现一个线程池。
举例说明:
- 没有使用线程池的时候,假设我们要看一本书“java编程思想”,是直接到网上买一本书,买来后,看完就丢弃(销毁)。
- 使用多线程,这次我们不是直接到网上买一本书,都是通过到图书馆,借"java编程思想这本书",我看完后,归回到图书馆,这时候其他的人,还可以继续重复阅读(线程的重复利用)。

2.实战
2.1通过线程池代码创建线程
public void two() throws Exception{
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int count=0;
for (int i = 0; i < 5; i++) {
Thread.sleep(1200);
count++;
}
return count;
}
};
ExecutorService e= Executors.newFixedThreadPool(10);
Future<Integer> f1=e.submit(callable);
Integer result = f1.get();
System.out.println("获取多线程的值:"+result);
}
通过上述代码,我们可以知道实现线程池涉及到ExecutorService和Executors。下面我们来一个个进行源码分析
2.1.Executors源码分析
在idea中,把光标放到Executors上,按住鼠标左键+ctrl进入Executors类。输入alt+7查看该类下的所有方法。

- newFixedThreadPool(int nThreads) 创建一个重用固定数量线程的线程池,如果在所有线程都处于活动状态时提交了额外的任务,他们将在队列中等待,直到线程可用为止。
- newWorkStealingPool(int parallelism) jdk1.8后引入的,它是新的线程池类ForkJoinPool的扩展,能够合理的使用CPU,进行并发运行任务。可以了解为,工作量一样,A,B同时开发,谁开发的快,谁就多做一些,能者多劳(不提倡工作中这样,只是为了通过实例更好的理解这个概念)。
- newSingleThreadExecutor() 创建一个单例的线程池,也就是说池中就一个线程。通过这个线程来处理所有的任务,如果发现这个这个线程因为失败而关闭,不要慌,会有一个线程来取代他,保证任务能正常的运转
- newCachedThreadPool() 创建一个可缓存线程池,如果没有线程可用,发现60s内有线程不工作,会创建一个线程的线程来取代他,再放入池中。 可以理解为一个公司为了保证公司的正常运转,会请20个人,但是,上班期间发现隔壁小王在偷懒,那不好意思,针对这种偷懒的人,公司表示不欢迎,直接开除,重新招一个人,保证公司的人员固定能正常运营。
- newSingleThreadScheduledExecutor() 创建一个单线程的线程池,此线程池的的线程可以定时周期性的运行任务。注意坑点:使用这种方法,如果出现异常,会导致无法正常的运行任务。所以,个人建议,使用这种方式的时候,run方法里面的代码可以加上异常处理逻辑。
- newScheduledThreadPool(int corePoolSize) 创建一个固定大小的线程池。此线程池支持定时以及周期性执行任务的需求。
newFixedThreadPool
创建一个重用固定数量线程的线程池,如果在所有线程都处于活动状态时提交了额外的任务,他们将在队列中等待,直到线程可用为止。
package com.cxyxs.thread.four;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Description:转发请注明来源 程序猿学社 - https://ithub.blog.csdn.net/
* Author: 程序猿学社
* Date: 2020/2/20 11:12
* Modified By:
*/
public class NewFixedThreadPool {
public static void main(String[] args) {
//System.out.println(Runtime.getRuntime().availableProcessors());
Runnable run = new Runnable() {
@Override
public void run() {
try {
System.out.println("程序猿学社:"+new Date());
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
ExecutorService executorService = Executors.newFixedThreadPool(2);
for (int i = 0; i < 10; i++) {
executorService.execute(run);
}
}
}
为了更好的看出效果,我特意把每个任务都延迟了3秒钟,模拟真实的场景,各位社友,觉得他的输出结果应该是怎么样的?
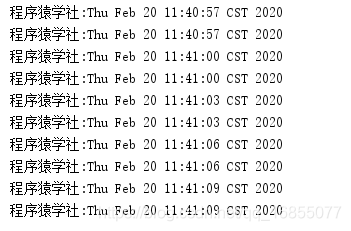
通过控制台,我们可以发现,每次只处理两个任务,而其他的任务处在排队状态,依次处理。
为什么只处理两个任务?有没有社友想到为什么?
这是因为社长设置了线程池中的数据大小为2。讲到这里有引发一个疑问。
线程池里面的数据量可以随便设置吗?
不能随便设置,不同的开发人员设置的标准不一样,个人是CPU核数的2倍。
- 例如,你单个cpu,同一时间只有一个通道,可以运行任务。就算你设置100个线程,实际上也是交替运行的。
- 不要社长这样说,就觉得CPU是单核,就觉得多线程没有一点用,实际上,在网络通讯过程中,解析包,处理包,就是通过多线程,把解析和处理的逻辑切割开来。实现解耦。这样有一个好处,就算你处理业务逻辑的线程很慢,也不会影响我解析包的线程正常运转。
newWorkStealingPool(int parallelism)
jdk1.8后引入的,它是新的线程池类ForkJoinPool的扩展,能够合理的使用CPU,进行并发运行任务。
package com.cxyxs.thread.four;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Description:转发请注明来源 程序猿学社 - https://ithub.blog.csdn.net/
* Author: 程序猿学社
* Date: 2020/2/20 14:15
* Modified By:
*/
public class WorkStealingPool {
public static void main(String[] args) throws Exception{
//再测试之前,我们应该了解我们电脑的cpu核数,我的电脑是4核
System.out.println(Runtime.getRuntime().availableProcessors());
ExecutorService executorService = Executors.newWorkStealingPool();
for (int i = 0; i < 10; i++) {
//产生一个随机数1-3
int num = (int) (Math.random() * 3 + 1);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
//模拟正在业务
Thread.sleep(num*1000);
System.out.println("线程名:"+Thread.currentThread().getName()+",业务时长:"+num+"秒");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
executorService.execute(runnable);
}
//因为是守护进程,如果不加这句话是无法看到结果的
System.in.read();
}
}
因为newWorkStealingPool是并发运行,既然人工作的效率都有高低,电脑也是一样。已经完成任务的,不可能让他闲着,这样会造成资源的浪费。

重点下面这句话要理解。打印出来的4,表示我们电脑只能并行4个线程。
Runtime.getRuntime().availableProcessors()
- 通过上面打印的线程名,我们可以发现他用的是ForkJoinPool线程池。这是jdk1.7引入的。
- 数字0-3 表示我们电脑同一时刻在工作(只是针对这块而言,这句话扩大来说是有问题的)。
- 我们可以发现work1线程跑了3次,说明执行完,自己的任务后,发现其他的小伙子还没有做完,开始继续接任何开始做事了(rabbitMQ里面有一个地方设置条数为1,跟这里的思想类似,意思就是我每次从队列里面取1条,我消费完,再继续取)。
System.in.read();
- 因为是守护进程,如果不加这句话是无法看到结果的,后文会详细说明
newSingleThreadExecutor()
创建一个单例的线程池,也就是说池中就一个线程。通过这个线程来处理所有的任务,如果发现这个这个线程因为失败而关闭,不要慌,会有一个线程来取代他,保证任务能正常的运转
package com.cxyxs.thread.four;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Description:转发请注明来源 程序猿学社 - https://ithub.blog.csdn.net/
* Author: 程序猿学社
* Date: 2020/2/20 14:48
* Modified By:
*/
public class NewSingleThreadExecutor {
public static void main(String[] args) {
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index=i;
singleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(index == 5){ //故意搞破坏
int flag =index/0;
}
System.out.println(Thread.currentThread().getName());
}
});
}
}
}
为了验证我上面那段话,我特意搞破坏,让i=5的时候,除以0,大家都知道0不能作为分母。
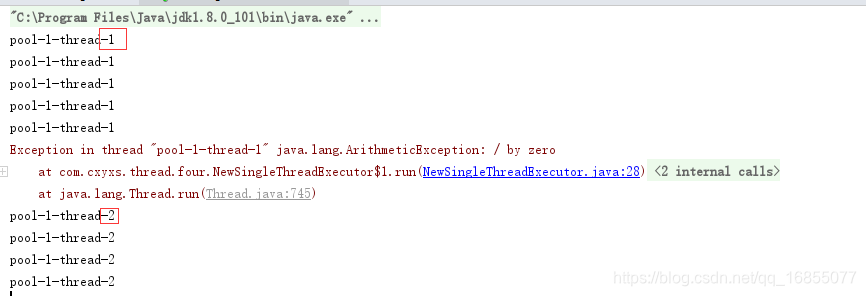
- 通过图,我们可以发现,之前的线程名一直是XXX-1,到了第五次报错后,就直接抛出异常,重新起了一个新的线程是XXX-2。
- newSingleThreadExecutor看名称就知道是单例线程池的意思。那就只有一个线程。一次只能运行一个任务,所以他也是顺序执行的。
newCachedThreadPool()
创建一个可缓存线程池,如果没有线程可用,发现60s内有线程不工作,会创建一个线程的线程来取代他,再放入池中。 可以理解为一个公司为了保证公司的正常运转,会请20个人,但是,上班期间发现隔壁小王在偷懒,那不好意思,针对这种偷懒的人,公司表示不欢迎,直接开除,重新招一个人,保证公司的人员固定能正常运营。
package com.cxyxs.thread.four;
import java.util.Date;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Description:转发请注明来源 程序猿学社 - https://ithub.blog.csdn.net/
* Author: 程序猿学社
* Date: 2020/2/20 15:02
* Modified By:
*/
public class NewCachedThreadPool {
public static void main(String[] args) throws Exception{
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
int index = i;
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
if(index == 0){
try {
Thread.sleep(8000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("第一次:"+Thread.currentThread().getName()+","+new Date());
}
});
}
Thread.sleep(7000);
for (int i = 0; i < 10; i++) {
int index = i;
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
if(index == 0){
try {
Thread.sleep(8000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("第二次:"+Thread.currentThread().getName()+","+new Date());
}
});
}
}
}

首先我这个代码看起来很乱。因为自身为了论证结论。所以没有把代码做一个简单的抽取。
代码设计:通过我的代码,可以发现,第一次循环5次,我把第一条数据设置延迟80s,我还特意在main主线程里面延迟了70s。,第二次,循环10次。为什么这样设计?
- 就是为了论证到了60秒以后,到底是不是把线程回收了。第一次第一个线程输出后,本身线程数量为9,被回收到了1。
- 线程的复用,我们可以看图,XXXX-3,出现了2次,说明就是这个线程执行完后,如果这时候有线程过来,其他的线程就可以直接复用这个线程。
newSingleThreadScheduledExecutor()
创建一个单线程的线程池,此线程池的的线程可以定时周期性的运行任务。注意坑点:使用这种方法,如果出现异常,会导致无法正常的运行任务。所以,个人建议,使用这种方式的时候,run方法里面的代码可以加上异常处理逻辑。这种方式newSingleThreadExecutor类似,只是增加了周期性运行,这里不过多的阐述。
newScheduledThreadPool(int corePoolSize)
创建一个固定大小的线程池。此线程池支持定时以及周期性执行任务的需求。
package com.cxyxs.thread.four;
import java.util.Date;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* Description:转发请注明来源 程序猿学社 - https://ithub.blog.csdn.net/
* Author: 程序猿学社
* Date: 2020/2/20 15:43
* Modified By:
*/
public class NewScheduledThreadPool {
public static void main(String[] args) {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2);
executorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("开始时间:"+Thread.currentThread().getName()+","+new Date());
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},2000,6000,TimeUnit.MILLISECONDS);
}
}
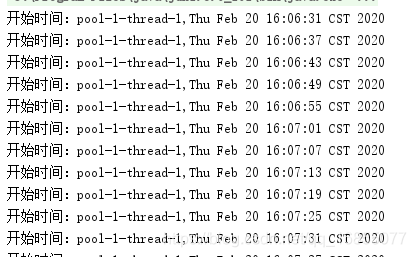
通过截图我们可以发现是6秒一次。
- 保证period>initialDelay,以period为准。以period的时长为一个周期
- 如果run方法运行时间大于period,定时任务的周期以run运行时长为一个周期。
- 详细这个方法的时候,本文就不阐述了,后续会出相关文章。
想实时查看我文章更新动态及干货,可以关注我的公众号「程序猿学社」。

