Python-深度学习-学习笔记(15):keras从多维张量中提取指定维度的方法
在处理数据集的时候,有时我们需要提取多维张量中的指定维度,例如我的预处理的数据维度为(27,8400,2048),其中27表示有27类,而我需要对这些数据进行一类一类的处理,那么我要做的是将每一类分离出来。
也就是说获得27组维度为(8400,2048)的数据。
二维分离
通常用法:
x[:,n]或者x[n,:]
x[:,n]
表示在全部数组(维)中取第n个数据,直观来说,x[:,n]就是取所有集合的第n个数据。
例如:
import numpy as np
x = np.array([[0,1],[2,3],[4,5],[6,7],[8,9]])
print(x[:,0])
-------------------------------------------------------------------------------------------------
[0 2 4 6 8]
x[:,n]相当于取矩阵的第n列。
x[n,:]
表示在n个数组(维)中取全部数据,直观来说,x[n,:]就是取第n集合的所有数据。
例如:
import numpy as np
x = np.array([[0,1],[2,3],[4,5],[6,7],[8,9]])
print(x[0,:])
-------------------------------------------------------------------------------------------------
[0 1]
x[n,:]相当于取矩阵的第n行。
x[:,m:n]
表示取所有数据集的第m到n-1列数据,取行的同理。
多维分离
假设预处理的数据维度为(27,8400,2048),其中27表示有27类,我想要分类处理的话必须要将每一类分离出来,也就是获得27组维度为(8400,2048)的数据。
那么我可以这样做:
#取第一组数据
X_data_1 = X_data[0,:,:]
Y_data_1 = Y_data[0,:]
Y_data_1_reshape = Y_data_1.reshape(8400,1)
print('X_data_1:',X_data_1.shape)
print('Y_data_1:',Y_data_1_reshape.shape)
结果为:
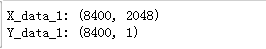
总结
当你想要分离出哪几维数据,或者也就是去掉维度中的哪个,那么就选择将数写在它的位置,这样说可能不太能理解。
用我们之前举的例子来说
- x[:,0]表示取第一列,我们的数据维度为(5,2),我们要分离出的是第2维,也就是去掉的维度是列,那么我们就选择在列上面置0,即可提取第1列。
- x[0,:]表示取第一行,我们的数据维度为(5,2),我们要分离出的是第1维,也就是去掉的维度是行,那么我们就选择在行上面置0,即可提取第1行。
- X_data[0,:,:]表示取第一类数据,我们的数据维度为(27,8400,2048),我们要分离出的是第1维,也就是去掉的维度是类,那么我们就选择在类上面置0,即可提取第1类。
取哪维就在谁上面写数,写的数就是取的第n-1个!!!!
