- 业务背景:由于公司的用户表中保存接近1亿行数据(单表),担心可能很快会单库的性能瓶颈,现在准备做水平分表,下面先做个简单的demo进行测试。
- 分片方案设计:用户表主要以userid(long)为逻辑主键进行查询,因此准备以userid取模分为32张分表,分别存放于4个分库
本示例项目基于springboot
一、引入依赖
<!-- sharding-jdbc相关依赖 -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>3.1.0</version>
</dependency>
<!-- 数据库操作相关依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
<scope>runtime</scope>
</dependency>
二、分片规则配置
配置完整示例(使用application.yml):
sharding:
jdbc:
datasource:
names: ds0,ds1,ds2,ds3
ds0:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/sharding0?useUnicode=true&characterEncoding=utf8
username: root
password: rootpass
ds1:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/sharding1?useUnicode=true&characterEncoding=utf8
username: root
password: rootpass
ds2:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/sharding2?useUnicode=true&characterEncoding=utf8
username: root
password: rootpass
ds3:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/sharding3?useUnicode=true&characterEncoding=utf8
username: root
password: rootpass
config:
props:
sql:
show: true
sharding:
tables:
user:
actual-data-nodes: ds0.user_${0..7},ds1.user_${8..15},ds2.user_${16..23},ds3.user_${24..31}
database-strategy:
standard:
sharding-column: userid
precise-algorithm-class-name: top.kylewang.sharding.sharding.ShardingDatabaseAlgorithmConfig
table-strategy:
standard:
sharding-column: userid
precise-algorithm-class-name: top.kylewang.sharding.sharding.ShardingTableAlgorithmConfig
配置说明:
sharding.jdbc.datasource:配置物理数据源- 在
names内配置所有物理数据源的名称列表,然后下面分别配置各数据源 - 上述示例中配置了
ds0、ds1、ds2、ds3四个物理数据源,且使用druid连接池(sharding-jdbc内置支持)
- 在
sharding.jdbc.config.props:配置sharding-jdbc的辅助属性配置- 上述示例使用
sql.show=true配置在使用分片数据源时打印sql,可看到最终实际路由的库和表
- 上述示例使用
sharding.jdbc.config.sharding:数据分片规则配置(重要)tables下可配置多个逻辑表,示例中配置了一个逻辑表:user,往下是其分片配置actual-data-nodes:各数据源和分表的对应关系- 示例中表user_0 ~ user_7位于ds0数据源中,表user_8 ~ user_15位于ds1数据源中,其余类推。
database-strategy和table-strategy:分别配置通过sharding-column(分片键)路由到具体数据源和表的算法standard表示单分片键的标准分片场景,即只通过一个字段路由- 示例中选取的分片键为userid,分库规则通过ShardingDatabaseAlgorithmConfig.class实现,分库规则通过ShardingTableAlgorithmConfig.class实现(见下文详细说明)
三、分片规则算法
分片算法类需要实现特定接口:
| 接口类 | 说明(sql操作支持) |
|---|---|
| PreciseShardingAlgorithm | 精确分片算法,用于=和IN |
| RangeShardingAlgorithm | 范围分片算法,用于BETWEEN |
本实例中实现PreciseShardingAlgorithm接口,重写doSharding() 方法,此方法中第一个参数为可用的数据源名或表名,第二个参数(shardingValue)为查询时传入的分片键的值。当执行"select * from user where userid = xxx" 或"in"操作时,会进入此方法,对userid(shardingValue)进行计算,获取到实际访问的数据源或表名并返回,然后再请求实际存储的库和表进行操作。
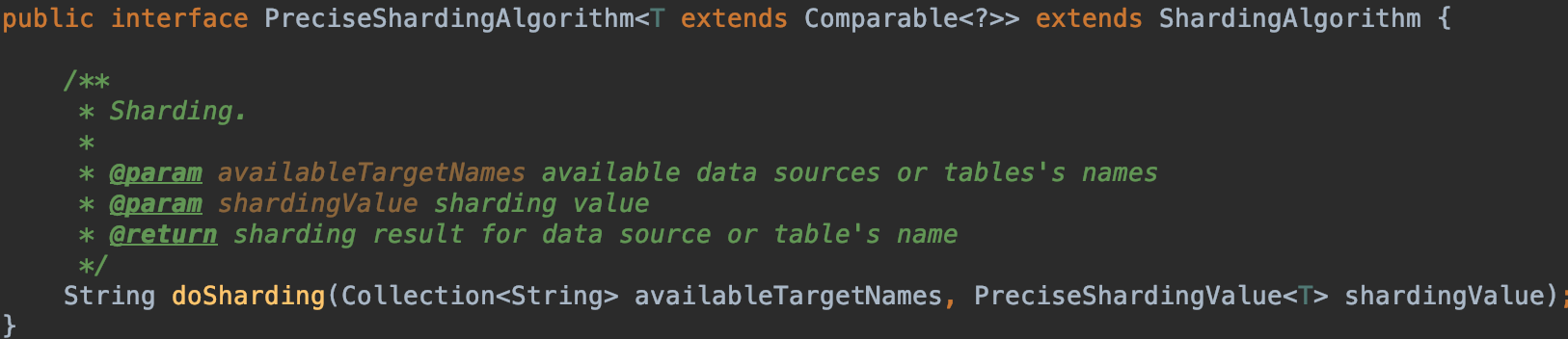
示例:
1.分库算法实现
package top.kylewang.sharding.sharding;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
/**
* @author KyleWang
* @version 1.0
* @date 2019年03月18日
*/
public class ShardingDatabaseAlgorithmConfig implements PreciseShardingAlgorithm<Integer> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) {
for (String availableTargetName : availableTargetNames) {
Integer userid = shardingValue.getValue();
int suffix = (userid % 32) / 8;
String dataSourceName = "ds" + suffix;
if (availableTargetName.equalsIgnoreCase(dataSourceName)) {
return availableTargetName;
}
}
return null;
}
}
说明:传入分片键userid的值,首先对userid取模32,再整除8,获取到数据源的后缀序号,再拼接"ds"得到真实数据源名,例如userid=10000路由到数据源:ds2。
2.分表算法实现
package top.kylewang.sharding.sharding;
import io.shardingsphere.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
/**
* @author KyleWang
* @version 1.0
* @date 2019年03月05日
*/
public class ShardingTableAlgorithmConfig implements PreciseShardingAlgorithm<Integer> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) {
for (String availableTargetName : availableTargetNames) {
Integer userid = shardingValue.getValue();
int suffix = userid % 32;
String tableName = shardingValue.getLogicTableName() + "_" + suffix;
if (availableTargetName.equalsIgnoreCase(tableName)) {
return availableTargetName;
}
}
return null;
}
}
说明:传入分片键userid的值,对userid取模32,获取到分表的后缀序号,再拼接"user"得到真实表名,例如userid=10000 路由到表:user_16。
四、操作数据库
由于使用spring-boot-starter的方式进行整合,sharding-jdbc会自动管理所有分库物理数据源,并将最后分片数据源对象注册到spring,所以可以直接自动注入DataSource来使用数据源。
示例
- 通过分片数据源构建JdbcTemplate操作数据库,执行query,insert等操作:
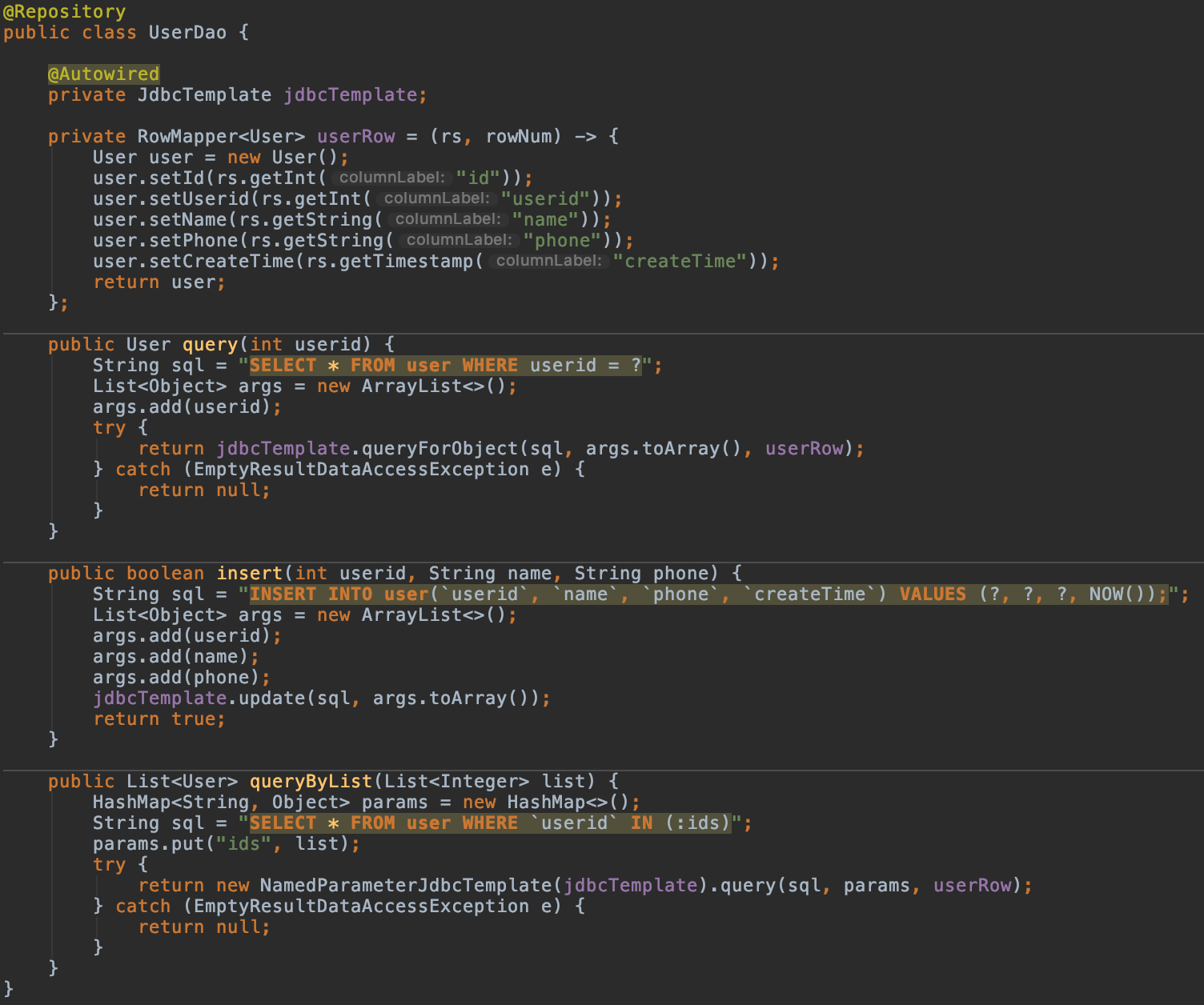
- 查询userid=10000的用户,可通过日志查看逻辑SQL语句及路由后的实际数据源和表名:

