总结
最开始,看到这个算法,感觉代码简洁,好用,就只是把这个板子记住了,但是发现这样的习惯真心不好,所以现在想理解一下
首先
空间复杂度:O(n2)
时间复杂度:O(n3)
作用:多源最短路径
注意:可以处理正负权值,但是不可以处理-负权回路(只会越减越小)-。
当时看了一下这两位大佬的博客
博客园 CSDN
这个算法,我开始有一个疑问,为什么dp[i][j]=min(dp[[i][j],dp[i][k]+dp[k][j]),这样转移一下,就是可行的?
万一当前转移的时候,dp[i][k]和dp[k][j]都不是最小的,这样转移的话,dp[i][j]就不是最小的,最终却是可行的!
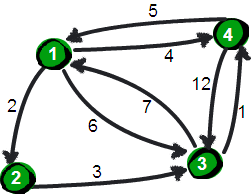
首先A:
memset(dp,inf,sizeof(dp));
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
if(i==j)
dp[i][j]=0;
邻接矩阵初始化,自环权值为0,无边权值为无穷大
然后B:
while(m--)
{
int x,y,v;
cin>>x>>y>>v;
dp[x][y]=min(dp[x][y],v);
}
把每一条边的权值更新一下,min的作用,避免一条重复多边,因为最短路径只需要最小的边权值
最后C:
for(int k=1;k<=n;k++)
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
dp[i][j]=min(dp[i][j],dp[i][k],dp[k][j]);
枚举一个图的所有两点是n^2,也就是第二层和第三层循环的作用
这里我特别提一下第一层循环
这个循环核心用了中转点
k=0,也就是没有中转点
这里就是上面==然后B:==边权值更新,两点最短路径没有任何中转点,权值就是填进去的权值
开始第一层for k循环
k=1,也就是只有1作为中转点
这里会发生什么呢?
两结点之间只有1作为中转点,上面图中更新最小边权值或者添加边

如果dp[2][4]边权值为无穷大,就图中添加一个边
如果dp[2][4]边权值非无穷大,就图中更新min边权值
k=1的2 3循环结束后,两结点最短路径之间,中转点要么没有,要么中转点为1
如果不考虑1结点与其他结点,在图中可以把结点1删除了看边权值更加直观
k=2,也就是以2作为中转点(但是这里中转点可能为2,也可能为1哦,也可能为-1-2-,也能没有)
这里会发生什么呢?
我们会发现在求dp[4][3]时,dp[4][2]和dp[2][3],已经是最小的了,为什么会这样?
如果这个图,结点更多,4->3之间有其他中转点更小边权值,这个是不是就不一定最小的了呢
什么情况:dp[4][2]和dp[2][3]这里的最小
只是dp[4][2]中无中转点或者只有中转点1时,是最小路径
同理dp[2][3]中无中转点或者只有中转点1时,是最小路径
k=3,也就是以3作为中转点(但是这里中转点S={3,2,1,3-2,3-1,2-1,3-2-1,空集})
这层同理了,这层进行结束,就代表上诉存在中转点情况中,多源最短路径最小
k=4
k=5
直到k=n
当k=n是,就代表所有情况中转点都考虑,所以可行的
for(int k=1;k<=n;k++)
for(int k=n;k>=1;k--)用上面跑,跟用下面的跑一样的
每跑一个结点作为中转点,就代表之前的跑的中转点可能作为中转点
dp[i][j]=min(dp[[i][j],dp[i][k]+dp[k][j])
回到最初的问题,floyd为什么可行?
就是每跑一个结点作为中转点,就代表之前的跑的中转点都可能作为最短路径的中转点,每一步都是最优的,只不过过程跑的不是全局最优,跑完后,就是最局最优了
