flex&bison简介
flex是GNU开发的一个实用工具,它主要用于对语言进行词法分析。使用flex,我们不需要使用像C/C++,Java这样的语言从设计状态机开始编写词法分析器,而只需要按照flex自己的语法编写分词规则文件,然后使用flex编译该文件,flex会根据规则文件生成C/C++源文件,这个源文件中包含了状态机的代码,简化了编写词法分析器的工作。flex的前身是lex,它们的出现都是为了简化词法分析器的编写,其语法也是非常类似,但lex是由Mike Lesk 和 Eric Schmidt开发的,并不遵循GNU的FDL协议。
bison与flex类似,也是GNU开发的一个实用工具,但它主要是用于语法分析,它的输入一般是flex的输出。bison的前身是yacc,使用flex&bison可以很方便的进行词法分析以及语法分析。
flex简单教程
我们首先安装flex,flex的安装非常容易,从flex的官网http://flex.sourceforge.net/下载最新版本的flex,然后使用tar工具进行解压,cd到解压出来的flex目录,然后在命令行运行./configure&&make&&make install即可,注意最好以root用户运行以上命令,否则有可能会因为权限问题而安装失败,如图所示

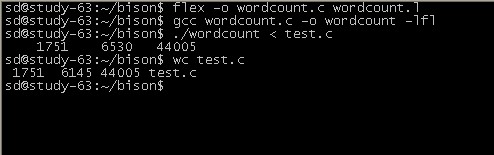
flex文件一般都是以.l作为文件名的后缀,且如果以.l作为文件后缀,vim就认为该文件为一个flex文件,而根据flex的语法对该文件进行高亮显示。下面我们来写第一个flex文件,新建一个文件名为wordcount.l,该文件内容如下图所示,源文件见附录一(注:内容来自<<flex&bison>>一书)。wordcount.l完成与wc类似的功能,它统计某个文件的行数,单词个数,以及字符数。

使用flex和gcc编译并运行该程序,如下图。编写flex程序的一般流程是这样的,首先书写flex文件,然后使用flex编译flex文件,生成对应的.c文件,最后使用gcc编译该.c文件,生成可执行程序。从图1-3我们也可以看到,我们自己写的单词统计的程序得到的结果与系统提供的wc程序的结果基本相同。
下面我们来详细分析wordcount.l这个文件。对于每一个flex文件,它一般分为3个部分,从上到下依次是Definition Section、Rules Section、和User Subroutines,以%%作为分隔符。
Definition Section可以包括选项,文字块,定义,开始条件,翻译。用%{和%}包围起来就是文字块,我们的程序较为简单,只包含了文字块,因此我主要对文字块进行说明,关于其他部分的信息请查看manual。文字块主要含有程序所需的头文件和变量的定义,如果程序中用到其他头文件,可以在这个块使用include包含进来。此外,对于我们的wordcoutn.l文件,在这个块定义了chars,words,lines这个3个变量,分别用于记录字节数,单词数,和行数。注意,在这个Section定义的变量都是全局变量,只要没有使用static修饰,对于整个程序都是可见的,包括其他文件。
Rules Section包含了模式行和C代码,模式行是最重要的,因此我主要分析模式行。每个模式行由2个部分组成,模式和动作,模式是一个正则表达式,动作是被{和}包围起来的C语言代码。当flex对输入进行匹配时,它会自上而下地依次对每个模式行进行匹配,如果存在一个匹配的模式行,则调用该模式行中相应的动作,如果不存在,则执行默认动作,把匹配到的字符回显到标准输出。当flex执行完模式行的动作后,它又会从第一个模式行往下开始匹配,一直到输入结束。
User Subroutines包含了用户子例程,通俗地说,就是用户定义函数,如main函数等,这里的代码会被原封不动地拷贝到生成的C文件。
yylex函数是词法分析器的入口,就像main函数是我们一般程序的入口一样,只有调用了yylex函数之后,词法分析器才开始工作。我们的wordcount程序只进行词法分析,因此我们在main函数里面直接调用yylex()。
bison简单教程
bison的安装与flex类似,从bison的官网http://www.gnu.org/software/bison/下载相关文件,安装方法和flex一样,都是Tarball安装。
bison文件使用BNF规则描述语法,例如,假设我们要设计一个计算器的语法,该计算器只有加和乘两种运算,以BNF的格式,语法可以如下:
<exp> ::= <factor>
| <exp> + <factor>
<factor> ::= NUMBER
| <factor> * NUMBER
这个语法规则可以识别1+2*3+4、1+4、2*3等这样简单的表达式,这些表达式必须是仅仅由加号和乘号以及数字构成。这个例子只是为了说明BNF语法的规则,在BNF语法中,::=表示“是由什么构成”。在BNF语法中,每一行就是一个规则,第一行说明exp是由factor构成,其余行依此类推。|表示“或”的意思,第一行和第二行表明exp可以是由factor或者exp + factor构成。
下面我们来说bison,bison属于一个语法分析器的编写工具,bison编写出来的只是语法分析器,而这个语法分析器的输入必须是词法分析得到的结果,也就是token流。什么是token流?所谓的token流与单词流类似,只不过是由一个个token而不是单词组成,以1+2*3+4这个表达式为例,其经过词法分析后得到的token流应该是1,+,2,*,3,+,4。在BNF表示的语法中,::=两边所有的符号都被称作token。BNF把token分为非终止符和终止符,非终止符即是在::=的左边出现过的token,如exp,其余的为终止符,如NUMBER、*。经过词法分析得到的token流中只包含终止符,而语法分析器也只需要终止符,非终止符是由语法分析器规约而得到的。
下面以一个简单的计算器为例,注意,这个计算器的语法与上述的例子稍微有些不同,它增加了乘法、除法和求绝对值运算。其bison的源文件caculator.y如下:
| %{ #include <stdio.h> %} %token NUMBER %token ADD SUB MUL DIV ABS %token EOL %% calclist: | calclist exp EOL {printf("= %d\n", $2);} ; exp: factor | exp ADD factor {$$ = $1 + $3;} | exp SUB factor {$$ = $1 - $3;} ; factor: term | factor MUL term {$$ = $1 * $3;} | factor DIV term {$$ = $1 / $3;} ; term: NUMBER | ABS term {$$ = $2 >= 0? $2 : -$2;} ; %% void yyerror ( const char *msg ) { fprintf(stderr, "%s\n", msg); return; } int main ( ) { yyparse(); return 0; } |
下面我们来详细分析一下caculator.y这个源文件。bison的文件结构与flex的类似,也是用%%分为三个部分,从上至下依次是Definition Section、Rules Section、和User Subroutines。
在Definition Section中最主要包括了终止符的声明,如NUMBER,ADD等,这些终止符将会被flex使用。
在Rule Section中bison文件里不再是包含模式匹配行,它包含的是以BNF规范描述的语法规则以及动作。用大括号括起来的那部分是相应的动作,里面由C代码构成,一旦bison使用这条规则进行规约,就会执行大括号里面的动作。在bison文件中,每一个token都有一个相应的值属性,每个token都可以当作一个变量,如果没有显示声明值属性,那么bison会使用int属性。在规则对应的动作中,可以使用$$引用规则左边的token,使用$1,$2,$3依次引用右边的第1,2,3个token,依此类推。在进行规约时,bison会自动将token的值保存起来。这里需要注意的一点是,如果某个规则右边的没有相应的动作,bison默认的动作是将$1的值赋给$$。
User Subroutines这个部分与flex文件中对应部分内容相同,参见上文。
只有语法分析程序显然不能够完成我们的计算器,每个bison文件都需要一个词法分析的结果作为输入,一般使用flex来编写词法分析器。下面就是我们这个计算器的flex源文件caculator.l:
| %{ #include <stdio.h> #include <string.h> #include "parse.h" %} %% "+" {return ADD;} "-" {return SUB;} "*" {return MUL;} "/" {return DIV;} "|" {return ABS;} [0-9]+ {yylval = atoi(yytext); return NUMBER;} \n {return EOL;} [ \t] {} . {} %% int yywrap ( ) { return 1; } |
这个文件与前面的例子类似,值得注意的一点是,parse.h是由bison编译caculator.y时自动生成的,而ADD,SUB等这些符号既是我们在caculator.y中定义的终止符。对于flex来说,它需要在识别出token时,返回token对应的符号,因为语法分析器需要这些符号。除此之外,如果token有相应的值属性,flex需要给token赋值,而这是通过yylval来实现的。yylval是连接flex和bison的一个桥梁,在这里的yylval就相当于bison中的token,因此在这里给yylval赋值,也就是给bison中的相应的token赋值。最后,我们编译源文件并运行执行程序,如下图所示,计算器成功完成。

系统需求及设计
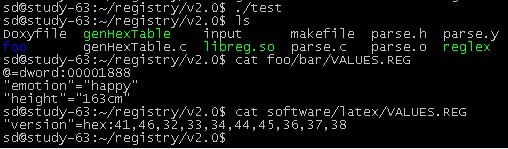
本系统不需要对完整的注册表进行解析,不需要对键进行解析,只需要对<value,name>对进行解析,如test.reg中包含以下内容:
@=dword:0f1e2b3c
"foo"=hex:00,de,ca,de,12,34
"foopath"="c:\\windows\\system"
则系统应该能正确地将这个文件解析出来,最后得到<value,name>对,其中name的类型只可能为dword,hex或者string。系统的最终目标是生成一个动态链接库,这个动态链接库提供一个regSetValue函数,该函数的原型如下:
int
regSetValue
(
const char *key,
const char *value,
enum VNameID id,
const unsigned char *data,
int len
)
用户可通过regSetValue函数操作注册表文件(注:这里不是指的标准注册表文件,而是格式与test.reg类似的文件),进行如下两个操作,即在文件中增加一个<value,name>对,或者修改已经存在的value的name的值。
为了便于测试,注册表信息根据key组织成一个目录结构。简单地说,就是如果在、注册表中存在一个key为foo/bar,则当前目录下便会有个foo/bar的目录用来表示该key,并且在foo/bar这个目录下,存在一个文件VALUES.REG,该文件存有这个key的<value,name>对信息(以test.reg的格式)。修改key为foo/bar的<value,name>对可以手工更改该key所对应目录的VALUES.REG文件,也可以使用本系统提供的动态库中的regSetValue函数。
测试
生成动态库
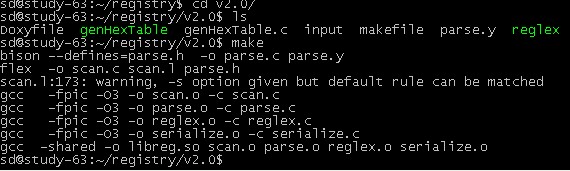
修改LD_LIBRARY_PATH环境变量并编译测试程序
![]()
程序运行结果
使用valgrind检测内存泄漏

