查找索引
步骤
- 创建一个Director对象,指定索引库的位置
- 创建一个IndexReader对象
- 创建一个IndexSearcher对象,构造方法中的参数indexReader对象。
- 创建一个Query对象,如TermQuery
- 执行查询,得到一个TopDocs对象
- 取查询结果的总记录数
- 取文档列表
- 打印文档中的内容
- 关闭IndexReader对象
public void searchIndex() throws Exception {
/**
* 1、创建一个Director对象,指定索引库的位置
*/
Directory directory = FSDirectory.open(new File("C:\\temp\\index").toPath());
/**
* 2、创建一个IndexReader对象
*/
IndexReader indexReader = DirectoryReader.open(directory);
/**
* 3、创建一个IndexSearcher对象,构造方法中的参数indexReader对象。
*/
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
/**
* 创建一个Query对象,TermQuery
*/
Query query = new TermQuery(new Term("name", "spring"));
/**
* 5、执行查询,得到一个TopDocs对象
* 参数1:查询对象 参数2:查询结果返回的最大记录数
*/
TopDocs topDocs = indexSearcher.search(query, 10);
/**
* 6、取查询结果的总记录数
*/
System.out.println("查询总记录数:" + topDocs.totalHits);
/**
* 7、取文档列表
*/
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
/**
* 8、打印文档中的内容
*/
for (ScoreDoc doc :scoreDocs) {
//获取得分(相关度)
System.out.println("相关度:" + scoreDocs.score);
//取文档id
int docId = doc.doc;
//根据id取文档对象
Document document = indexSearcher.doc(docId);
System.out.println(document.get("name"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
//System.out.println(document.get("content"));
System.out.println("-----------------寂寞的分割线");
}
//9、关闭IndexReader对象
indexReader.close();
}
Query的子类
-
TermQuery
- Query子类,Lucene支持的最基本的一个查询类,不会进行分词
- 例子:
Query query = new TermQuery(new Term("filename", "lucene"));
-
RangeQuery
- 对LongPoint进行范围查询
- 例子:
Query query = LongPoint.newRangeQuery("size", 0l, 100l);
-
NumericRangeQuery
- 数字区间查询
- 例子:
Query newLongRange = NumericRangeQuery.newLongRange("fileSize",0l, 100l, true, true);
-
PrefixQuery
- 前缀查询,查询分词中含有指定字符开头的内容
- 例子:
PrefixQuery query = new PrefixQuery(new Term("fileName","hell"));
-
FuzzyQuery
- 模糊查询
- 例子:
FuzzyQuery query = new FuzzyQuery(new Term("fileName","lucene"));
-
WildcardQuery
- 通配符查询
- * :任意字符(0或多个)
- ? : 一个字符
- 例子:
WildcardQuery query = new WildcardQuery(new Term("fileName","*"));
- 通配符查询
-
RegexQuery
- 正则表达式查询
- 例子:
RegexQuery query = new RegexQuery(new Term("fileName","[a-z]{1,6}"));
-
BooleanQuery
- 布尔查询,是一个组合Query(多个查询条件的组合)
- 连接条件
- Occur.MUST
- Occur.SHOULD
- Occur.FILTER
- Occur.MUST_NOT
- 例子
TermQuery termQuery1 = new TermQuery(new Term("fileName", "lucene")); TermQuery termQuery2 = new TermQuery(new Term("fileName", "name")); BooleanQuery query1 = new BooleanQuery(); BooleanQuery query2 = new BooleanQuery(); query1.add(termQuery1, Occur.SHOULD); query2.add(termQuery2, Occur.SHOULD); //组合多个query query1.add(query2, Occur.SHOULD);
QueryParser
使用QueryPaser进行查询,可以对要查询的内容先分词,然后基于分词的结果进行查询。
public void testQueryParser() throws Exception {
//创建一个QueryPaser对象,两个参数
QueryParser queryParser = new QueryParser("name", new IKAnalyzer());
//参数1:默认搜索域,参数2:分析器对象
//使用QueryPaser对象创建一个Query对象
Query query = queryParser.parse("lucene是一个Java开发的全文检索工具包");
//TODO 执行查询
}
- MultiFieldQueryParser
- 查询多个field
- 例子
String[] fields = {"fileName","fileContent"}; MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new StandardAnalyzer()); Query query = queryParser.parse("fileName:lucene AND filePath:a");
可视化Luke
Luke 是用于查询 Lucene / Solr / Elasticsearch 索引的可视化工具
链接:https://pan.baidu.com/s/110VLjtuTSjNFUGiKDW9yTg
提取码:wnc3
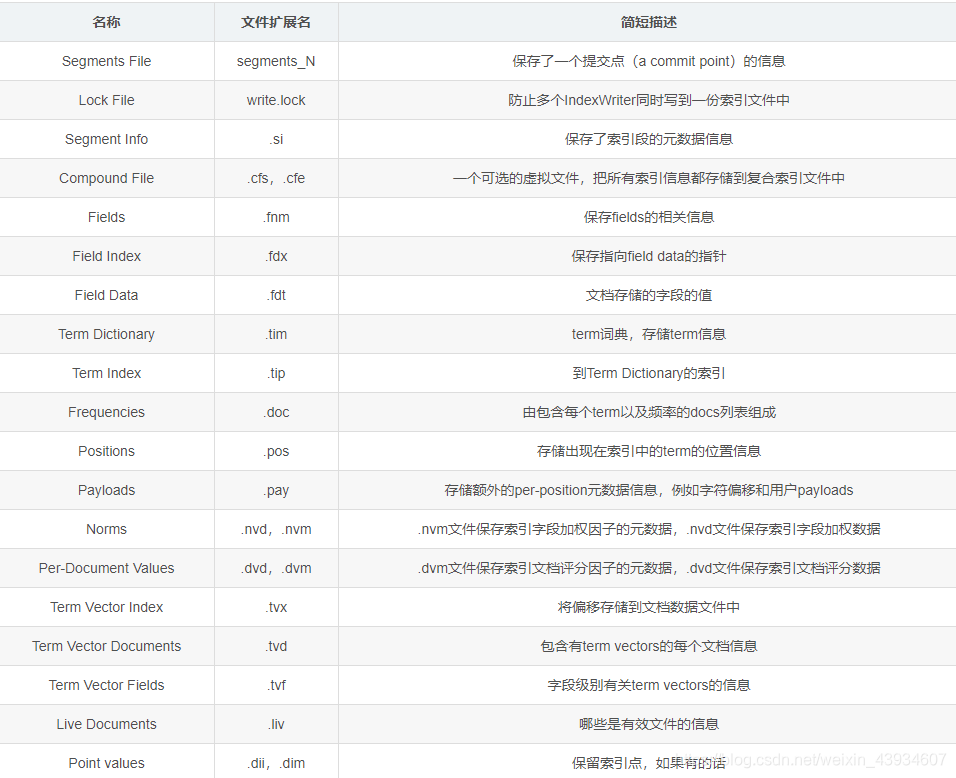
- index库生成的文件

拓展名说明
- Luke使用(7.40要求JDK9)
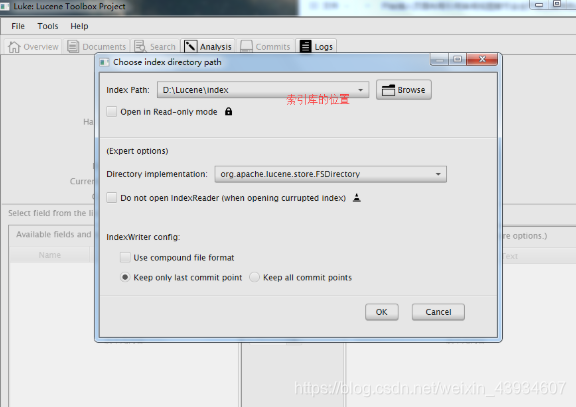
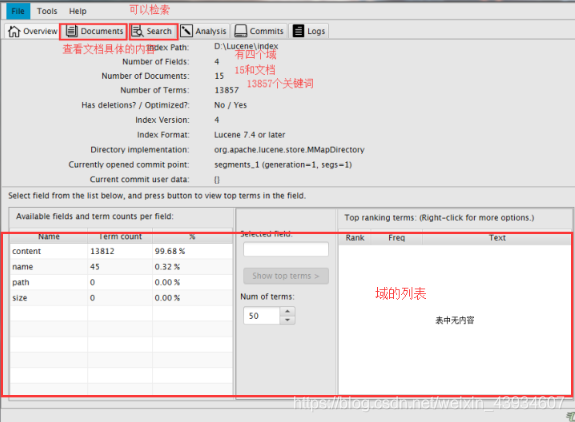
- Luke使用(7.40要求JDK9)
